- The paper introduces a 15B parameter model that rivals larger LLMs by balancing competitive performance with a reduced memory footprint.
- It employs a structured four-stage training pipeline including depth-upscaling, continual pre-training, and supervised fine-tuning to refine reasoning and domain adaptation.
- Reinforcement Learning with GRPO and efficient token utilization enable superior performance on enterprise benchmarks with deployment on single high-end GPUs.
Apriel-Nemotron-15B-Thinker
Introduction
The paper "Apriel-Nemotron-15B-Thinker" (2508.10948) addresses the limitations of recent LLMs, specifically focusing on the balance between performance and computational efficiency in enterprise applications. These models, though capable of complex tasks such as code generation and mathematical problem-solving, demand significant memory and computational resources, hindering their deployment in typical enterprise environments. The introduction of Apriel-Nemotron-15B-Thinker aims to fill this gap by providing a model that offers competitive performance with fewer computational demands. With a parameter count of 15 billion, this model succeeds in mirroring the performance of larger models in the 30–32B parameter range while maintaining a reduced memory footprint.
Methodology
Model Design and Upscaling
Apriel-Nemotron-15B-Thinker is designed through a structured four-stage training pipeline, starting with model upscaling. The process begins by expanding a 12 billion parameter model to 15 billion parameters through depth-upscaling, specifically by duplicating transformer layers. This approach is favored over width-upscaling due to its stability in training. The model is pre-trained with 100 billion tokens