- The paper introduces globally optimal techniques for data reduction using the mRMR criterion and Kullback-Leibler divergence.
- It develops novel polyhedral relaxations and MIP formulations that ensure tighter relaxations and faster computation than benchmark methods.
- Experimental results validate improved predictive efficiency and data representativeness on both real-world and synthetic datasets.
Introduction
The paper "Optimal Data Reduction under Information-Theoretic Criteria" (2508.16123) explores advanced methodologies in data preprocessing aimed at feature and instance selection. These data reduction techniques are pivotal in handling the growing complexity of datasets, particularly in information-rich environments. By proposing solutions for feature selection using the maximum-relevance minimum-redundancy criterion and instance selection based on Kullback-Leibler divergence, the study addresses the inherent challenges posed by data nonconvexities through polyhedral relaxations and mixed-integer linear programming (MIP) formulations.
Data Reduction Techniques
The primary focus of feature selection is to extract a subset of the most relevant features while minimizing redundancy. The mRMR criterion is instrumental here, as it balances the mutual information between features and the target variable against redundancy among the features themselves. This balance is crucial for improved data visualization and predictive efficiency. For instance selection, the study leverages the Kullback-Leibler divergence to ensure the representativeness of data subsets, which simplifies computational constraints without compromising learning quality.
The authors propose novel MIP formulations that effectively address these complex problems, allowing for globally optimal solutions even for practically sized instances. By integrating modern optimization techniques, their approach significantly outperforms existing methods, facilitating more efficient data reduction processes.
Methodology
This study innovatively tackles the nonlinear challenges within data reduction problems. For feature selection under the mRMR criterion, the authors introduce a polyhedral relaxation technique to handle bilinear and fractional structures, leading to formulations that are stronger than existing recursive methods. Their approach not only simplifies the feature selection process but also enhances the precision of the selections made.
Regarding instance selection, the authors develop an exact MIP formulation for the KL divergence method by deriving polyhedral relaxations for the associated log-rational functions. This formulation accurately represents the underlying data distribution, effectively optimizing the data subset size and quality.
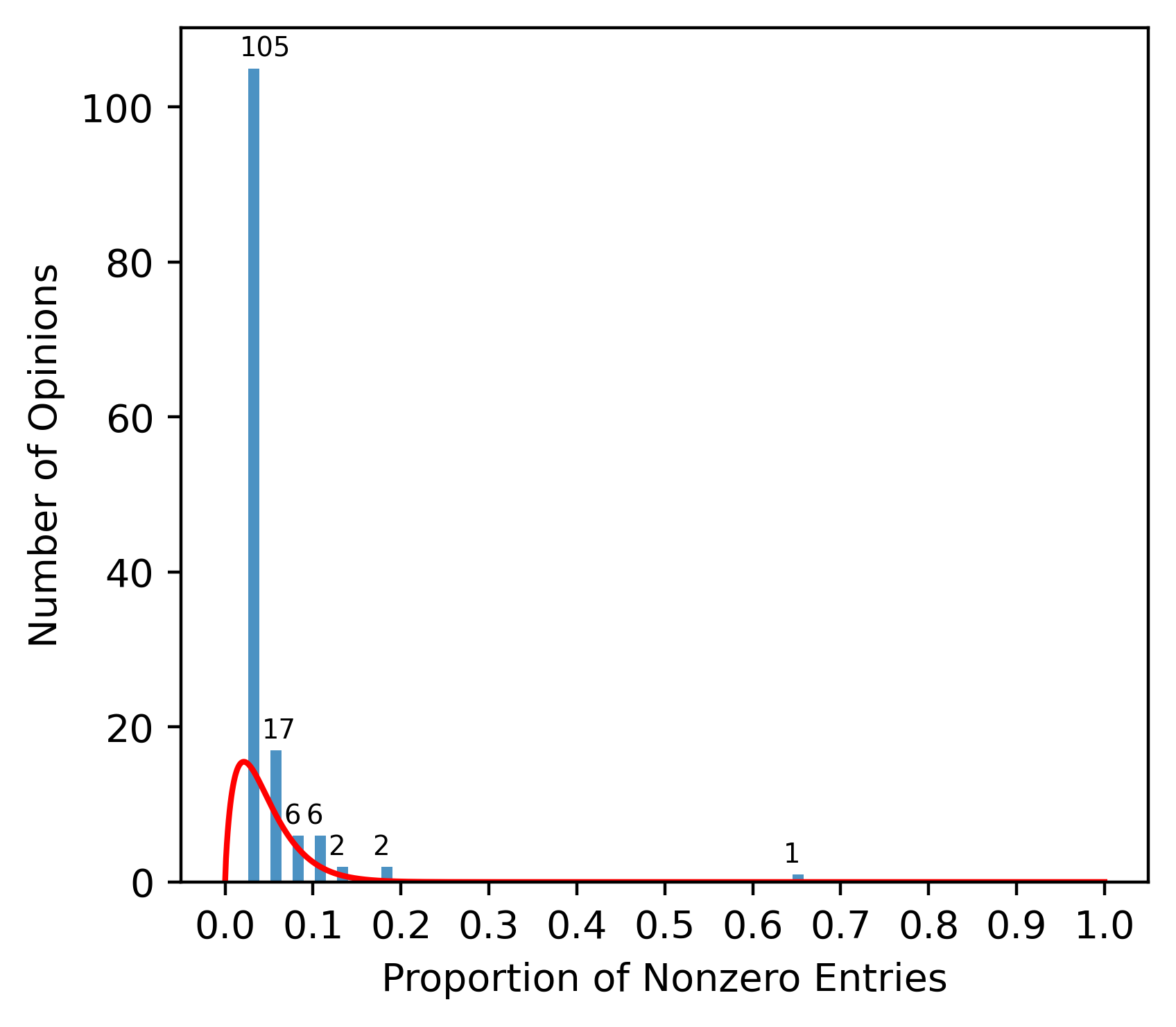
Figure 1: The histogram for the proportion of nonzeros entries of each opinion in sample reviews.
Experimental Results
The proposed methodologies are validated through extensive computational experiments on both real-world and synthetic datasets. The results demonstrate the superior efficiency and accuracy of the authors' approaches compared to alternative methods. The feature selection solution, when applied to real-world datasets, consistently achieves tighter relaxations and optimal solutions more rapidly than benchmark methods. Similarly, the instance selection approach excels in preserving data representativeness across large-scale settings without succumbing to computational inefficiency.
Implications and Future Work
The implications of this research are substantial for the fields of machine learning and data mining. By enhancing the accuracy and efficiency of data reduction techniques, the study contributes to more robust machine learning model development and deployment. These advancements pave the way for exploring more complex datasets with reduced computational overhead, potentially leading to breakthroughs in various applications such as thermodynamics, image processing, and even areas outside traditional data processing, like quantum computing.
Looking forward, further expansions of these techniques could involve exploring their applications in other forms of data preprocessing, such as noise reduction and feature extraction under different criteria. The potential for integrating these preprocessing methods into larger machine learning pipelines also presents an interesting direction for future research.
Conclusion
The research presented in this paper marks a significant advancement in data reduction techniques by providing globally optimal solutions to feature and instance selection problems using information-theoretic criteria. The proposed polyhedral relaxation-based MIP formulations overcome the typical hurdles of nonlinear optimization, demonstrating a robust approach to data management for complex datasets. This work sets a foundational precedent for further advancements and practical implementations in large-scale data processing.