Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks
Abstract: Empirical scaling laws have driven the evolution of LLMs, yet their coefficients shift whenever the model architecture or data pipeline changes. Mixture-of-Experts (MoE) models, now standard in state-of-the-art systems, introduce a new sparsity dimension that current dense-model frontiers overlook. We investigate how MoE sparsity influences two distinct capability regimes: memorization skills and reasoning skills. By training MoE families that vary total parameters, active parameters, and top-$k$ routing under fixed compute budgets, we disentangle pre-training loss from downstream accuracy. Our results reveal two principles. First, Active FLOPs: models with identical training loss but greater active compute achieve higher reasoning accuracy. Second, Total tokens per parameter (TPP): memorization tasks improve with more parameters, while reasoning tasks benefit from optimal TPP, indicating that reasoning is data-hungry. Neither reinforcement learning post-training (GRPO) nor increased test-time compute alters these trends. We therefore argue that optimal MoE sparsity must be determined jointly by active FLOPs and TPP, revising the classical picture of compute-optimal scaling. Our model checkpoints, code and logs are open-source at https://github.com/rioyokotalab/optimal-sparsity.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑English Summary of “Optimal Sparsity of Mixture‑of‑Experts LLMs for Reasoning Tasks”
1) What is this paper about?
The paper studies how to build smarter LLMs that can both remember facts and solve problems. It focuses on a popular design called a Mixture‑of‑Experts (MoE), where the model has many “experts” (small specialist networks) but only a few are used for each word. The big question: how many experts should be active at once, and how many total should we have, to get the best reasoning skills?
2) What questions are the researchers asking?
- How does “sparsity” (having many experts but using only a few per word) affect two kinds of skills:
- Memorization skills (like trivia and common sense)
- Reasoning skills (like step‑by‑step math)?
- If we keep the training effort the same, what mix of experts and activity works best?
- Do tricks after training (like reinforcement learning) or using more compute at test time change the best setup?
3) How did they test this? (Explained with simple analogies)
Think of the model as a big school with many tutors (experts). For each question (token), a “router” picks the top‑k tutors to answer it.
Key ideas in everyday terms:
- MoE model: A school with lots of tutors; each question goes to only a few tutors.
- Sparsity: Most tutors are idle most of the time. Higher sparsity means you have more tutors overall, but you still ask only a few to help each time.
- Top‑k: How many tutors you ask per question.
- Active parameters / Active FLOPs: The brainpower actually used per question (how many tutors actively help).
- Total parameters: The total staff on payroll, even if most don’t help on a given question.
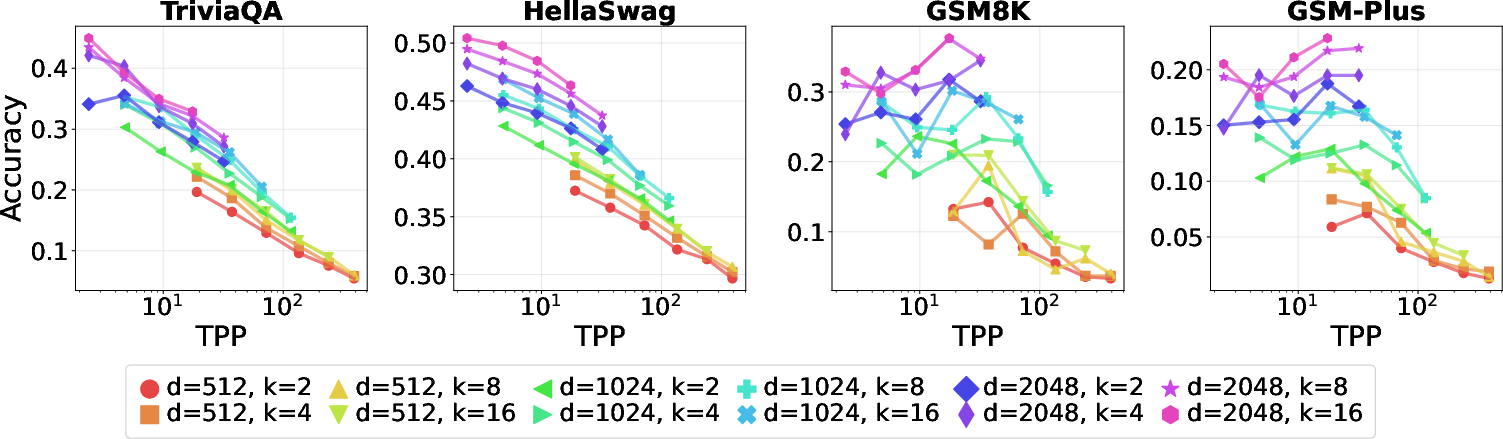
- Tokens per parameter (TPP): How much practice each “unit of brain” gets. It’s like how many practice problems each tutor sees during training. A higher TPP means more data per unit of model size.
