- The paper introduces QvTAD, a framework that combines differential attention with graph-based data augmentation to enhance voice timbre attribute detection.
- The methodology employs a relative timbre shift-aware module to suppress common noise and improve cross-speaker generalization.
- Results on the VCTK-RVA dataset show significant improvements in unseen-speaker accuracy compared to baseline models.
QvTAD: Differential Relative Attribute Learning for Voice Timbre Attribute Detection
Introduction
The paper "QvTAD: Differential Relative Attribute Learning for Voice Timbre Attribute Detection" presents a framework named QvTAD, designed to address challenges in Voice Timbre Attribute Detection (vTAD). This system is proposed to enhance modeling of perceptual timbre attributes by incorporating a novel pairwise comparison framework with differential attention. The inherent subjectivity in timbre descriptors and label imbalance are identified as significant obstacles in existing timbre modeling approaches.
To mitigate these issues, the paper introduces a graph-based data augmentation strategy using Directed Acyclic Graphs (DAGs) and Disjoint-Set Union (DSU) techniques, automatically mining valid attribute comparisons from unobserved utterance pairs (Figure 1). The system employs speaker embeddings from a pretrained FACodec and integrates a Relative Timbre Shift-Aware Differential Attention module to explicitly model contrasts between paired utterances.
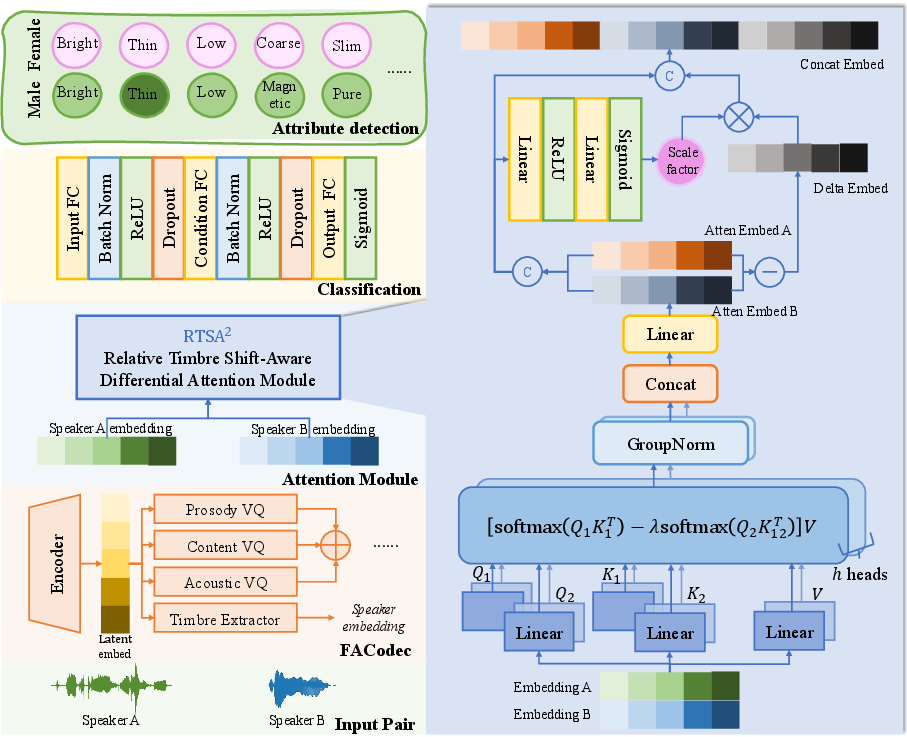
Figure 1: Overview of the proposed QvTAD framework.
Methodology
Differential Attention Framework
QvTAD leverages differential attention by contrasting embeddings from paired utterances to amplify differences in timbre attributes. The proposed Relative Timbre Shift-Aware Differential Attention module performs differential denoising, enhancing attribute-specific contrasts. By suppressing shared noise between query-key pairs, it strengthens discriminative contrast features. This approach allows for accurate prediction of which utterance exhibits stronger presence of a given timbre attribute.
Data Augmentation Strategy
Addressing the label imbalance seen in datasets like VCTK-RVA, QvTAD employs a DSU-based augmentation strategy. Each speaker and associated attribute is abstracted as nodes in a directed graph, where directed edges represent the relative strength of attributes. This graph structure enables the discovery of potential comparable pairs, even if initially unobserved, enriching the training data and ensuring a more balanced distribution of timbre attributes.
Experiments and Results
The VCTK-RVA dataset serves as the evaluation benchmark for QvTAD. Experimental validation indicates substantial improvements in timbre attribute prediction, particularly in cross-speaker generalization scenarios. The model demonstrates enhanced performance in unseen-speaker conditions, marking notable gains over baseline models like ECAPA-TDNN and FACodec, as evidenced in Table 1 below.
| Method |
Seen ACC (%) |
Unseen ACC (%) |
| ECAPA-TDNN (Reported) |
93.83 |
70.60 |
| FACodec (Reported) |
93.02 |
90.72 |
| FACodec (Reproduced) |
86.03 |
75.99 |
| QvTAD-AST |
86.87 |
75.22 |
| QvTAD-RTSA2 |
85.89 |
86.99 |
Ablation Studies
Ablation experiments highlight the contributions of the graph-based data augmentation method and differential attention mechanism. Removal of data augmentation results in accuracy decreases, underscoring its importance in promoting robustness to speaker variations. The exclusion of the RTSA2 module results in reduced performance on unseen speakers, emphasizing the module's significance in generalizing beyond the training dataset.
Conclusion
The QvTAD framework integrates differential attention and advanced data augmentation to effectively model timbre attributes in speech. Its superior performance on the VCTK-RVA dataset showcases its potential for fine-grained acoustic modeling and perceptual attribute understanding. Future research could explore extending QvTAD to multilingual scenarios or enabling real-time synthesis with controllable attributes.