- The paper introduces CAAAv2, a novel pipeline leveraging web-sourced forged images and auto-annotation to construct the vast MIMLv2 dataset for image manipulation localization.
- The method distinguishes SPG and SDG pairs using self-supervised classification paired with DASS and Correlation DINO for precise segmentation.
- Empirical results show that the Web-IML model, enhanced by Object Jitter and multi-scale perception, outperforms previous approaches with significant IoU gains and robustness.
Webly-Supervised Image Manipulation Localization via Category-Aware Auto-Annotation
Introduction and Motivation
The paper addresses the persistent challenge of data scarcity in Image Manipulation Localization (IML), a critical task for image forensics. Existing datasets are limited in scale and diversity, leading to overfitting and poor generalization in deep models. The authors propose leveraging abundant manually forged images from the web, combined with automatic pixel-level annotation via a novel Constrained Image Manipulation Localization (CIML) paradigm, termed Category-Aware Auto-Annotation v2 (CAAAv2). This approach enables the construction of a large-scale, high-quality dataset (MIMLv2) and the development of robust IML models.
Category-Aware Auto-Annotation v2 (CAAAv2)
CAAAv2 introduces a bifurcated processing pipeline for image pairs, distinguishing between Shared Probe Group (SPG) and Shared Donor Group (SDG) pairs. SPG pairs involve direct modification of the original image, while SDG pairs involve copy-pasting foreground objects.
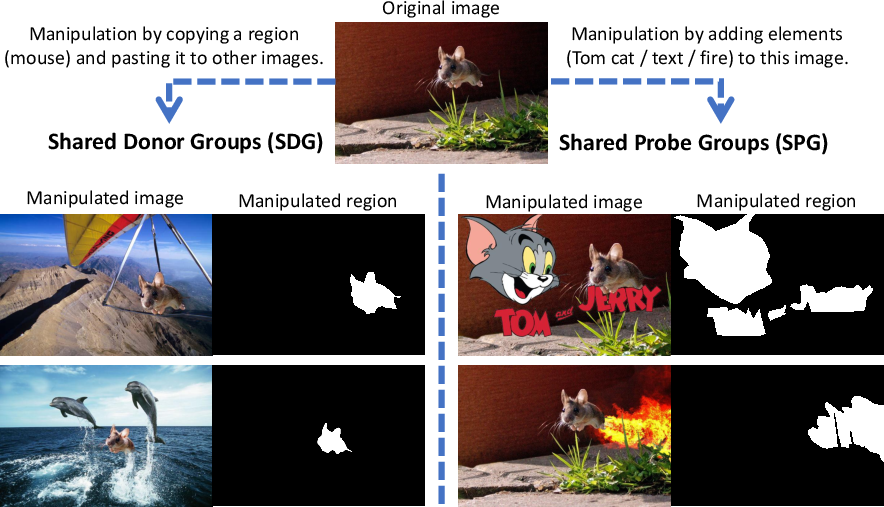
Figure 1: SPG and SDG categorization based on manipulation type; SPG involves direct modification, SDG involves copy-paste of foreground objects.
The pipeline first classifies image pairs into SPG or SDG using a self-supervised classifier. SPG pairs are processed with Difference-Aware Semantic Segmentation (DASS), leveraging both the image pair and their difference map for robust localization. SDG pairs are handled by Correlation DINO, which employs a frozen DINOv2 ViT backbone, learnable aggregation, feature super-resolution, and multi-aspect denoising to mitigate overfitting and enhance generalization.
