- The paper demonstrates that traditional readability metrics, such as FKGL with a Pearson correlation of 0.16, poorly align with human judgments compared to LM-based evaluations.
- Researchers systematically compared 8 traditional metrics and 5 large language models using a dataset of 60 scientific summaries to highlight critical evaluation gaps.
- The study advocates integrating LM-based evaluators and developing novel metrics to better capture comprehensive readability in plain language summarization.
Evaluating the Evaluators: Are Readability Metrics Good Measures of Readability?
Introduction and Motivation
This work critically examines the validity of traditional readability metrics as evaluators for Plain Language Summarization (PLS), a task that aims to distill complex scientific or technical documents into accessible summaries for non-expert audiences. The authors identify a disconnect between the widespread use of legacy readability formulas—such as Flesch-Kincaid Grade Level (FKGL)—and their actual alignment with human judgments of readability in the PLS context. The study further investigates whether large LMs can serve as more reliable evaluators, given their demonstrated capacity for nuanced language understanding.
Survey of Current Evaluation Practices
A comprehensive literature survey of PLS research published in ACL venues from 2013 to 2025 reveals that the field predominantly relies on a small set of traditional readability metrics, with FKGL being the most frequently used, followed by the Coleman-Liau Index (CLI) and Dale-Chall Readability Score (DCRS). LM-based evaluation remains rare, despite the increasing popularity of PLS and the growing number of shared task participants.
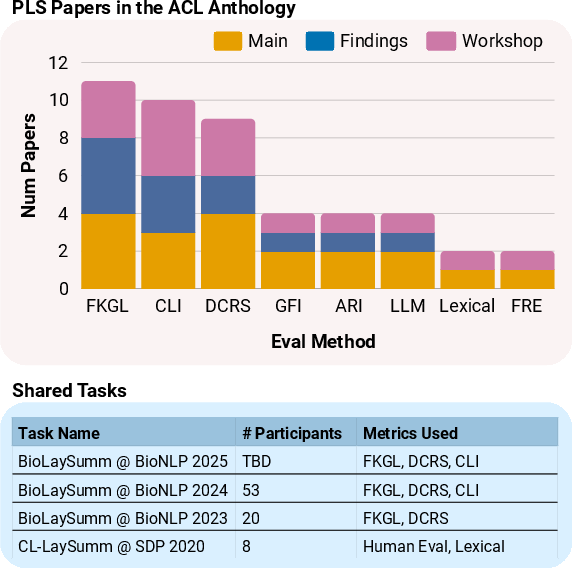
Figure 1: Distribution of evaluation metrics used in ACL Anthology PLS papers, highlighting the dominance of FKGL and the limited adoption of LM-based evaluation.
This reliance on traditional metrics is notable given their origins in educational and legal domains, rather than in the context of scientific communication to lay audiences.
Empirical Correlation with Human Judgments
The core empirical contribution is a systematic comparison of eight traditional readability metrics and five LMs against human-annotated readability judgments on a dataset of 60 scientific summaries. The metrics evaluated include FKGL, CLI, DCRS, Gunning Fog Index (GFI), Automated Readability Index (ARI), Flesch Reading Ease (FRE), Spache, and Linsear Write (LW).
The results demonstrate that six out of eight traditional metrics exhibit Pearson correlations below 0.3 with human judgments. Notably, FKGL, the most popular metric, achieves only 0.16 Pearson and 0.08 Kendall-Tau correlation, indicating minimal alignment with human perception of readability. DCRS and CLI perform best among traditional metrics but still fall short of robust correlation.
In contrast, all five LMs tested (Mistral 7B, Mixtral 7B, Gemma 7B, Llama 3.1 8B, Llama 3.3 70B) outperform traditional metrics, with the best model (Llama 3.3 70B) achieving a Pearson correlation of 0.56. This is a substantial improvement, suggesting that LMs capture aspects of readability that are missed by surface-level lexical proxies.

Figure 2: The best-performing prompt for LM-based readability evaluation, which yields the highest correlation with human judgments.
Qualitative Analysis and Model Reasoning
The study provides qualitative evidence that LMs, when prompted appropriately, reason about readability in a manner more consistent with human annotators. For example, LMs recognize the importance of defining technical terms, providing context, and explaining motivation—attributes that are not captured by traditional metrics, which focus on sentence length, word length, and word familiarity.
A keyword analysis of LM-generated rationales reveals that low-scoring summaries are associated with terms like "expert background knowledge" and "specialized terms," while high-scoring summaries are linked to "explanations for the non-expert" and "accessible concepts."

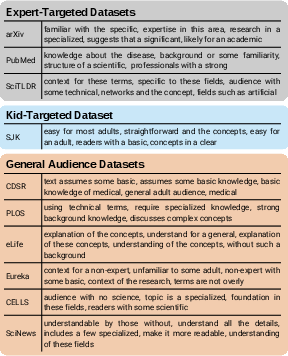
Figure 3: (a) Keywords in LM rationales stratified by score; (b) Keywords stratified by dataset, illustrating the LM's sensitivity to audience and content.
Dataset-Level Evaluation and Metric Disagreement
The authors extend their analysis to ten scientific summarization datasets, spanning expert-, kid-, and general-audience targets. LM-based evaluation reveals that some datasets commonly used for PLS (e.g., PLOS, CELLS) are rated as similarly unreadable as expert-targeted datasets (arXiv, PubMed), challenging their suitability for PLS research. In contrast, datasets like CDSR and SciNews receive high readability scores, aligning with their intended audience.
A direct comparison between LM-based and FKGL-based rankings of datasets exposes substantial disagreement. For instance, FKGL ranks arXiv as the second most readable dataset, whereas the LM evaluator ranks it last, highlighting the risk of drawing misleading conclusions from traditional metrics.
Theoretical and Practical Implications
The findings indicate that traditional readability metrics suffer from both definitional inconsistency and measurement error in the PLS context. Their definitions of readability are rooted in educational grade-level appropriateness, not in the accessibility of scientific content for non-experts. Moreover, their reliance on shallow lexical features makes them vulnerable to manipulation and blind to deeper aspects of comprehension.
LMs, by contrast, demonstrate the ability to reason about background knowledge requirements, conceptual clarity, and explanatory adequacy. However, the authors caution that LMs are not a panacea: they are subject to bias, lack interpretability, and may not generalize across domains or languages.
Recommendations and Future Directions
The authors recommend discontinuing the use of FKGL for PLS evaluation and suggest DCRS and CLI as preferable among traditional metrics, though with caveats. They advocate for the integration of LM-based evaluators, especially for qualitative analysis and dataset selection, but emphasize the need for multi-faceted evaluation strategies.
Future research should focus on developing new metrics that are both theoretically aligned with human definitions of readability and empirically validated against human judgments. There is also a need for more diverse, high-quality datasets and for interpretability methods that can elucidate LM-based evaluations.
Conclusion
This study provides compelling evidence that traditional readability metrics are inadequate for evaluating plain language summaries in scientific communication. LM-based evaluators, when properly prompted, offer a more reliable and nuanced assessment, but their adoption should be accompanied by careful consideration of their limitations. The work calls for a paradigm shift in PLS evaluation practices and sets the stage for the development of more robust, human-aligned metrics for readability in NLP.