MIRAGE: Scaling Test-Time Inference with Parallel Graph-Retrieval-Augmented Reasoning Chains
Abstract: Large reasoning models (LRMs) have shown significant progress in test-time scaling through chain-of-thought prompting. Current approaches like search-o1 integrate retrieval augmented generation (RAG) into multi-step reasoning processes but rely on a single, linear reasoning chain while incorporating unstructured textual information in a flat, context-agnostic manner. As a result, these approaches can lead to error accumulation throughout the reasoning chain, which significantly limits its effectiveness in medical question-answering (QA) tasks where both accuracy and traceability are critical requirements. To address these challenges, we propose MIRAGE (Multi-chain Inference with Retrieval-Augmented Graph Exploration), a novel test-time scalable reasoning framework that performs dynamic multi-chain inference over structured medical knowledge graphs. Specifically, MIRAGE 1) decomposes complex queries into entity-grounded sub-questions, 2) executes parallel inference chains, 3) retrieves evidence adaptively via neighbor expansion and multi-hop traversal, and 4) integrates answers using cross-chain verification to resolve contradictions. Experiments on three medical QA benchmarks (GenMedGPT-5k, CMCQA, and ExplainCPE) show that MIRAGE consistently outperforms GPT-4o, Tree-of-Thought variants, and other retrieval-augmented baselines in both automatic and human evaluations. Additionally, MIRAGE improves interpretability by generating explicit reasoning chains that trace each factual claim to concrete chains within the knowledge graph, making it well-suited for complex medical reasoning scenarios. The code will be available for further research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and uncertainties that could guide future research.
- Dependence on curated medical knowledge graphs (KGs): No analysis of robustness to KG incompleteness, outdated facts, regional biases, or noisy/contradictory edges; unclear how performance degrades as coverage drops or errors increase.
- Hybrid retrieval under KG sparsity: The system falls back to “medical priors” when the KG is silent but does not explore or evaluate hybrid strategies that combine structured KG retrieval with vetted unstructured sources while maintaining provenance and faithfulness.
- Entity grounding and disambiguation: The soft-matching threshold τ, candidate generation, and tie-breaking strategies are not specified or ablated; sensitivity to synonymy, polysemy, OOD entities, and cross-lingual mentions remains unquantified.
- Graph traversal design: Key parameters (neighbor cap k, hop limit h) and the path-search/ranking algorithm are not detailed or evaluated; risks of path explosion, spurious multi-hop paths, and their pruning/selection criteria are not analyzed.
- Cross-chain verification mechanism: The “majority-based” selection over chain sets lacks a formal definition, uncertainty modeling, and ablation; no comparison with probabilistic/Bayesian aggregation, confidence calibration, or causal consistency checks.
- Failure handling in the retrieval loop: Termination criteria, retry strategies after no_entity_match, and handling of conflicting or cyclic paths are unspecified; no quantitative analysis of dead ends or reformulation success rates.
- Parallelization claims vs. actual concurrency: The Coordinator is described conceptually, but implementation details (true parallel execution, scheduling, resource contention, and synchronization) and empirical latency/throughput benchmarks are absent.
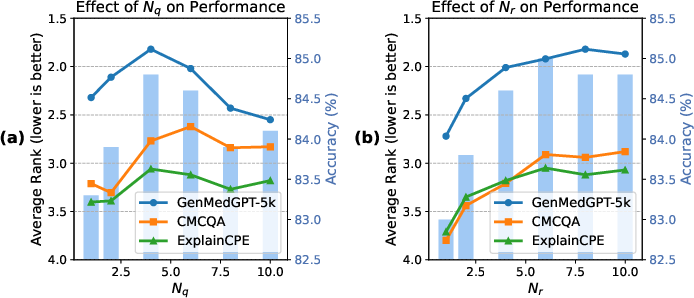
- Compute and cost efficiency: No reporting of wall-clock time, token usage, memory footprint, or cost-per-question versus single-chain or ToT baselines; scaling behavior with increasing Nq, Nr, k, h, and graph size remains unknown.
- Generalization beyond medicine: The method’s reliance on clinically validated relation schemas raises questions about portability to other domains with different ontologies, relation semantics, or sparser KGs.
- Dialogue handling: The method shows potential performance drops with decomposition in dialogue-style tasks; no exploration of interactive clarification, turn-level decomposition policies, or memory mechanisms tailored to multi-turn QA.
- Evaluation fidelity and bias: Heavy reliance on BERTScore and GPT-4o ranking; limited human evaluation (n=100, 2 raters) without inter-annotator agreement statistics; no task-specific clinical correctness, safety, or faithfulness metrics to the cited graph paths.