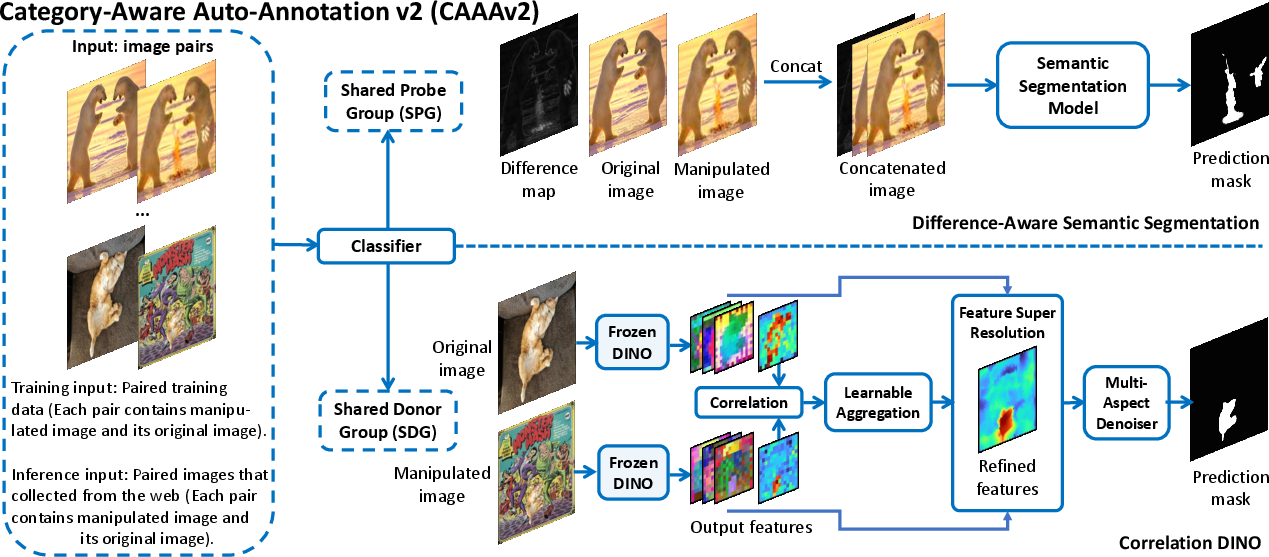
Figure 2: CAAAv2 pipeline: classifier separates SPG/SDG, followed by DASS for SPG and Correlation DINO for SDG.
The frozen-denoising paradigm in Correlation DINO is critical for SDG, where overfitting is prevalent due to limited training data and high visual complexity. The frozen backbone preserves general representations, while the denoising modules refine correlation features for accurate mask prediction.
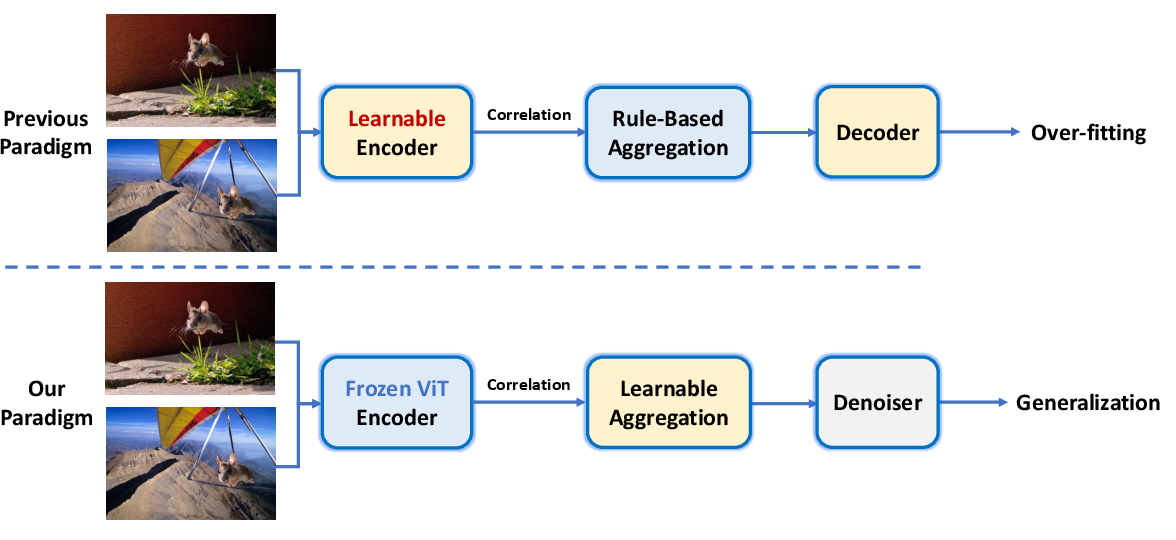
Figure 3: Frozen-denoising paradigm for SDG pairs, improving generalization over prior learnable encoder approaches.