What they did:
- They built many MoE models with different numbers of total experts, different top‑k (how many experts you consult per word), and different widths (size of layers).
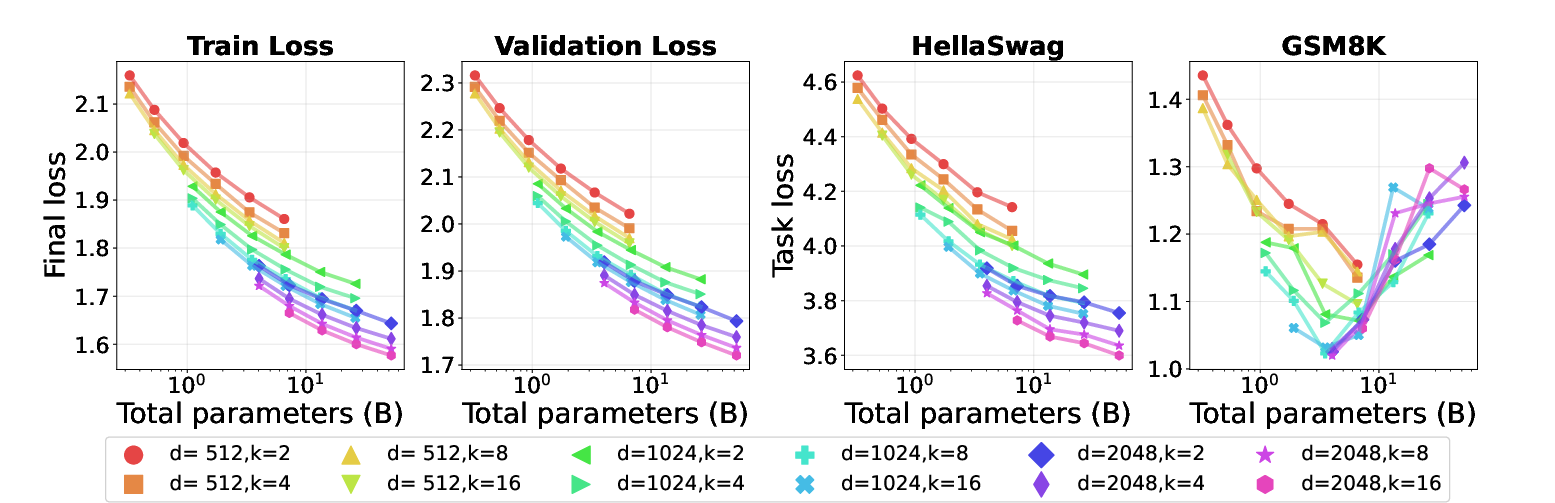
- They trained all models under fixed compute budgets (same total “training effort”) on the same 125 billion tokens of data.
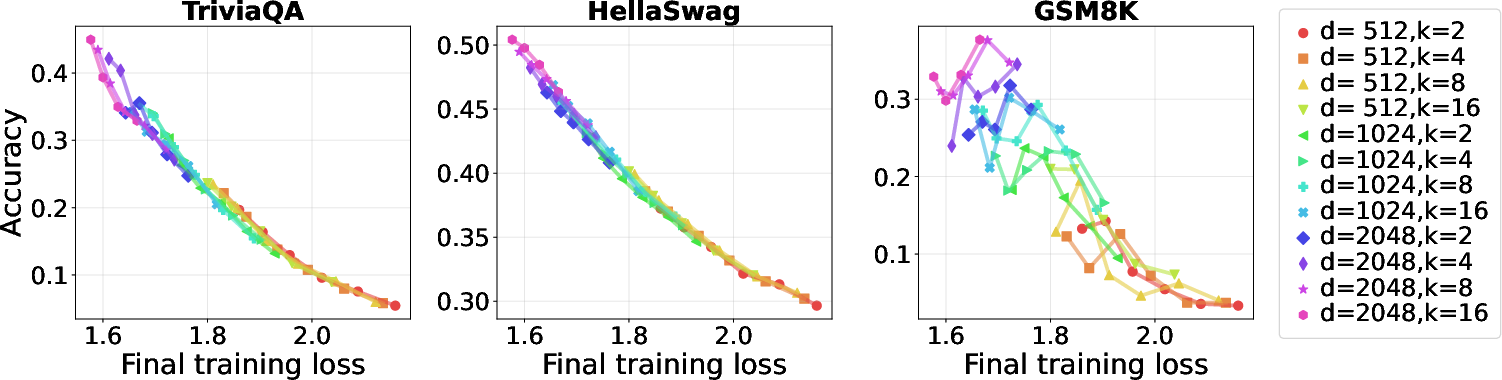
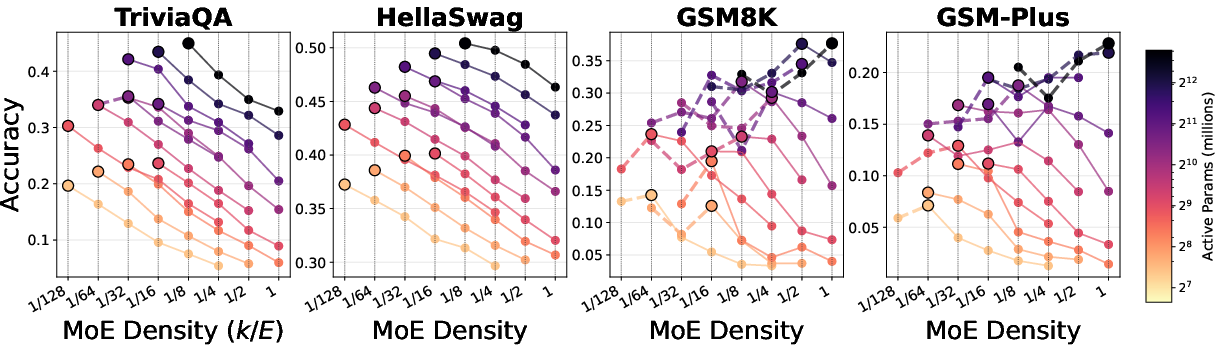
- They evaluated two memorization tasks (TriviaQA, HellaSwag) and two reasoning tasks (GSM8K, GSM‑Plus).
