- The paper presents two novel open-source MoE transformer models that significantly enhance reasoning and tool use efficiency.
- It details advanced architecture features like root mean square normalization, rotary embeddings, and quantization techniques to optimize performance.
- Evaluation shows that both models achieve competitive accuracy on STEM, coding, and safety benchmarks compared to closed alternatives.
Overview of "gpt-oss-120b & gpt-oss-20b Model Card"
The paper "gpt-oss-120b & gpt-oss-20b Model Card" (2508.10925) presents two open-weight models designed to enhance reasoning and tool-use capabilities under an open-source framework. These models, gpt-oss-120b and gpt-oss-20b, extend previous architectures such as GPT-2 and GPT-3 while incorporating Mixture-of-Experts (MoE) for enhanced computational efficiency. The research details the models' architectures, training regimes, evaluation benchmarks, and safety measures. Notably, safety and flexibility are emphasized, particularly concerning the customizable nature of the models and the inherent risks once deployed openly.
Model Architecture and Training
Architecture
The gpt-oss models are built upon an autoregressive MoE transformer framework, integrating advanced architecture like root mean square normalization and rotary position embeddings for efficient context extension. The gpt-oss-120b includes 36 layers with 116.8 billion parameters, while the gpt-oss-20b has 24 layers amassing 20.9 billion parameters. This architecture leverages the MoE with experts selected dynamically, reducing the computational load required for high-dimensional tasks.
Training
The training process employs quantization techniques to condense memory usage, crucial for deploying large models in constrained environments. Post-training, the models undergo reinforcement learning phases that refine their reasoning and tool-use skills, akin to those used in OpenAI's o3 models.
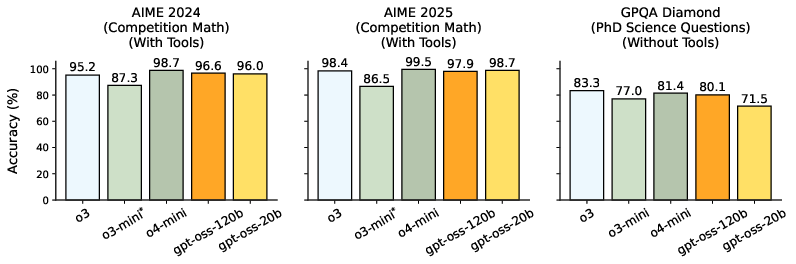
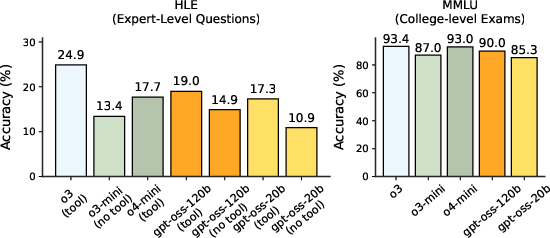
Figure 1: Main capabilities evaluations, showcasing the performance of gpt-oss models against OpenAI's o3 and others on standard benchmarks.
The models are trained on vast datasets focusing on STEM and coding, with strategic filtering applied to ensure safety, especially concerning biosecurity. This training ensures robust CoT and alignment with safety protocols.
Evaluation and Capabilities
The models' capabilities are assessed across a spectrum of benchmarks, including reasoning, coding, and health. Importantly, they demonstrate competitive accuracy across various domains, addressing complex reasoning challenges with adaptive CoT lengths. Evaluation on specific tasks reveals that gpt-oss-120b and gpt-oss-20b maintain performance levels similar to or surpassing closed models of comparable scale (Figure 2).
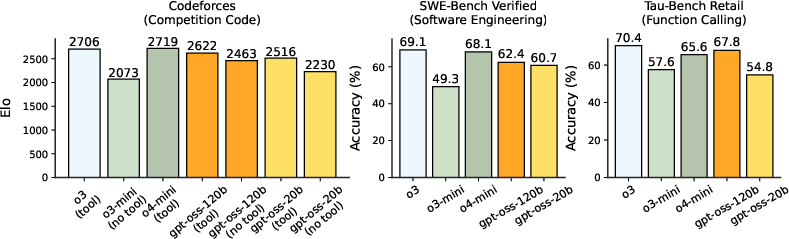
Figure 2: Coding and tool use results, illustrating gpt-oss models' performance in coding challenges compared to OpenAI benchmarks.
Safety and Ethical Considerations
The gpt-oss models incorporate multiple levels of safety testing, addressing potential misuse through adversarial and jailbreak test scenarios. This includes resilience to harmful content generation and maintaining ethical integrity through deliberate training methodologies, such as deliberative alignment and instruction hierarchy adherence. Furthermore, their safety evaluation uncovers their alignment robustness, ensuring negligible advancement of hazardous capabilities in biological domains compared to existing models.
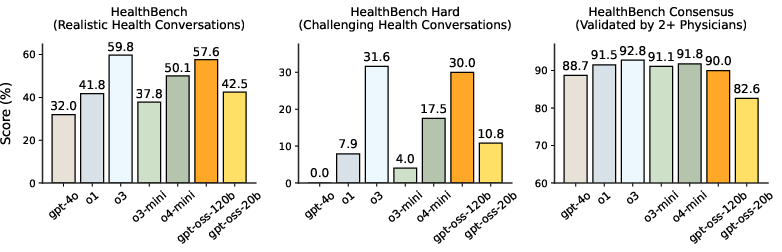
Figure 3: Health performance evaluation demonstrating gpt-oss models' effectiveness in health-related reasoning tasks.
Future Implications
The release of gpt-oss models under an open-source license poses both opportunities and challenges. Practically, these models offer a versatile solution for diverse applications requiring dynamic reasoning and tool interaction. Theoretically, they push the boundaries of open model capabilities while setting a new standard in safety and customization. The research suggests significant potential for open models to influence the global AI landscape, particularly in resource-constrained environments where proprietary models are less feasible.
In conclusion, the "gpt-oss-120b & gpt-oss-20b Model Card" represents a significant advancement in the development of open-source, large-scale LLMs. Its focus on safety, efficiency, and versatility sets an important precedent for future research and development within the AI community.
