- The paper introduces an autonomous AI Data Scientist that streamlines data cleaning, hypothesis testing, feature engineering, and model training into a single automated workflow.
- It employs six specialized Subagents and rigorous statistical methods like chi-square tests and ANOVA to validate data-driven hypotheses at every stage of the pipeline.
- The system demonstrates superior performance in efficiency and accuracy, providing actionable business insights from diverse datasets.
The AI Data Scientist
Introduction
In the pursuit of transforming vast amounts of raw organizational data into insightful and actionable recommendations, the "AI Data Scientist" emerges as a promising autonomous agent powered by LLMs. Unlike traditional data science methodologies which entail sequential, labor-intensive processes, this agent streamlines the workflow into an end-to-end automated system. This comprehensive AI system integrates hypothesis testing into the core of its operations, thereby ensuring that each step in the data processing, from cleaning to feature engineering and modeling, is statistically validated and driven by meaningful insights.
System Architecture and Operation
At the heart of the AI Data Scientist are six specialized Subagents, each performing a distinct task within the data science pipeline: Data Cleaning, Hypothesis Generation, Preprocessing, Feature Engineering, Model Training, and Call-to-Action.
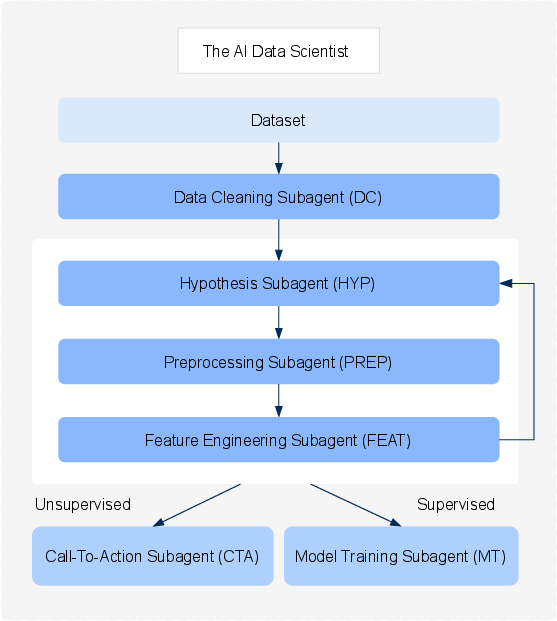
Figure 1: Overview of the hypothesis-driven AI Data Scientist. Six specialized Subagents work together to transform raw data into business-ready recommendations. The system iteratively tests hypotheses, validates results, creates features, and trains predictive models.
The system begins with the Data Cleaning Subagent, which addresses common issues such as missing values and outliers, employing techniques like Multiple Imputation by Chained Equations for nuanced scenarios. This ensures a robust foundation for subsequent analysis. Each transformation is meticulously recorded, allowing for transparency and traceability throughout the workflow.
Hypothesis-Driven Analysis
The Hypothesis Subagent is a pivotal component that distinguishes this system from conventional approaches. It autonomously generates potential explanations based on data and validates them using statistical methods like chi-square tests and ANOVA (Figure 2). By only forwarding validated hypotheses, the system ensures that subsequent modeling steps are grounded in statistically significant relationships.
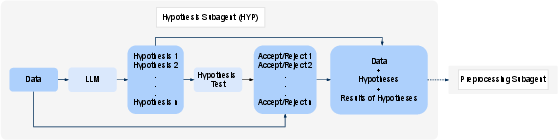
Figure 2: How the Hypothesis Subagent works. It automatically generates potential explanations from data and then rigorously tests each one using statistical methods such as chi-square and ANOVA. Only validated hypotheses move forward to guide feature engineering and modeling.

Figure 3: Sample hypotheses generated by the Hypothesis Subagent. Each hypothesis is statistically tested. If validated, it is used to create features that support predictive modeling. This ensures that every modeling step is based on meaningful, data-backed insights.
From Data to Business Insights
Once hypotheses are employed to guide feature engineering, the Preprocessing and Feature Engineering Subagents apply transformations and create predictive features that are statistically justified. The Model Training Subagent capitalizes on these enriched inputs by leveraging an array of machine learning models. It employs both ensemble strategies and individual models, ensuring robust predictive capabilities across diverse datasets.
The Call-to-Action Subagent concludes the process by translating technical findings into clear, actionable business recommendations (Figure 4). This component is crucial for bridging the gap between data analysis and actionable business strategy, offering stakeholders practical steps illuminated by data-backed insights.

Figure 4: From data to decisions. The Call-to-Action Subagent translates validated hypotheses into clear and actionable recommendations for business stakeholders. It connects analytical findings with practical business strategies.
Experimental Evaluation
The system was rigorously evaluated across various datasets, demonstrating superior performance in accuracy and efficiency when compared to traditional methods (Figure 5). This consistent performance across classification and regression tasks substantiates the system’s model-agnostic nature and highlights its utility as a versatile tool in automating the data science workflow.
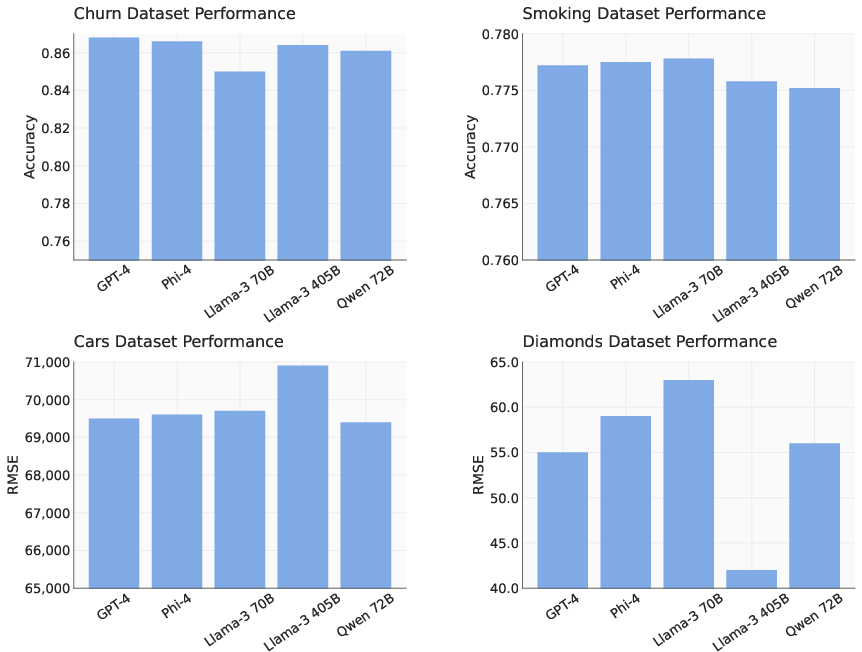
Figure 5: Model-agnostic performance. The AI Data Scientist delivers consistent results across a variety of LLMs. It shows strong accuracy and stability in both classification and regression tasks.
Conclusion
The AI Data Scientist marks a significant advancement in the automation of the data science pipeline. By integrating hypothesis testing early in the process, it provides a structured and scientifically rigorous pathway from raw data to actionable insights. This system not only enhances the efficiency of data processing but also ensures that models are built on robust, validated insights, thereby facilitating more confident decision-making. As organizations continue to navigate the complexities of big data, the capabilities offered by the AI Data Scientist could prove invaluable in driving both strategic insights and operational efficiencies. Future developments could aim at enhancing its capabilities in causal inference and adaptability to evolving data landscapes, paving the way for even more profound impacts in the field of data science.