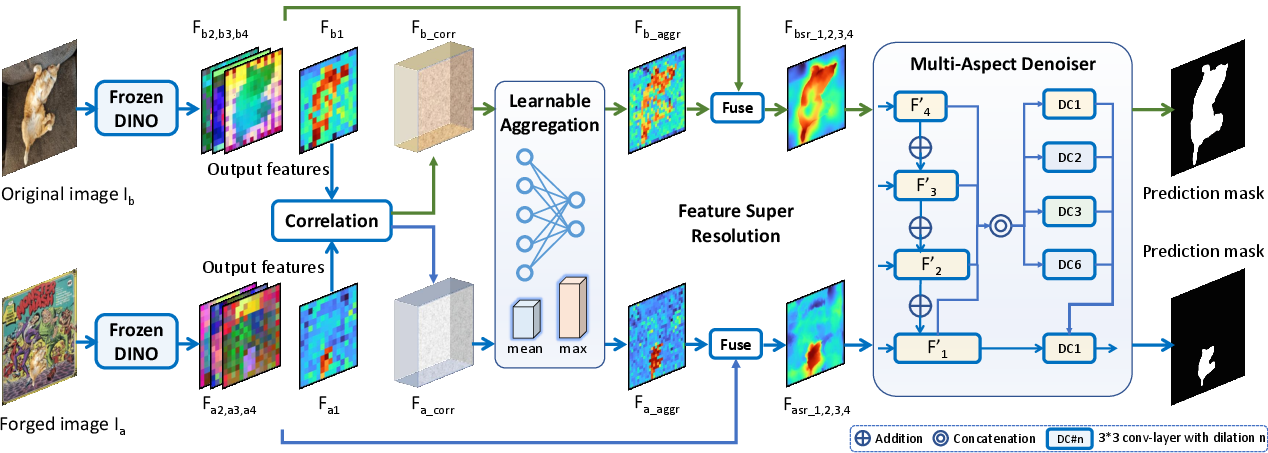
Figure 4: Correlation DINO architecture: frozen DINO backbone, correlation calculation, learnable aggregation, feature super-resolution, and multi-aspect denoising.
MIMLv2 Dataset Construction
The MIMLv2 dataset is constructed by collecting manually forged images and their originals from the web (e.g., imgur.com), followed by automatic annotation using CAAAv2. To ensure annotation quality, the Quality Evaluation Score (QES) metric filters unreliable masks based on confidence and edge sharpness.
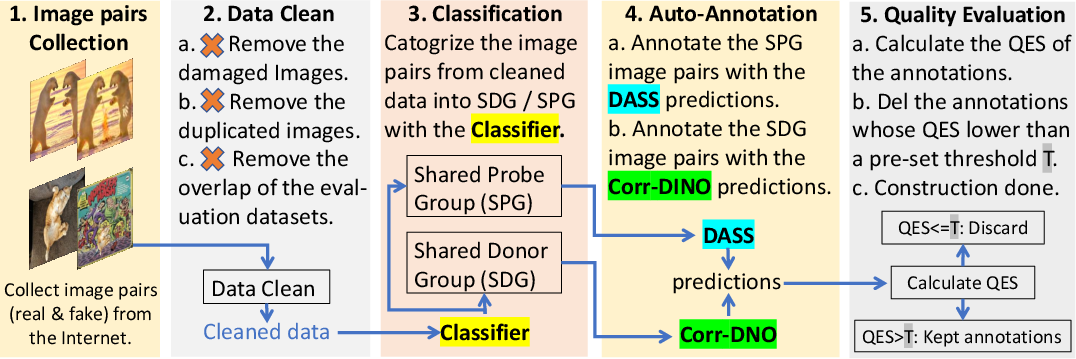
Figure 5: MIMLv2 dataset construction pipeline: web image collection, CAAAv2 annotation, QES filtering.
MIMLv2 comprises 246,212 manually forged images, over 120× larger than previous datasets (e.g., IMD20). It features high-quality, diverse, and modern manipulations, supporting robust model training and generalization.