- Evidence faithfulness and attribution: While paths are logged, no quantitative measure of whether generated answers strictly rely on retrieved paths (faithfulness), how often hallucinations occur, or how accurate/complete the cited chains are.
- Safety and clinical risk: No safety guardrails, contraindication checks beyond limited rules, or assessment of harmful recommendation rates; no clinician-in-the-loop evaluation, prospective user studies, or post-hoc harm analysis.
- Multilingual and cross-lingual grounding: Datasets span English and Chinese, but cross-lingual entity mapping, KG alignment, and performance disparities by language are not examined.
- Error analysis depth: Limited breakdown of failure modes (e.g., grounding errors, retrieval misses, aggregation mistakes, synthesis hallucinations); no stratification by question difficulty, hop distance, or symptom/disease rarity.
- Ablation granularity: Ablations remove Decomposer and/or Synthesizer, but there is no component-level analysis of Anchor vs. Bridge modes, cross-chain verification strategies, or single-chain variants of MIRAGE using the same KG.
- Parameter sensitivity: Only Nq and Nr are studied; no sensitivity or robustness analyses for τ (matching threshold), k (neighbor cap), h (hop limit), temperature/decoding settings, or prompt variants.
- Path semantics (causal vs. associative): The framework treats typed relations uniformly; no mechanism to distinguish causation from correlation or to prefer clinically causal chains in synthesis and verification.
- Handling quantitative/temporal constraints: Unit normalization is mentioned, but there is no evaluation of dose/temporal reasoning, time-aware relations, or the impact of temporal contradictions in the KG.
- Backbone dependence: Main results use QWQ-32B; limited tests with DeepSeek-R1-32B on a single dataset; no analysis across broader backbones (e.g., Llama, GPT-4 variants) or model sizes, nor how backbone reasoning style interacts with MIRAGE.
- Real-world integration: No discussion of deployment with EHR systems, privacy constraints, PHI handling, regulatory compliance, or audit workflows for clinical environments despite generating “patient-oriented” advice.
- Statistical rigor: No confidence intervals or significance testing for metric improvements; lack of per-dataset variance and effect sizes hampers conclusions about consistent gains.
- Reproducibility gaps: Code “will be available,” but critical configuration details (e.g., τ, k, h, prompt templates, scheduler settings) and KG versions are not fully specified; reproducibility and comparability may be limited.
- Adaptive decomposition policy: The current trigger (multiple entities) may miss necessary decompositions for single-entity but multi-faceted queries; no learned or uncertainty-aware policy to decide when and how to split.
- Robustness to adversarial or out-of-scope inputs: No experiments on misspellings, layperson terminology, conflicting symptoms, or adversarial prompts; resilience under such conditions remains unknown.
Practical Applications
Immediate Applications
Below are practical applications that can be deployed with existing LLMs and curated knowledge graphs, leveraging MIRAGE’s multi-chain, graph-based retrieval and cross-chain verification.
- Clinical QA assistant for patient portals
- Sector: Healthcare; Daily life
- Use case: Answer patient questions about symptoms, conditions, and lifestyle factors with traceable citations to the medical knowledge graph.
- Tools/products/workflows: “Graph-RAG Clinical Copilot” powered by MIRAGE; connectors to EMCKG/CMCKG; audit-record export (JSON) for provenance; LLM orchestrator with Coordinator module.
- Assumptions/dependencies: Availability and coverage of a clinically validated medical KG; clinician-approved guardrails; latency acceptable for portal use; HIPAA/GDPR compliance.
- Nurse line and telehealth triage support
- Sector: Healthcare
- Use case: Parallel chains decompose multi-symptom calls (e.g., chest pain + fatigue), retrieve structured evidence, and propose risk-ranked triage advice with conflict checks.
- Tools/products/workflows: MIRAGE API integrated into call-center CRM; real-time KG queries via Anchor and Bridge modes; cross-chain verification to suppress inconsistent advice.
- Assumptions/dependencies: Real-time compute budget; escalation workflow to human clinicians; liability frameworks; robust KG relations (symptom→condition, condition→risk).
- Medication interaction and contraindication checker
- Sector: Healthcare; Pharmacy
- Use case: Bridge-mode reasoning across drug–condition–symptom relations to flag adverse interactions and contradictory effects (e.g., drug both treats and exacerbates a symptom).
- Tools/products/workflows: Pharmacy app plugin; EHR medication order checker; MIRAGE synthesizer enforcing consistency and dosage normalization.