- They also tried:
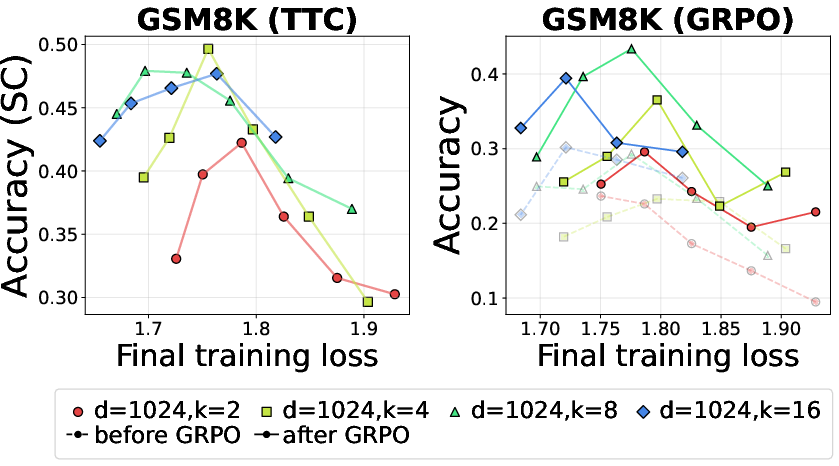
- Reinforcement learning post‑training (GRPO) to improve reasoning.
- Test‑time compute (Self‑Consistency) to boost accuracy by sampling multiple answers and voting.
4) What did they find, and why does it matter?
Main findings (the two big rules):
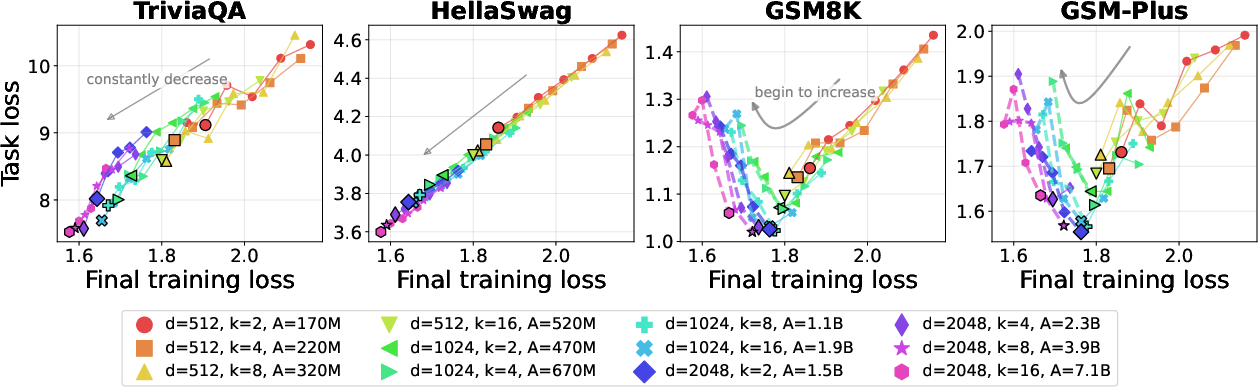
- Active FLOPs rule: Reasoning quality depends on how much compute the model actually uses per token (active compute), not just how low the training loss is or how large the model is overall.