Figure 6: Example images and mask annotations from MIMLv2; left: SPG pairs, right: SDG pairs.
Object Jitter: Data Augmentation for Realism
Object Jitter is introduced to further enhance data diversity and realism. Unlike prior synthetic methods that produce obvious artifacts, Object Jitter applies subtle distortions (size, exposure, texture) to randomly selected objects in authentic images, preserving semantic integrity and generating unobvious artifacts.

Figure 7: Comparison of data generation methods; Object Jitter produces semantically reasonable forgeries.

Figure 8: Object Jitter operations: enlargement, overexposure, texture alteration on segmented objects.
This method is universally applicable and supplements MIMLv2 with high-quality, diverse samples, improving model robustness to real-world manipulations.
Web-IML Model Architecture
To fully exploit web-scale supervision, the Web-IML model is proposed. It consists of a ConvNeXt-Base encoder, a Multi-Scale Perception module for integrating features across scales, and a Self-Rectification module for iterative error correction. The Nested Channel Attention mechanism enables in-depth analysis of suspected tampered regions.
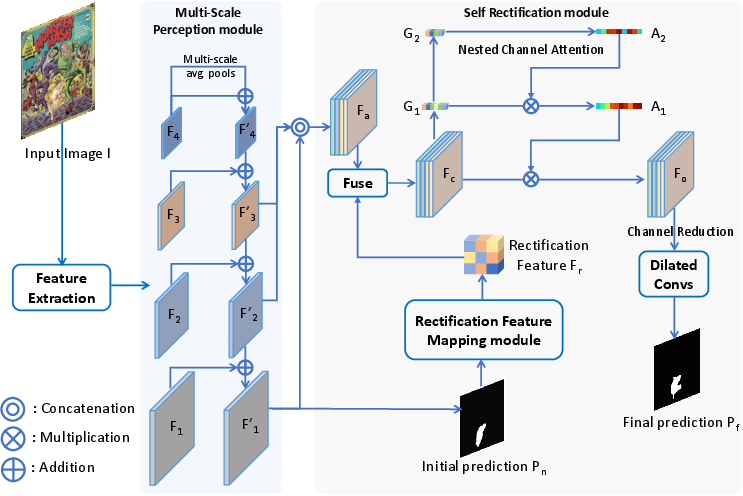
Figure 9: Web-IML framework: encoder, multi-scale perception, self-rectification, and nested channel attention.
The model is optimized with cross-entropy loss and demonstrates strong performance and robustness across multiple benchmarks.
Experimental Results
Web-IML, trained with MIMLv2 and Object Jitter, achieves substantial improvements over prior state-of-the-art methods. Notably, it surpasses TruFor by 24.1 average IoU points and achieves a 31% performance gain with web supervision. Ablation studies confirm the effectiveness of each architectural component and data augmentation strategy.
Robustness
Web-IML maintains stable performance under various image distortions (resizing, blurring, JPEG compression), indicating strong robustness.
Downstream Applicability
Fine-tuning Web-IML on document IML tasks (SACP benchmark) yields significant improvements, demonstrating universal applicability and transferability of web-supervised features.
Implications and Future Directions
The proposed framework shifts the paradigm in IML from reliance on limited handcrafted datasets to scalable, continuously growing web resources. The CAAAv2 annotation pipeline, combined with QES filtering and Object Jitter augmentation, enables the construction of large, diverse, and high-quality datasets. The Web-IML model architecture is well-suited for leveraging such data, achieving strong generalization and robustness.
The approach is readily extensible: as new manually forged images emerge online, the dataset and models can be continuously updated. This scalability is critical for keeping pace with evolving manipulation techniques and maintaining forensic efficacy.
Conclusion
The paper presents a comprehensive solution to data scarcity in image manipulation localization by leveraging web-scale manually forged images, automatic category-aware annotation, and advanced data augmentation. The resulting MIMLv2 dataset and Web-IML model set new benchmarks in performance and generalization. The methodology is universally applicable and establishes a scalable framework for future developments in image forensics.

Figure 10: Qualitative comparison of image manipulation localization results across models and datasets.