- Assumptions/dependencies: Up-to-date pharmacopeia KG; dosage/unit normalization rules; regional labeling differences; pharmacist oversight.
- Clinical documentation copilot for EHR notes
- Sector: Healthcare; Software
- Use case: Suggest structured differentials and management steps with explicit KG-backed citations; detect contradictions within the draft note.
- Tools/products/workflows: EHR sidebar widget; MIRAGE Answer Synthesizer; provenance audit logs attached to chart notes.
- Assumptions/dependencies: Integration with EHR vendor APIs; data privacy controls; clinician-in-the-loop review; institution-specific guideline mappings in the KG.
- Guideline and order-set compliance checker
- Sector: Healthcare; Policy/compliance
- Use case: Verify that proposed care plans align with curated guideline relations (e.g., first-line therapy, contraindications) and suppress inconsistent orders.
- Tools/products/workflows: Hospital QA dashboards; MIRAGE verification prompts; rule overlays atop KG relations.
- Assumptions/dependencies: Access to region-specific clinical guidelines encoded in KG; institutional policy alignment; auditability requirements.
- Knowledge-base curation and gap analysis
- Sector: Academia; Healthcare informatics
- Use case: Use MIRAGE audit records to identify missing or low-confidence edges and noisy entities; prioritize human curation.
- Tools/products/workflows: KG maintenance pipeline; discrepancy dashboards; human-in-the-loop validation queues.
- Assumptions/dependencies: Editorial process; versioning; continuous ingestion of curated sources; acceptance testing.
- AI governance and safety auditing for LLM outputs
- Sector: Policy; Enterprise risk
- Use case: Attach machine-readable audit records to answers (decomposition steps, KG paths, verification decisions) to enable post-hoc reviews and incident analysis.
- Tools/products/workflows: MIRAGE audit trail + provenance viewer; compliance checks against internal standards; red-teaming workflows.
- Assumptions/dependencies: Standardized audit schemas; secure log storage; reviewer training; alignment with regulatory guidance.
- Medical education tutoring and case-based learning
- Sector: Education
- Use case: Decompose student questions into entity-grounded sub-questions; show evidence chains and cross-chain reconciliations to teach multi-hop clinical reasoning.
- Tools/products/workflows: Interactive tutor with MIRAGE “show-your-work” mode; KG visualizer of Anchor/Bridge paths; assessment integration.
- Assumptions/dependencies: Didactic KG with pedagogical annotations; faculty oversight; alignment with curricula.
- Domain-agnostic customer support over product/policy knowledge graphs
- Sector: Finance; Insurance; Software; Public services
- Use case: Answer complex policy questions (e.g., coverage rules, product eligibility) by traversing structured rule graphs and reconciling conflicts.
- Tools/products/workflows: MIRAGE-backed “Policy Copilot” for agents/self-service; rule KG connectors; contradiction resolution via Synthesizer.
- Assumptions/dependencies: High-quality, up-to-date enterprise KGs; access controls; latency SLAs; legal review.
- Consumer-facing health guidance with guardrails
- Sector: Daily life; Healthcare
- Use case: Symptom checkers, nutrition planning, and lifestyle recommendations grounded in KG relations; clear disclaimers and escalation prompts.
- Tools/products/workflows: Mobile wellness apps; MIRAGE parallel reasoning chains for multi-factor queries; safety rails and referral thresholds.
- Assumptions/dependencies: Coverage of diet, exercise, and common conditions in KG; localized content; safety and escalation policies.
Long-Term Applications
The following applications require additional research, scaling, integration, or validation before widespread deployment.
- Point-of-care clinical decision support integrated with EHRs
- Sector: Healthcare
- Use case: Real-time, patient-specific reasoning that fuses structured patient data (labs, vitals, meds) with KG evidence and cross-chain verification.
- Tools/products/workflows: MIRAGE + clinical data graph (patient timelines as nodes); context windows extended via streaming; on-call compute orchestration.
- Assumptions/dependencies: Rigorous clinical validation; regulatory approval; reliable data harmonization (FHIR); safety monitoring and human oversight.
- Federated, privacy-preserving hospital knowledge graph networks
- Sector: Healthcare; Policy
- Use case: Hospitals share de-identified relational knowledge via federated KG to improve coverage and reduce biases; MIRAGE operates across shards.
- Tools/products/workflows: Federated KG protocols; differential privacy; decentralized MIRAGE Coordinator; cross-site audit reconciliation.
- Assumptions/dependencies: Legal frameworks for inter-institutional sharing; interoperability standards; privacy guarantees; governance bodies.
