2000 character limit reached
The Subset Sum Matching Problem
Published 26 Aug 2025 in cs.AI | (2508.19218v1)
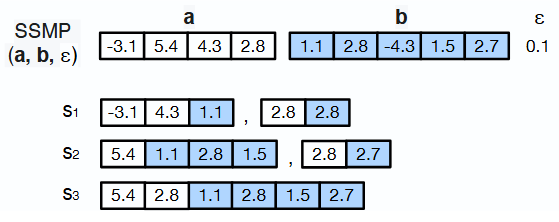
Abstract: This paper presents a new combinatorial optimisation task, the Subset Sum Matching Problem (SSMP), which is an abstraction of common financial applications such as trades reconciliation. We present three algorithms, two suboptimal and one optimal, to solve this problem. We also generate a benchmark to cover different instances of SSMP varying in complexity, and carry out an experimental evaluation to assess the performance of the approaches.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that, if addressed, could advance the understanding and practical applicability of SSMP/SMP.
- Formal properties of SMP beyond SSMP are largely unexplored:
- Complexity of the general SMP optimization problem (beyond the NP-completeness of the decision version) is not characterized.
- Classes of validation functions for which SMP becomes tractable (poly-time) or admits efficient approximations or FPT algorithms are not identified.
- Objective design for SSMP is under-specified:
- The current objective is ad hoc (counts matched elements plus number of matches) and lacks theoretical justification; no comparison to alternatives (e.g., penalizing large match sizes, residual differences, or using weighted coverage).
- The impact of scaling the term or introducing tunable weights is not analyzed; no guidance on how to set these weights for reconciliation use-cases.
- No approximation guarantees or bounds are provided for the greedy construction relative to the objective .
- MILP formulation details and scalability:
- The absolute value constraint is not linearized; the exact linearization (auxiliary variables and big-M constants or equivalent) and numerical settings used in CPLEX are not documented.
- No symmetry-breaking constraints or model-strengthening cuts are proposed; potential performance gains remain unexplored.
- Memory usage, node counts, and gap evolution for MILP are not reported, hindering diagnosis of solver bottlenecks.
- Reasons for MILP performance degradation at small (e.g., numerical precision vs. combinatorial hardness) are not analyzed.
- Suboptimal greedy framework lacks decision policy:
- The Solve-based greedy loop has no tie-breaking or prioritization heuristics aligned with (e.g., preferring smaller, fine-grained matches or higher marginal gain).
- No analysis of how early match choices affect global optimality; no local-search or lookahead variants are evaluated.
- Search solver design and tuning:
- The choice of split parameter is only justified for and ; there is no analysis for or for (symmetric cases), nor adaptive strategies for tuning.
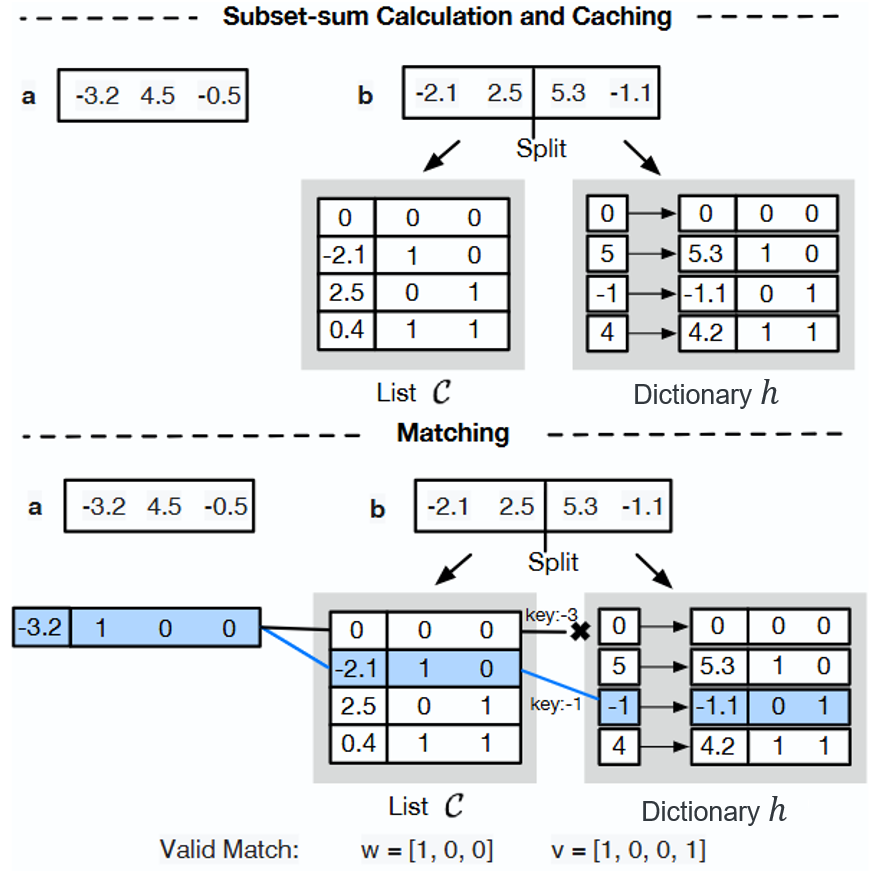
- Precision handling for real-valued inputs (impact of significant digits on associative array bucket sizes and collision rates) is discussed informally but not formalized or quantified.