sourced from varied domains, including technical literature, code, and mathematical problems. This carefully selected dataset aids in enhancing the model's foundational capabilities.
Continual Pre-training and Supervised Fine-tuning
Continual Pre-training (CPT) follows the initial scaling, where the model is exposed to 70 billion tokens focusing on reasoning and chain-of-thought samples. This stage aims to refine the model's reasoning skills without overly relying on task-specific labels. Subsequent Supervised Fine-tuning (SFT) leverages high-quality datasets for tasks like advanced mathematics and coding, further improving the model’s capacity to generate intermediate reasoning before arriving at final solutions.
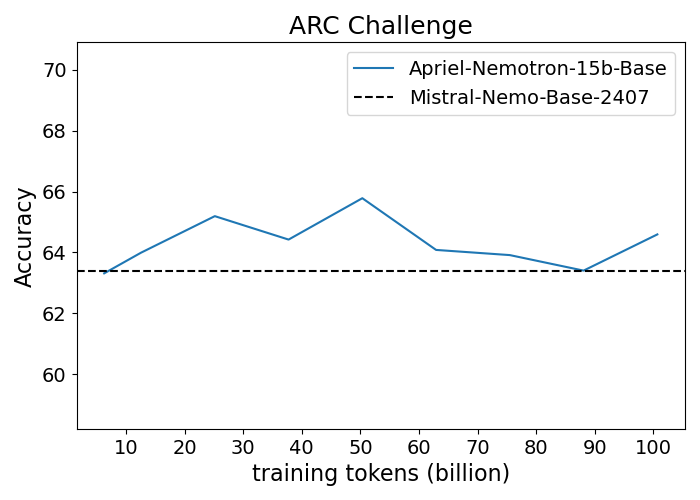
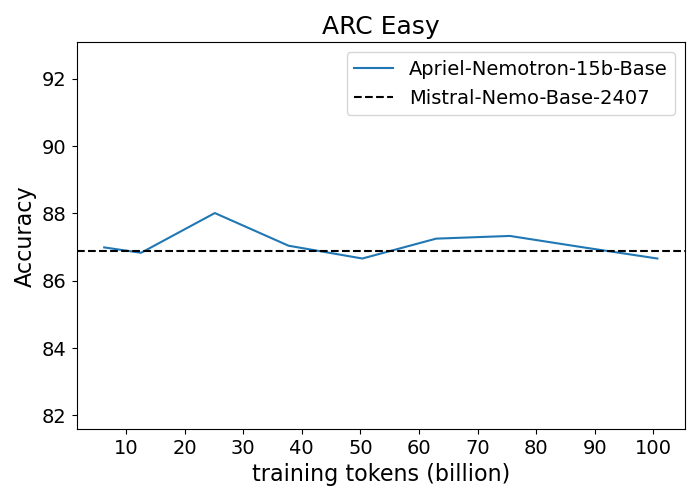
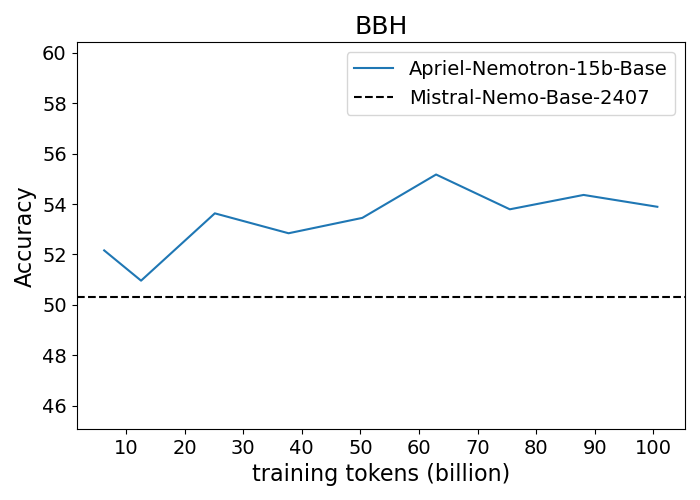
