- The paper introduces MMReview, a benchmark designed for LLM-based peer review automation, covering 13 tasks across 4 disciplines.
- The paper demonstrates that larger models and chain-of-thought prompting yield more structured, accurate reviews in extensive experiments.
- The paper reveals that integrating multimodal data significantly enhances model robustness against prompt injection and improves evaluative performance.
MMReview: A Comprehensive Benchmark for Peer Review Automation
The paper "MMReview: A Multidisciplinary and Multimodal Benchmark for LLM-Based Peer Review Automation" (2508.14146) addresses the limitations of existing LLM-based review systems in the peer review process, particularly their inadequacy in handling multimodal content effectively. To fill this gap, MMReview is introduced as a benchmark designed to evaluate LLMs and Multimodal LLMs (MLLMs) across diversified tasks and scientific disciplines. MMReview aims to establish a standardized evaluation framework that can comprehensively assess model capabilities in generating detailed reviews that align with human standards.
Benchmark Design and Methodology
MMReview comprises an elaborate construction pipeline divided into three main stages: data collection, processing, and task construction.
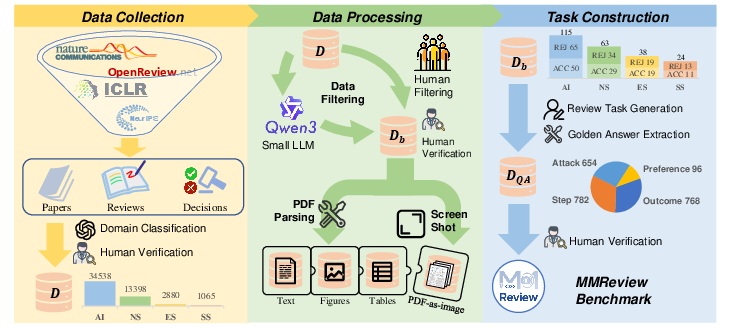
Figure 1: The construction pipeline of MMReview. The construction pipeline is divided into three stages: data collection, data processing, and task construction.
Data Collection and Processing
The benchmark is built on an extensive collection of 51,881 papers sourced from open review platforms, focusing on four major disciplines: Artificial Intelligence, Natural Sciences, Engineering Sciences, and Social Sciences. The data is curated to ensure balanced representation across accepted and rejected papers. The papers undergo a multistage processing pipeline that includes filtering for quality and ensuring a balanced distribution. This exhaustive process results in a curated set of 240 samples representing 17 research domains.
Task Construction
MMReview incorporates 13 diverse tasks grouped into four thematic categories: step-based, outcome-based, preference-based, and attack-based tasks. These tasks aim to evaluate various aspects of peer review, such as the generation of review content, alignment with human preference, and robustness to adversarial inputs. Each task is designed to emulate specific aspects of the peer review process, enabling detailed assessment of model capabilities in summarization, strengths and weaknesses evaluation, scoring, decision-making, and preference ranking.
Experimental Evaluation
The experiments involve extensive evaluations of 18 open-source models and 3 closed-source models, assessing their performance across various tasks under different input modalities, including text-only, multimodal, and PDF-as-image inputs.
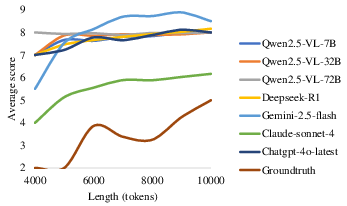
Figure 2: The average scores under text-only input setting, with context length measured in tokens.
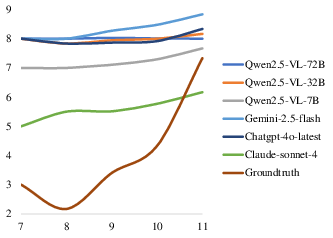
Figure 3: The average scores under pdf-as-image input setting, with context length measured in the number of images.
Key Findings
- Model Scale Matters: Larger models outperform others in generating structured and reliable review comments, indicating a correlation between model size and review quality.
- Reflective Reasoning Benefits: Step-by-step reasoning enhances review quality, with Chain-of-Thought prompting resulting in lower Mean Absolute Error compared to direct judgment tasks.
- Multimodal Robustness: Inclusion of multimodal inputs significantly improves model robustness against prompt injection, suggesting superior evaluative capabilities when image data complements textual analysis.
Future Directions
The benchmark's implementation demonstrates potential for significant improvements in automating aspects of peer review using LLMs. Future work may focus on expanding MMReview to include more comprehensive datasets and refining tasks to capture nuanced aspects of peer review processes. Exploration into strengthening model resistance to input perturbations and biases also remains critical.
Conclusion
MMReview establishes an essential foundation for evaluating LLM-based systems in the peer review domain, paving the way for developing robust automated systems that can assist human reviewers. The integration of multimodal inputs and diverse tasks provides a comprehensive framework that supports nuanced assessments of LLM capabilities, advocating for their potential role in scholarly publishing workflows.