- No comparison against state-of-the-art meet-in-the-middle variants (e.g., Schroeppel–Shamir) or other space–time trade-off algorithms.
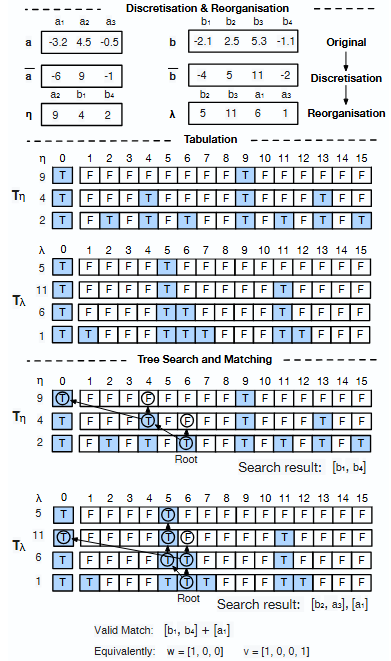
- DP solver correctness and error control:
- For real-valued inputs, the discretization scale and threshold are chosen heuristically; there are no formal bounds on false positives/negatives induced by rounding.
- The converse mapping (from integer proxy back to real problem) is known to be invalid in general, but the expected number of spurious candidate matches and its impact on runtime is not quantified.
- For mixed sign data, the reorganization into is justified, but the effect on table size and the resulting complexity in realistic distributions is not analyzed.
- Memory usage of DP tables () is not measured; practical limits as grows with value ranges are missing.
- Theoretical guarantees and parameterized complexity:
- No approximation ratios or inapproximability results are provided for the SSMP optimization problem under (or other objectives).
- Parameterized complexity (e.g., parameterizing by , solution size , maximum match size, value range , or precision) is not investigated.
- Kernelization or FPT strategies (e.g., bounding subset sizes or using conflict constraints) are not explored.
- Problem structure and constraints for reconciliation:
- Domain-specific constraints (e.g., date windows, counterparties, transaction metadata consistency, one-to-many limits, excluded pairs) are not modeled; their effect on tractability and solver performance is unknown.
- A global is assumed; per-record or context-dependent tolerances and their modeling (soft constraints with penalties vs. hard thresholds) are not considered.
- Integration with attribute/text-based matching is left out; frameworks to jointly or sequentially combine amount-based SSMP with metadata matching are not proposed.
- Benchmarking and evaluation limitations:
- Benchmarks are synthetic (i.i.d. uniform) and may not reflect heavy tails, duplicates, and correlations common in financial data; no real-world datasets are used.
- The benchmark is claimed reusable, but there is no artifact link, code repository, or dataset specification to ensure reproducibility.
- Optimality gaps for MILP (when timeouts occur) are not reported; DP “exactness” in real-valued cases is not validated against known optima.
- Memory consumption across methods (search cache size, DP table footprint, MILP model size) is not measured, limiting practical guidance.
- Sensitivity analyses (varying , , , value ranges, duplicates) are limited; no ablation studies guide parameter selection.
- Scalability and parallelization:
- Methods are evaluated up to ; performance on larger reconciliation workloads (thousands to tens of thousands of records) is not assessed.
- Parallelization opportunities (e.g., subset sum enumeration, DP table row-level parallelism, MILP solver parallel tuning) are not explored.
- Extensions of the SSMP model:
- Multi-objective formulations (e.g., trade-off between coverage, match granularity, and residual difference) are not investigated.
- Soft constraints (penalized deviations) vs. hard threshold are not compared; robust or stochastic variants (uncertain amounts) are not considered.
- Match-size constraints (e.g., cap the number of elements per match) and fairness/regularization terms are not studied.
- Generalizations to multi-set matching across more than two lists (multi-ledger reconciliation) are not modeled.
- Practical deployment questions:
- Strategies for adaptive calibration from historical data (and its effect on false match rates) are not provided.
- Error handling for zero-valued records (MILP assumes non-zero real numbers) and currency/precision normalization across ledgers is not discussed.
- Post-hoc validation pipelines (human-in-the-loop review, auditability, explanation of matches) and metrics (precision/recall vs. ) are not defined.
Collections
Sign up for free to add this paper to one or more collections.