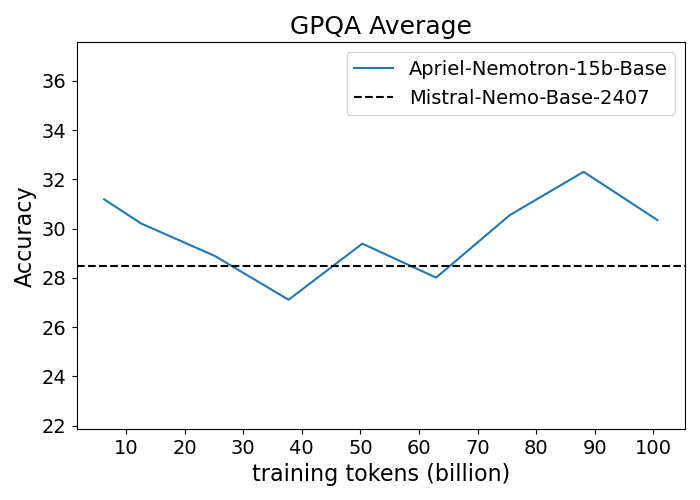
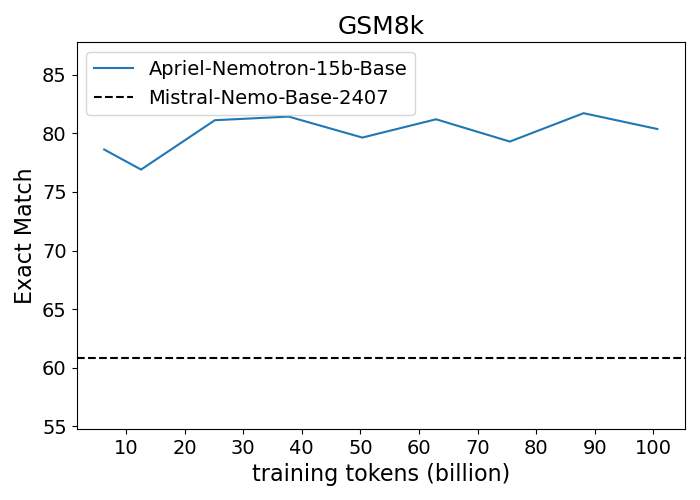
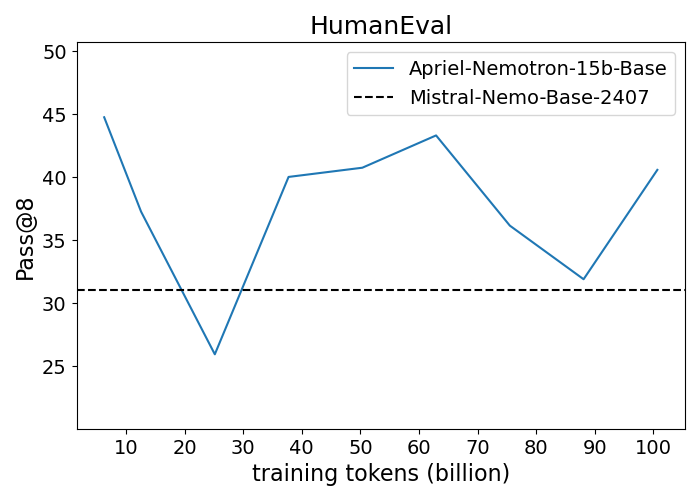
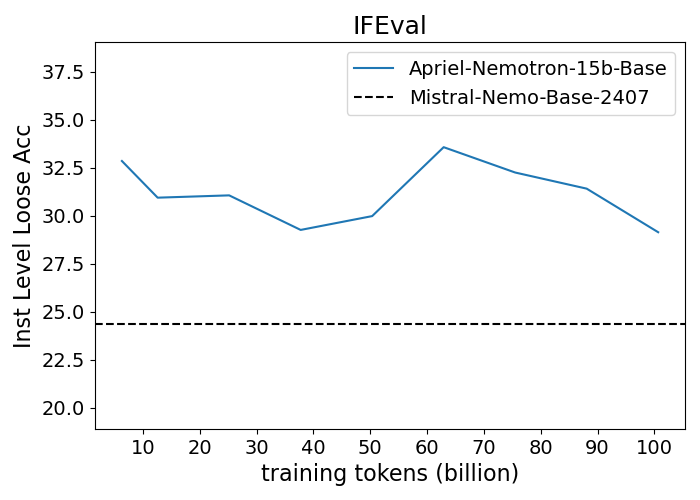
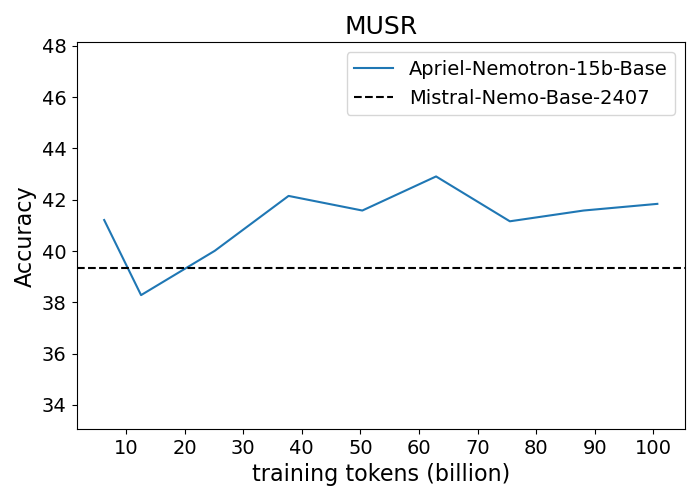
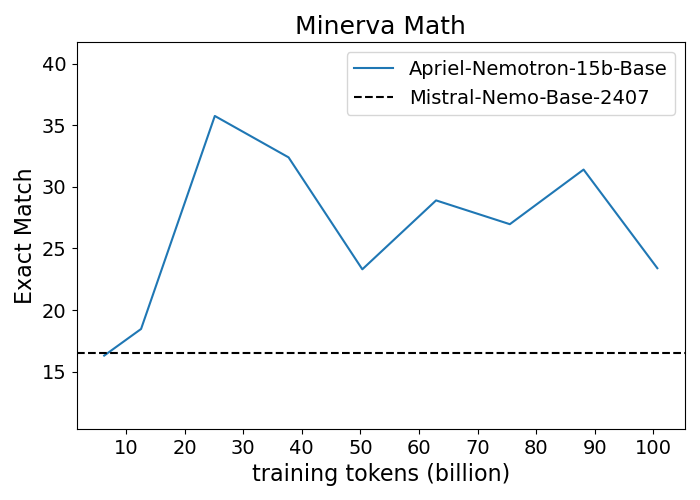
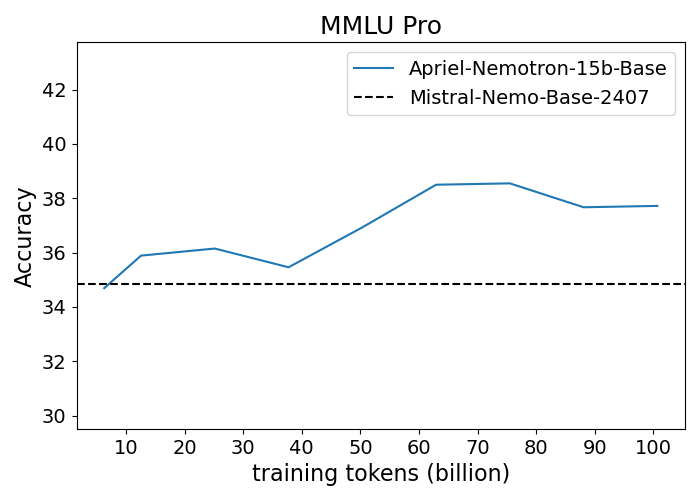
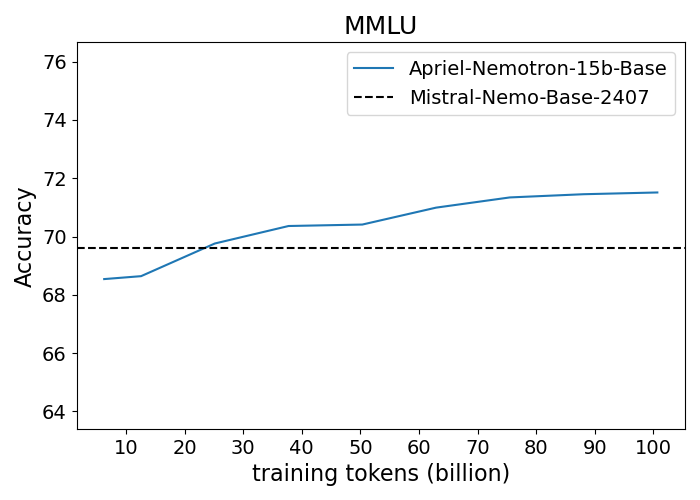
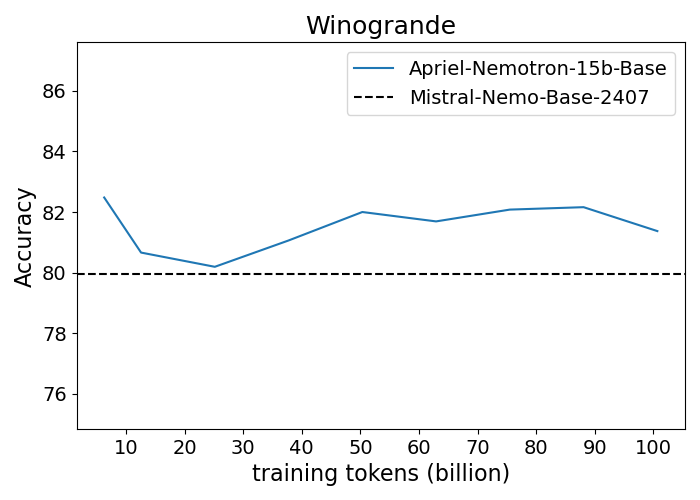
Figure 1: Performance progression of Apriel-Nemotron-15B-Base compared to Mistral-Nemo-Base-2407 across benchmarks.
Reinforcement Learning with GRPO
The final phase employs Reinforcement Learning using Group Relative Policy Optimization (GRPO) to enhance robust performance across diverse scenarios, such as output formatting and advanced coding. This stage employs a reward mechanism based on task success and structural correctness, leveraging verifiable compositional instructions and code samples to guide learning.
