- The paper demonstrates that integrating diverse multilingual datasets significantly improves the detection robustness compared to a single-dataset approach.
- It employs self-supervised learning models with an AASIST backend to capture critical spectral and temporal features of deepfake audio.
- Results indicate notable performance gains in unmodified and processed speech detection while highlighting ongoing challenges with laundered audio.
Multilingual Dataset Integration Strategies for Robust Audio Deepfake Detection
Introduction
The paper focuses on enhancing audio deepfake detection through the integration of multilingual datasets, employing self-supervised learning (SSL) to improve robustness against various spoofing challenges. The research tackles the pressing need for deepfake detection systems that can adapt to a diverse range of synthetic speech generated from numerous text-to-speech (TTS) systems under varying conditions. The methodology is benchmarked using the SAFE Challenge, which evaluates synthetic speech detection across three key tasks, emphasizing real-world applicability and system generalization.
SAFE Challenge and Key Contributions
The SAFE Challenge offers three tasks: detection of unmodified synthetic speech, detection of processed audio with artifacts, and detection of laundered audio designed to evade conventional systems. The paper utilizes SSL models integrated with an AASIST backend to enhance deepfake detection. By leveraging datasets such as ASVspoof, MLAAD, and SpoofCeleb, the system achieves notable recognition in multilingual settings, addressing the challenge of training models that generalize across languages and processing conditions.
Dataset Integration Strategy
The core concept revolves around combining datasets with varying characteristics to boost the generalization of detection systems. A strategic analysis of TTS system coverage across datasets was conducted, highlighting complementarity and gaps. The iterative experimental design demonstrated significant improvements over a single-dataset baseline. By progressively integrating datasets with complementary attributes, the system achieves a balanced representation of real and fake audio samples across tasks.
Through four iterations, the dataset coverage and audio segment length were optimized. Important milestones included moving from a single-dataset approach to a multi-dataset integration, optimizing audio lengths for better temporal context, and refining dataset selection based on technology complementarity.
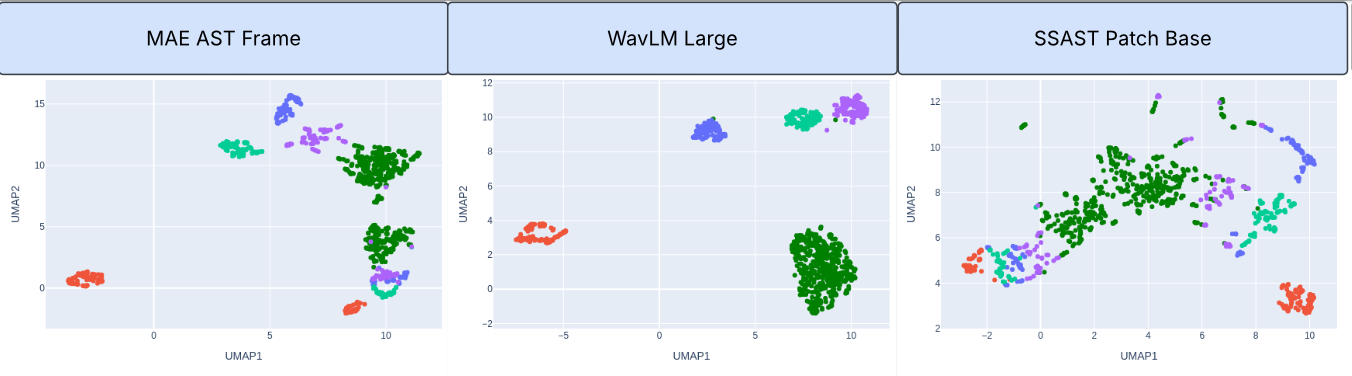
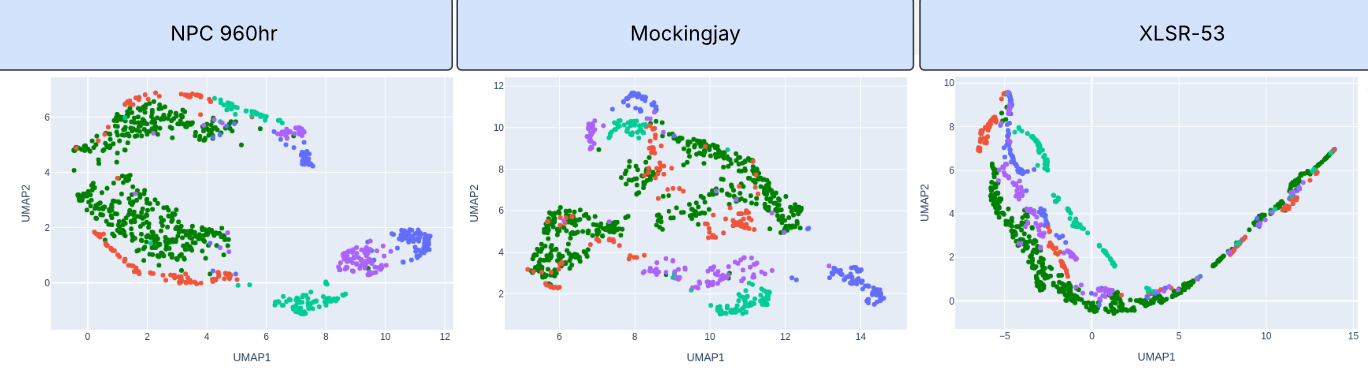
Figure 1: UMAP visualizations of SSL model representations for ASVSpoof 2019 LA eval data. Top: Comparison of MAE AST Frame, WavLM Large, and SSAST Patch Base models. Bottom: Additional SSL model comparisons including NPC 960hr, Mockingjay, and XLSR-53. Green color represents bonafide, other colors represent various deepfakes.
Self-Supervised Learning Model Selection
The SSL front-ends, including WavLM Large and MAE-AST Frame, were assessed for their effectiveness in identifying deepfake features. The AASIST backend was instrumental in mapping spectral and temporal artifacts critical for spoofing detection. The adoption of SSL allowed for the effective utilization of large unlabeled audio corpora in learning robust feature representations, which were tuned to detect deepfakes across different scenarios.
Results and Analysis
The research highlights significant performance improvements through dataset diversification and strategic SSL integration. Balanced accuracy improvements in Tasks 1 and 2 of the SAFE Challenge were notable. However, Task 3 pertaining to laundered audio remains challenging, suggesting a need for ongoing exploration into more sophisticated laundering detection techniques. Source-level analysis identified specific areas for system enhancement and highlighted particular synthesized audio sources and real-world recordings that are difficult for current systems to accurately classify.
Implications and Future Directions
The presented methodologies demonstrate significant strides in audio deepfake detection, showcasing how dataset diversity and SSL can be leveraged to enhance system robustness. However, challenges remain, particularly in identifying sophisticated laundering attacks. Future work could explore advanced SSL architectures and integrate adversarial techniques to bolster system defenses against evolving deepfake threats.
The research underscores the necessity for adaptive spoofing detection frameworks capable of handling burgeoning TTS technologies. Future research and development will need to focus on maintaining an up-to-date understanding of TTS advancements and synthesizing these learnings into training and evaluation protocols.
Conclusion
The integration of multilingual and diverse datasets, combined with SSL methodologies, represents a significant advancement in audio deepfake detection. While notable progress is highlighted, particularly against unmodified and processed synthetic audio, ongoing challenges with laundered audio indicate areas for further investigation. Future research should continue to explore innovative approaches to bolster detection across the evolving landscape of deepfake audio technology.