- Two models can have the same training loss, but the one that uses more experts per token (more active compute) usually reasons better.
- If you only add more total experts (making the model sparser) but don’t increase how many are used per token, reasoning can get worse—even if the training loss looks better.
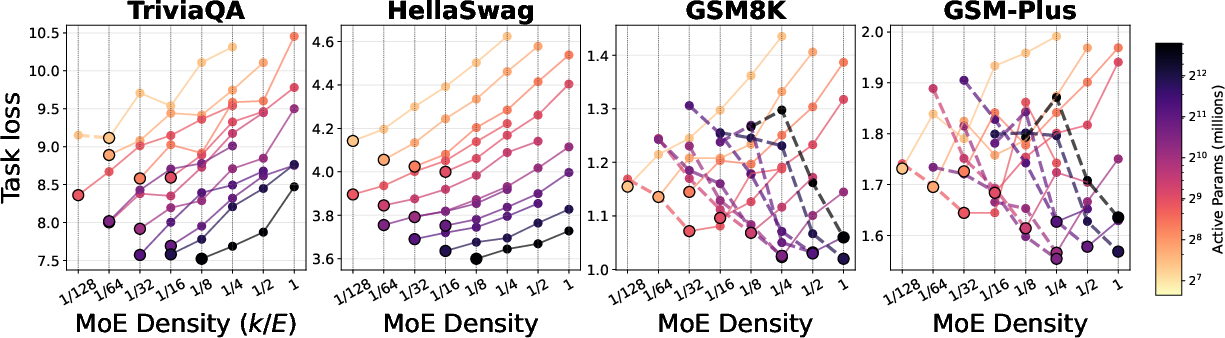
- TPP rule (tokens per parameter): Reasoning is data‑hungry and peaks around about 20 tokens per parameter, while memorization is parameter‑hungry.
- Memorization tasks keep improving as you add more total experts (more capacity) and reduce TPP (more parameters per token).
- Reasoning tasks show a “sweet spot”: performance is best near TPP ≈ 20. If TPP is too low (too many parameters for the amount of data), reasoning gets worse. If TPP is too high (too little capacity for the data), reasoning also drops.
Other important observations:
- Training loss alone is misleading for reasoning. As models get bigger and training loss keeps going down, math reasoning can first improve and then get worse (an inverted‑U shape).
- Under fixed compute, sparser MoE models help memorization, but as you increase the compute budget, denser settings (using more experts per token) tend to win for reasoning.
- Simply changing top‑k isn’t magic by itself; what matters is how much active compute you actually allocate per token.
- Post‑training with GRPO and using extra test‑time compute (like Self‑Consistency) boost scores, but they do not remove the fundamental trade‑offs. If the model was too sparse for reasoning during pre‑training, these methods can’t fully fix it.
- Similar patterns show up in coding tasks: when compute is small, sparsity helps; when compute is large, denser setups give better step‑by‑step code reasoning.
Why it matters:
- It challenges the old idea that you should just keep adding parameters or just chase lower training loss. For reasoning, how you spend compute during both training and inference matters more.
5) So what’s the big takeaway?
If you want a model that reasons well, you must plan:
- Enough active compute per token (use enough experts per word).
- The right balance of data and parameters (TPP near the sweet spot, around 20 for these setups).
In short:
- Memorization thrives with more total experts and higher sparsity.
- Reasoning thrives when you balance active compute and data per parameter—often favoring denser configurations as you scale up compute.
- Post‑training tricks and extra test‑time compute help, but they won’t fix a poor sparsity choice made during pre‑training.
This gives builders a clearer recipe: don’t just make MoE models bigger; make sure the model actually uses enough of its brain on each token and gets the right amount of practice per unit of capacity.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide concrete follow-up research.
- Data contamination and distributional shift control:
- Quantify and report the impact of GSM8K (and synthetic math) contamination in pre-training on GSM8K evaluation. Provide decontaminated results side-by-side and ablate all potential leakage sources (datasets, templates, CoT artifacts).
- Measure how sensitive the observed inverse-U trends are to more controlled train/test distribution gaps (e.g., unseen math domains, unseen problem formats, multilingual math).
