- The paper introduces a diffusion-based framework that generates high-resolution, temporally consistent 24 FPS virtual try-on videos.
- The CondNet architecture unifies multi-modal inputs via cross-attention, enabling robust garment transfer and precise motion fidelity.
- Progressive training with curriculum learning and video refinement yields superior quantitative metrics, outperforming existing methods.
Dress&Dance: High-Resolution Video Virtual Try-On with Controllable Motion
Introduction
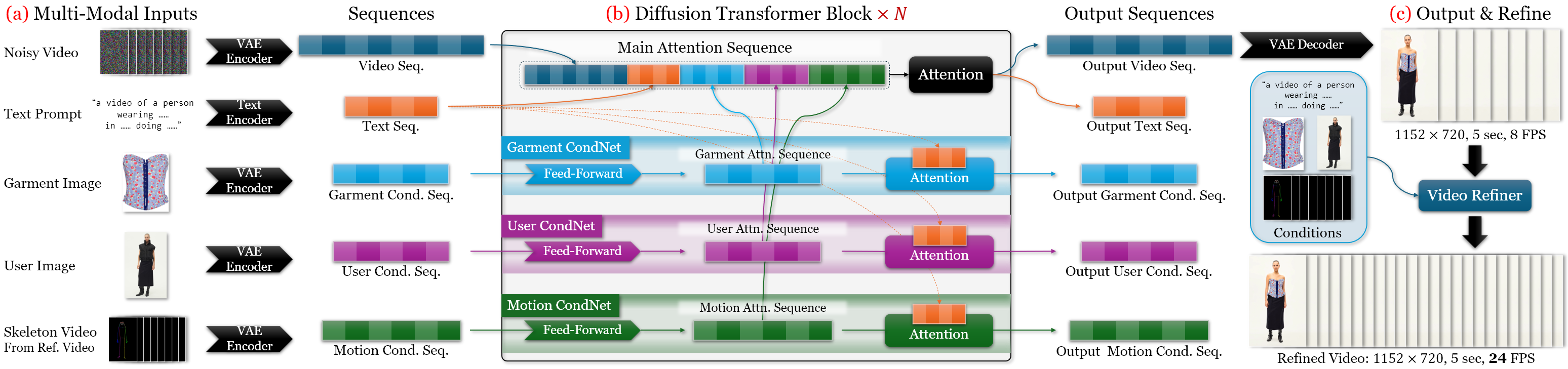
The "Dress&Dance" framework introduces a video diffusion-based approach for high-fidelity, temporally consistent virtual try-on, enabling users to visualize themselves wearing arbitrary garments while performing user-specified motions. Unlike prior methods that are limited to static images or short, low-resolution video outputs, this system generates 5-second, 24 FPS videos at 1152×720 resolution, supporting a wide range of garment types and combinations. The core innovation is the CondNet architecture, which unifies multi-modal conditioning (text, images, videos) via cross-attention, facilitating robust garment registration and motion fidelity. The system is trained with a data- and compute-efficient curriculum, leveraging both synthetic and real paired data.

Figure 1: Dress&Dance enables complicated dancing motions, simultaneous try-on of top and bottom garments, and garment transfer from other users.
Methodology
Unified Multi-Modal Conditioning with CondNet
The central technical contribution is CondNet, an attention-based conditioning network that encodes heterogeneous inputs—user image, garment images, reference motion video, and optional text—into a unified token sequence. This sequence is concatenated with the diffusion model's latent sequence, enabling cross-attention to all modalities. This design allows the model to:
Progressive Training and Data Synthesis
To address the scarcity of paired video try-on data, the authors synthesize unpaired triplets (user, garment, motion) and employ a multi-stage progressive training strategy:
- Garment Warm-Up (Curriculum Learning): The model first learns coarse garment registration at low resolution.
- Progressive Resolution Training: The resolution and conditioning complexity are gradually increased, stabilizing convergence and improving fidelity.
- Video Refinement: An auto-regressive refiner upsamples the initial 8-FPS output to 24-FPS, enhancing visual quality and removing artifacts.
This approach eliminates the need for intermediate representations (e.g., agnostic masks, Dense Poses) and aligns training and inference conditions.
Experimental Results
Qualitative Analysis
Dress&Dance demonstrates superior garment and user appearance preservation, motion fidelity, and robustness to occlusions compared to both open-source and commercial baselines.

Figure 3: Given a user image, garment, and reference video, Dress&Dance extracts a detailed text description and generates temporally coherent try-on videos.

Figure 4: Garment transfer from another image is supported, with Dress&Dance producing high-resolution, detailed videos, outperforming Fashion-VDM.

Figure 5: Simultaneous try-on of top and bottom garments is achieved without explicit labeling, whereas Kling AI misclassifies garment types.

Figure 6: Dress&Dance outperforms existing video virtual try-on methods in texture detail and support for transparent garments.
Quantitative Analysis
On a captured dataset with ground truth, Dress&Dance achieves:
- PSNR: 22.41 (best among all methods)
- SSIM: 0.9038 (best)
- LPIPS (VGG): 0.2382 (best)
- LPIPS (AlexNet): 0.0624 (best)
On Internet-scale data, GPT-4-based evaluation scores for try-on fidelity, user appearance, motion, and visual quality are consistently higher than open-source baselines and competitive with commercial models (Kling, Ray2). Notably, Dress&Dance achieves the highest garment fidelity (GPT_Try-On: 87.41) and overall quality (GPT_Overall: 84.95).
Ablation Studies
Ablation experiments confirm that the curriculum-based garment warm-up and progressive training are essential for convergence and high-fidelity results. Direct training without these strategies leads to significant degradation in garment and user appearance preservation.
Practical and Theoretical Implications
Dress&Dance establishes a new state-of-the-art for video virtual try-on, particularly in:
- Resolution and Temporal Consistency: First to achieve 1152×720 at 24 FPS with temporally coherent garment and user appearance.
- Multi-Garment and Garment Transfer: Supports simultaneous try-on of multiple garments and garment transfer from arbitrary images, without explicit garment type annotation.
- Motion Control: Enables nuanced, user-specified motion via reference videos, overcoming the limitations of text-based motion description.
The CondNet architecture demonstrates the efficacy of unified cross-attention for multi-modal conditioning in generative video models, suggesting broader applicability to other conditional video synthesis tasks.
Limitations and Future Directions
While Dress&Dance achieves strong results, several limitations remain:
- Data Requirements: Despite synthetic triplet generation, high-quality results still depend on large-scale, diverse training data.
- Computational Cost: High-resolution video generation with attention-based diffusion models remains resource-intensive, though the progressive training mitigates this to some extent.
- Generalization: The model's ability to generalize to out-of-distribution garments, extreme poses, or complex backgrounds warrants further study.
Future work may explore more efficient architectures (e.g., sparse attention, token pruning), improved garment parsing and segmentation, and integration with real-time or interactive systems.
Conclusion
Dress&Dance advances the field of video virtual try-on by introducing a unified, high-resolution, and temporally consistent framework that supports flexible garment and motion conditioning. The CondNet architecture and progressive training pipeline enable robust garment registration, multi-modal input handling, and superior visual fidelity, outperforming both open-source and commercial baselines. This work sets a new benchmark for controllable, high-quality video-based virtual try-on and provides a foundation for future research in conditional video synthesis and human-centric generative modeling.