- The paper introduces a novel post-hoc debugging methodology that leverages LLMs to generate natural-language explanations for distributed processes.
- The approach is validated through a web-based demonstrator on a Java system, showcasing interactive and customizable debugging insights.
- Integration considerations highlight the language-agnostic and scalable nature of the method, supporting diverse software architectures.
Post-hoc LLM-Supported Debugging of Distributed Processes
Introduction
The paper "Post-hoc LLM-Supported Debugging of Distributed Processes" (2508.14540) investigates the challenges inherent in debugging complex, distributed systems and proposes a methodology that leverages LLMs to provide natural-language explanations for process behaviors and errors. Traditional debugging methods struggle with the volume and intricacies of modern software systems, which can contain thousands of inter- and intra-component interactions. The proposed method aims to enhance the comprehensibility of these systems by generating articulate explanations based on process data, interfaces, and documentation.
Methodology
The approach is particularly focused on component-based systems. It involves collecting process data during runtime and using it to generate explanations post-hoc. The system records detailed interactions and employs LLMs to distill and summarize pertinent information from subprocesses into a coherent narrative that can guide developers in understanding the source and nature of errors.
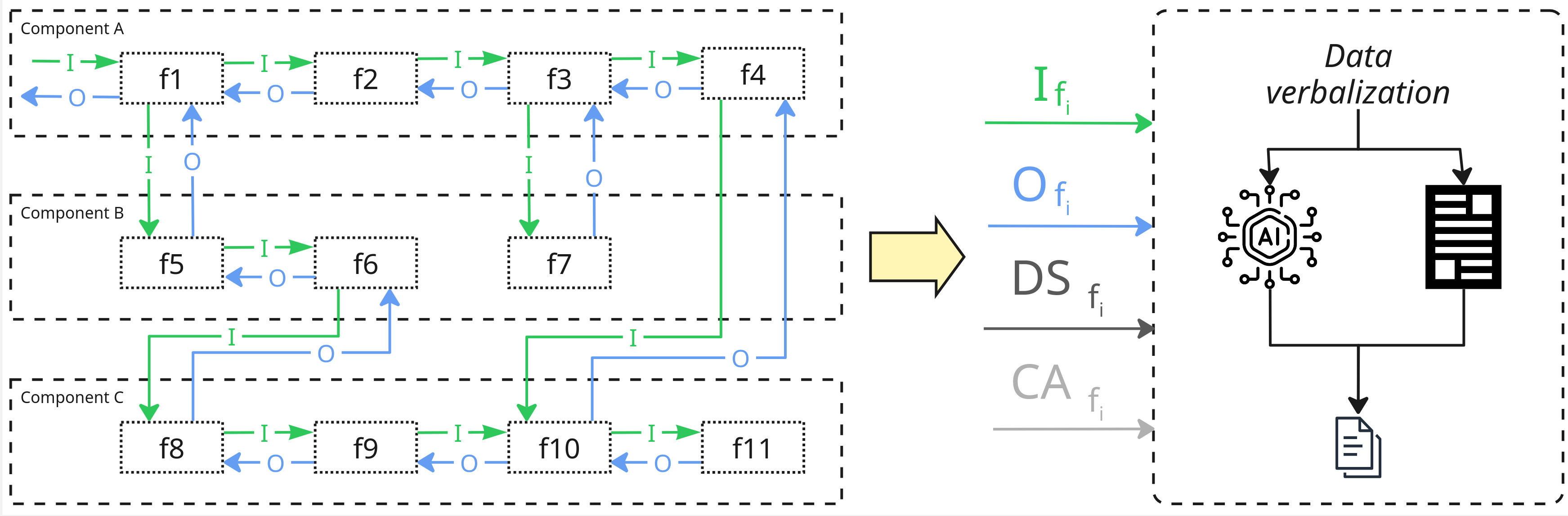
Figure 1: An overview of the process for generating LLM-supported debug explanations.
This figure illustrates the mechanism by which data from component interactions is captured and processed to create hierarchical, human-readable explanations. By incorporating LLMs, the explanations condensed further relevant information, ensuring a focus on the elements that are crucial for understanding the behavior of the system, thereby facilitating more efficient debugging.
Implementation and Demonstrator
A significant contribution of the paper is the implementation of a web-based demonstrator that exemplifies the approach on a Java system. The demonstrator is designed to explore the integration of LLMs into the debugging process, presenting a detailed view of both the explanations generated and the parameters used for their creation.

Figure 2: Screenshot of the demonstrator showing LLM-generated explanations.
Figure 2 provides a glimpse into the functionality of the demonstrator, which features a web interface where users can interact with the system's debugging functionalities. It allows developers to select specific processes, view explanations at various granularities, and customize the explanation generation through the selection of different LLMs and templates. This interaction not only aids in understanding the process but also provides flexibility in tailoring the explanatory content to suit specific needs.
Integration Considerations
The LLM-support extends beyond mere text generation to encompass the aggregation of subordinate explanations into a holistic view of system processes. The considerations in this integration include the persistence of process data via a triplestore architecture and the adaptability of the approach to various programming languages and system architectures. The language-agnostic nature ensures broad applicability across diverse environments, making it a versatile tool in a developer's debugging arsenal.
Conclusion
The methodology presented in the paper marks a pivotal advancement in debugging distributed systems by offering a structured approach to generating natural-language explanations via LLMs. The potential for future developments lies in the enhancement of the explanation quality by incorporating additional data like source code and performance metrics. Such improvements promise to further refine the debugging process in distributed systems, reducing the reliance on manual interventions and fostering an environment where software development and maintenance are more efficient and less error-prone. This approach provides a critical stepping stone toward achieving more autonomous, AI-driven software development practices.