- The paper introduces a modular PyTorch framework, pyFAST, that decouples data processing from model computation to flexibly manage heterogeneous and irregular time series data.
- It implements dynamic batch-level padding and transformer-inspired, alignment-free fusion techniques to support efficient imputation and forecasting.
- The framework promotes rapid prototyping, reproducible research, and scalable benchmarking across diverse domains such as healthcare and bioinformatics.
pyFAST: A Modular PyTorch Framework for Time Series Modeling with Multi-source and Sparse Data
Motivation and Design Principles
pyFAST is introduced as a research-oriented PyTorch framework specifically engineered to address the limitations of existing time series libraries in handling multi-source, irregular, and sparse data. The framework is built on a strict modular architecture, decoupling data processing from model computation to facilitate rapid prototyping and extensibility. This separation is critical for reproducible research and for supporting complex real-world scenarios where data heterogeneity and missingness are prevalent.
The design is organized into three principal layers: Interfaces and Applications, Packages and Features, and Infrastructures. This layered approach ensures that each component—data handling, modeling, and training utilities—can be independently extended or replaced, promoting flexibility and maintainability.
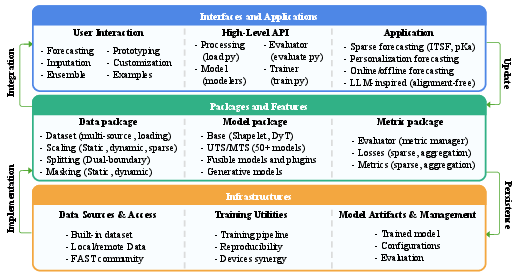
Figure 1: Architectural overview of the pyFAST library, illustrating the separation of interfaces, packages, and infrastructure for modular extensibility.
Data Handling Innovations
A central contribution of pyFAST is its Data package, which provides advanced capabilities for loading, normalizing, and integrating multi-source datasets without requiring temporal alignment. Each data stream is tokenized independently and assigned source-specific identifiers, enabling downstream models to learn cross-modal relationships in an alignment-free manner. This is particularly advantageous for domains such as healthcare, energy, and bioinformatics, where asynchronous and heterogeneous data sources are common.
Dynamic sequence- and patch-level padding is performed at the batch level, reducing memory overhead and preprocessing time compared to static approaches. The framework supports high-throughput processing of variable-length sequences, including protein sequences, and implements mask-based modeling strategies for both imputation and forecasting. These tensor-based operations are optimized for scalability and efficiency, leveraging PyTorch’s native capabilities.
Model Library and LLM-inspired Architectures
pyFAST provides a comprehensive suite of models, ranging from classical statistical baselines to state-of-the-art deep learning architectures, including CNNs, RNNs, Transformers, and GNNs. The Base submodule offers reusable components such as shapelet layers, time series decomposition methods, and DyT, enabling the construction of novel architectures with minimal boilerplate.
A notable feature is the integration of LLM-inspired architectures for alignment-free fusion of sparse data sources. These models adapt transformer-based mechanisms to handle multi-source inputs, learning relationships across modalities without explicit temporal alignment. This approach is particularly effective for scenarios with missing or irregular data, where traditional models struggle to generalize.
Training Utilities and Evaluation
The Training Utilities package streamlines the experimental workflow with automated training loops, checkpointing, early stopping, and learning rate scheduling. The metric module includes both standard and sparse metrics, tailored for evaluation in the presence of missing data. The Evaluator class implements batch-based stream aggregation, enabling robust evaluation on large datasets that cannot fit into main memory. This streaming approach computes metrics on-the-fly, supporting scalable benchmarking and reproducible research.
pyFAST is accompanied by a curated suite of benchmark datasets, further promoting systematic comparison and reproducibility in time series research.
Comparative Analysis
Compared to existing libraries such as GluonTS, PyTorch Forecasting, sktime, and TSLib, pyFAST distinguishes itself through its explicit data–model decoupling, native support for sparse and multi-source data, and integration of LLM-inspired architectures. While other frameworks excel in specific domains—probabilistic forecasting, interpretability, or efficiency—pyFAST is uniquely positioned for research-centric applications involving heterogeneous and irregular data.
Key differentiators include:
- Modularity and Extensibility: Component-based design allows easy addition of custom models and data pipelines.
- Alignment-free Multi-source Fusion: Transformer-based models natively support asynchronous data integration.
- Sparse Data Support: Dedicated metrics and loss functions for sparse scenarios.
- Dynamic Padding and Normalization: Efficient batch-wise operations for variable-length sequences.
- Benchmarking Suite: Standardized evaluation framework for reproducible research.
Practical and Theoretical Implications
Practically, pyFAST enables rapid experimentation and deployment of advanced time series models in domains characterized by data heterogeneity and missingness. Its modularity supports agile development and systematic benchmarking, accelerating the research cycle. The alignment-free fusion mechanisms and sparse data support are particularly relevant for healthcare, energy, and bioinformatics, where data irregularity is the norm.
Theoretically, the framework’s decoupling of data and model computation provides a clean abstraction for investigating novel modeling strategies, including cross-modal and multi-source learning. The integration of LLM-inspired architectures opens avenues for research into alignment-free representation learning and imputation in time series, potentially informing future developments in multi-modal AI.
Future Directions
Potential future developments include:
- Extension of LLM-inspired architectures to more complex multi-modal fusion tasks.
- Integration with distributed training and inference pipelines for large-scale industrial applications.
- Expansion of the benchmarking suite to cover emerging datasets and tasks in time series analysis.
- Development of automated model selection and hyperparameter optimization modules leveraging the modular design.
Conclusion
pyFAST establishes a modular, extensible, and efficient platform for time series modeling, with explicit support for multi-source, sparse, and irregular data. Its separation of data processing and model computation, combined with a rich model library and advanced training utilities, positions it as a robust tool for both applied and theoretical research in time series analysis. The framework’s innovations in alignment-free data fusion and sparse metric evaluation address critical gaps in the current ecosystem, enabling systematic and reproducible research across diverse scientific and industrial domains.