Results and Evaluation
Apriel-Nemotron-15B-Thinker undergoes rigorous evaluation against comprehensive benchmarks that encompass both enterprise-focused and academic scenarios. It demonstrated superior performance, even surpassing models twice its size (30–32B parameters), across a variety of tasks. Notably, its memory efficiency allows for deployment on single high-end GPUs, making it a viable option for enterprise environments.
In the context of enterprise benchmarks, Apriel-Nemotron-15B-Thinker achieved top-tier results, notably excelling in MT Bench and IFEval scores, and holding competitive positions in reasoning and domain adaptation tasks.
Token Utilization Efficiency
Analyzing token utilization across tasks reveals that Apriel-Nemotron-15B efficiently uses "thinking tokens," leveraging fewer resources while maintaining performance, especially in simpler mathematical and logical tasks. This is a testament to its optimized architecture, emphasizing efficiency and scalability.
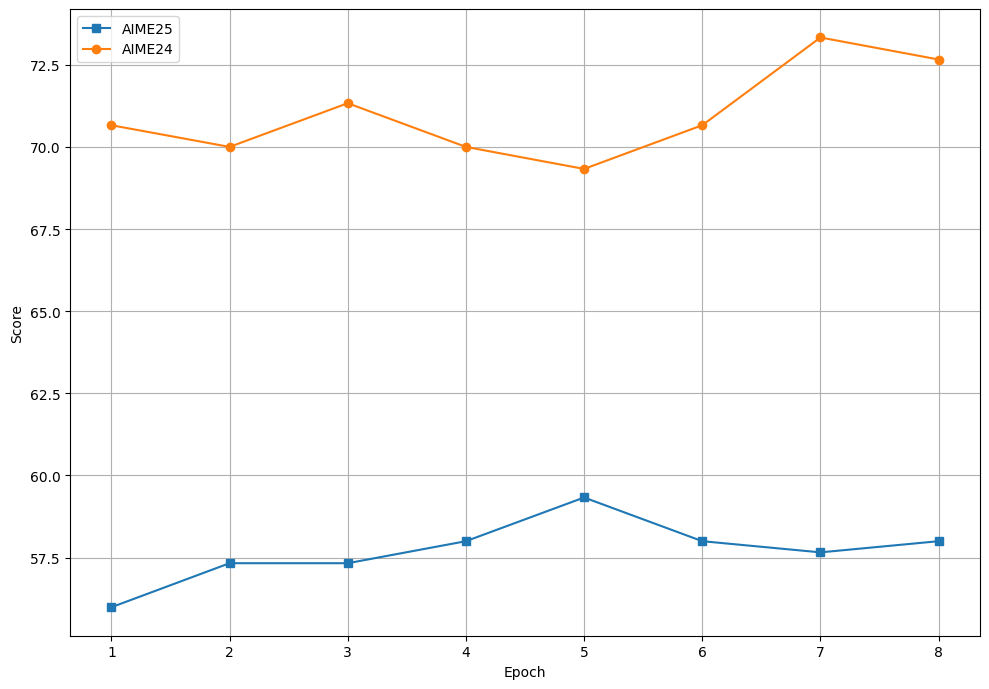
Figure 2: Variation in AIME24 and AIME24 scores over SFT epochs.
Conclusion
The Apriel-Nemotron-15B-Thinker presents a significant advancement in LLM design by successfully bridging the gap between large-scale capabilities and practical deployability in enterprise settings. Its innovative training pipeline, combined with strategic upscaling and fine-tuning, results in models that are both computationally efficient and highly effective in reasoning tasks. The model's performance across a diverse set of benchmarks underscores its potential for future application in a variety of domains requiring sophisticated natural language understanding and generation. As technology continues to evolve, enhancements in scalability and efficiency, as demonstrated by Apriel-Nemotron-15B-Thinker, are likely to play a pivotal role in broadening the scope and application of AI-driven solutions.