- The paper introduces a novel approach combining ReLU and trigonometric functions in KANs to accelerate training without sacrificing performance.
- It replaces computationally expensive polynomial activations with element-wise operations, reducing training time significantly as shown on MNIST benchmarks.
- Experimental results indicate competitive accuracy and improved efficiency over traditional B-spline and RBF functions, highlighting scalability potential.
Combinations of Fast Activation and Trigonometric Functions in Kolmogorov-Arnold Networks
Introduction
The paper introduces novel function combinations within Kolmogorov-Arnold Networks (KANs), leveraging fast activation and trigonometric functions to enhance computational efficiency. KANs, inspired by the Kolmogorov-Arnold Representation Theorem (KART), have traditionally incorporated polynomial functions like B-splines and Radial Basis Functions (RBFs). However, these functions often suffer from limited GPU support and extended training times. This work proposes integrating widely used functions such as ReLU, sine, cosine, and arctan to overcome these limitations while maintaining competitive performance.
Kolmogorov-Arnold Networks and KART
Kolmogorov-Arnold Representation Theorem (KART) asserts that any continuous multivariate function can be decomposed into a superposition of one-dimensional functions and additions. KANs embody this theorem, providing a versatile neural architecture where layers consist of function matrices instead of traditional fixed activation functions.
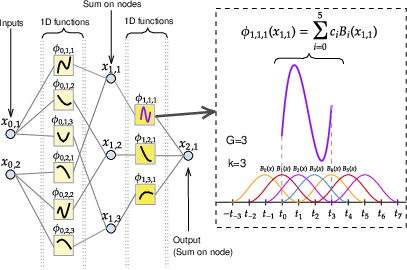
Figure 1: Left: the architecture of KAN(2,3,1). Right: A showcase of computing ϕ1,1,1 using control points and B-splines.
KAN models aim to extend the capabilities of MLPs by enhancing both width and depth through the application of functions Φq and ϕq,p, thereby capturing complex data patterns more effectively.
Methodology
The proposed approach introduces simple combinations of fast functions, focusing on activation functions like ReLU and trigonometric functions such as sine, cosine, and arctangent. These functions are chosen for their computational efficiency and are combined via element-wise operations, such as sum and product, to form FC-KAN models.
This design diverges from more complex polynomial representations, avoiding longer training times and promoting scalability. The use of these functions facilitates faster computation, as demonstrated by substantial reductions in execution time compared to B-splines and other traditional functions.
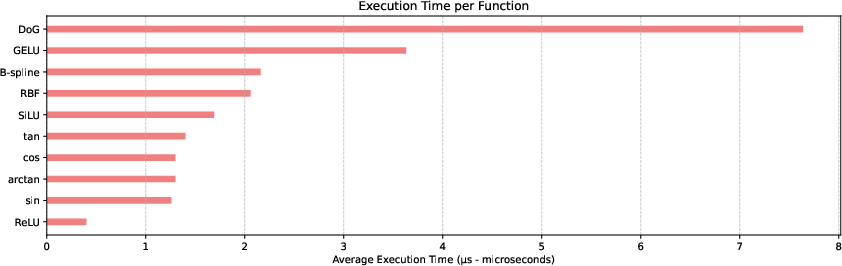
Figure 2: Average execution time (μs -- microseconds) for processing 1,000,000 inputs per function.
Experiments
The experimental evaluation comprises training FC-KAN on MNIST and Fashion-MNIST datasets, comparing performance metrics across diverse function combinations. The results highlight significant reductions in training time alongside competitive validation accuracy and F1 scores relative to B-Spline-based models and existing KAN configurations.
Implications and Future Directions
This work offers practical improvements in computational efficiency, reducing training time without sacrificing model accuracy. The findings suggest potential extensions to real-world datasets and deeper architectures. Future research could further optimize function combinations and explore additional trigonometric or non-trigonometric functions for FC-KAN, promising enhanced performance in varied domains.
Conclusion
By integrating fast functions into KAN, the paper presents a viable path toward more efficient and scalable neural networks. The approach achieves performance comparable to MLPs and existing KAN variants while operating with a similar parameter count, marking a step forward in the application of theoretical mathematical constructs in practical AI models. However, opportunities remain for further refinement and extension, particularly in addressing lingering scalability and computational constraints within fast function combinations.