- Token–parameter trade-off (TPP) identification without confounds:
- Validate the claimed reasoning-optimal TPP ≈ 20 by directly varying the token budget (not only by altering total parameters via experts). Hold parameters fixed and scale tokens to disentangle data effects from capacity effects.
- Compare “TPP per total parameters” versus “TPP per active parameters” (TPP_active). Establish which definition predicts reasoning performance more reliably for MoE.
- Mechanistic understanding of reasoning degradation:
- Probe router behavior and expert specialization (e.g., routing entropy, per-expert utilization, specialization to math/code) to test whether sparsity induces brittle specialization or overfitting in few experts.
- Conduct mechanistic interpretability or representational analyses (e.g., linear probes, activation patching) to explain why task loss and accuracy diverge for reasoning as sparsity increases.
- Architectural design space underexplored:
- Systematically vary depth, MoE placement (subset of layers vs all layers), per-layer density (layerwise k/E), and shared/dense experts to test whether the inverse-U persists across configurations.
- Study alternative routing schemes (noisy gates, temperature schedules, capacity constraints, soft routing, multi-gate, residual-mix experts) and hyperparameters (router z-loss, load-balancing weight) to see if the trade-off can be mitigated.
- Explore adaptive or dynamic top-k at training and/or inference (difficulty-aware routing) to increase active FLOPs only where needed.
- Scale and generality of conclusions:
- Validate trends at larger widths (e.g., d ≥ 4k), more experts (E > 256), and higher k to test asymptotic behavior and assess whether optima shift at frontier scales.
- Extend beyond a small set of English benchmarks to multilingual, multimodal, and diverse reasoning tasks (e.g., theorem proving, formal logic, long-form math, multi-hop QA) to assess external validity.
- Optimization and regularization controls:
- Go beyond the limited LR/initialization/epsilon sweeps: test label smoothing, dropout in MoE layers, data augmentation, mixup, and weight decay schedules to reduce the reasoning generalization gap while keeping sparsity.
- Characterize the role of gradient noise scale and training schedule length on the onset of inverse-scaling in reasoning tasks.
- Post-training and test-time compute (TTC) coverage:
- Evaluate stronger TTC methods (tree search, verifiers, tool use, program-of-thought, reflective or debate-style inference) and process-supervised RL (e.g., verifier-guided GRPO/RL) to test whether more powerful methods can neutralize the sparsity-induced gap.
- Explore inference-time changes to routing (e.g., increasing k at test time, ensemble over router randomness) and measure cost–quality trade-offs.
- Compute accounting and practicality:
- Incorporate end-to-end system costs (communication, memory bandwidth, routing overhead, load imbalance) into “Active FLOPs” to check whether the proposed axis remains predictive under real hardware constraints.
- Report training wall-clock, throughput, instability events, and reproducibility across parallelization strategies (tensor/expert/pipeline) since MoE topology may alter optimization dynamics at fixed FLOPs.
- Baselines and calibration of scaling laws:
- Include dense baselines trained under identical corpora and compute budgets to quantify absolute gains/losses from MoE sparsity for both memorization and reasoning.
- Fit explicit scaling-law models (including loss-to-loss mappings) for MoE that incorporate active FLOPs and TPP, and test predictive accuracy out-of-sample.
- Threshold prediction and diagnostics:
- Develop diagnostic metrics (e.g., router entropy, effective rank, validation-on-synthetic families) to predict when additional experts will push reasoning into the inverse-scaling regime.
- Characterize uncertainty (confidence intervals, multi-seed runs) for all curves to distinguish genuine inverse-U effects from variance at small test set sizes (e.g., GSM8K, HumanEval).
- Data mixture sensitivity:
- Systematically vary the pre-training mixture (proportions of math, code, and general web) at fixed compute to see how the optimal sparsity/density shifts with domain emphasis.
- For code ablations, decouple architectural effects from data effects by keeping the corpus constant across sparsity settings and reporting TPP and Active FLOPs consistently.
- Evaluation methodology:
- Complement “answer-token cross-entropy” with process-sensitive metrics (reasoning step accuracy, verifier pass rates) to better capture reasoning quality vs final-answer accuracy.
- Assess long-context effects by varying sequence length in pre-training and evaluation; reasoning performance may depend on context size, not only sparsity and TPP.
- Prescriptive guidance is incomplete:
- Translate the two-axes insight (Active FLOPs, TPP) into a practical optimization recipe: given a compute and data budget, compute k and E that optimize reasoning while satisfying system constraints; validate the prescribed recipe prospectively.
Collections
Sign up for free to add this paper to one or more collections.