- Multi-modal diagnostic agents (text + labs + imaging + wearables)
- Sector: Healthcare; Robotics
- Use case: Extend MIRAGE to integrate multi-modal evidence nodes; bridge textual findings with signals and images for robust diagnosis support.
- Tools/products/workflows: Multi-modal KG schema; embeddings for images/time-series; safety-tuned Synthesizer with uncertainty handling.
- Assumptions/dependencies: New graph schemas; calibrated uncertainty; data consent; model robustness across modalities.
- Pharmacovigilance and safety signal detection
- Sector: Healthcare; Regulatory
- Use case: Use Synthesizer’s contradiction flags and cross-chain evidence to detect emerging adverse events from pharmacovigilance databases and literature graphs.
- Tools/products/workflows: Ingestion from VAERS/EudraVigilance; literature-to-KG pipelines; MIRAGE anomaly detection workflows; regulator dashboards.
- Assumptions/dependencies: High-quality, timely data; signal detection validation; cross-jurisdiction harmonization; domain expert review.
- Public health policy Q&A and surveillance
- Sector: Policy; Public health
- Use case: Traceable answers linking interventions to evidence across epidemiology KGs, guidelines, and outcomes; scenario analysis via parallel chains.
- Tools/products/workflows: Policy KG (guidelines→measures→outcomes); MIRAGE “scenario planner” with audit trails; simulation hooks.
- Assumptions/dependencies: Comprehensive, updated policy KGs; non-text data integration; transparency requirements; civic oversight.
- Autonomous literature review and knowledge synthesis
- Sector: Academia; Pharma R&D
- Use case: Build and traverse literature-derived KGs (entities, claims, causal links) with cross-chain verification to produce living systematic reviews.
- Tools/products/workflows: NLP pipelines for claim extraction; provenance-preserving KG; MIRAGE synthesis with contradiction suppression; expert curation loop.
- Assumptions/dependencies: Accurate extraction at scale; citation normalization; domain expert validation; continual updates.
- Cross-domain reasoning in law, finance, energy, and cybersecurity
- Sector: Legal; Finance; Energy; Cybersecurity
- Use case: Apply parallel graph-retrieval chains to statutes/contracts (legal), risk/derivatives (finance), grid topology (energy), and provenance graphs (security) to improve accuracy and traceability.
- Tools/products/workflows: Domain-specific KGs; MIRAGE orchestration; compliance/audit viewers; scenario testing.
- Assumptions/dependencies: Mature domain KGs; regulatory buy-in; bespoke relation types; performance tuning for domain complexity.
- MIRAGE-as-a-Service and MLOps ecosystem
- Sector: Software; Cloud
- Use case: Managed service offering with scaling controls (N_q, N_r), KG connectors, audit log APIs, and cost-aware parallelization.
- Tools/products/workflows: Cloud orchestration with autoscaling; GPU scheduling for parallel chains; observability for reasoning steps; cost dashboards.
- Assumptions/dependencies: Stable APIs; enterprise security certifications; SRE support; predictable workloads and SLAs.
- Safety certification and standards for reasoning auditability
- Sector: Policy; Standards bodies
- Use case: Define standard audit formats and evaluation protocols for multi-chain reasoning systems, enabling certification and cross-vendor comparability.
- Tools/products/workflows: Open audit schema; benchmark suites (medical QA, multi-hop tasks); calibration metrics for contradiction detection.
- Assumptions/dependencies: Multi-stakeholder consensus; participation from regulators and vendors; reference implementations.
- Edge and on-device deployment for privacy-sensitive settings
- Sector: Healthcare; Consumer devices
- Use case: Lightweight MIRAGE variants running on local hardware for private health querying; limited KG slices cached on-device.
- Tools/products/workflows: Distilled LRM backbones; KG compression; offline audit logging; secure update channels.
- Assumptions/dependencies: Model/graph compression quality; device capabilities; robust offline safety rails; periodic sync with authoritative KG.
Notes on feasibility and adoption
- Performance depends on KG quality, coverage, and correctness; benefits decline with sparse or noisy graphs.
- Parallel multi-chain reasoning trades accuracy and interpretability for compute cost; budget and latency constraints must be managed.
- Medical deployments require clinical validation, clear disclaimers, and clinician oversight; MIRAGE should augment—not replace—professional judgment.
- Parameterization (e.g., sub-question cap N_q, retrieval budget N_r) affects accuracy vs. noise; production systems need adaptive controls and monitoring.
- Provenance and audit logging are central enablers for policy, compliance, and trust; storage, access control, and reviewer workflows must be established.
Collections
Sign up for free to add this paper to one or more collections.