Fast and Scalable Mixed Precision Euclidean Distance Calculations Using GPU Tensor Cores
Published 28 Aug 2025 in cs.DC and cs.PF | (2508.21230v1)
Abstract: Modern GPUs are equipped with tensor cores (TCs) that are commonly used for matrix multiplication in artificial intelligence workloads. However, because they have high computational throughput, they can lead to significant performance gains in other algorithms if they can be successfully exploited. We examine using TCs to compute Euclidean distance calculations, which are used in many data analytics applications. Prior work has only investigated using 64 bit floating point (FP64) data for computation; however, TCs can operate on lower precision floating point data (i.e., 16 bit matrix multiplication and 32 bit accumulation), which we refer to as FP16-32. FP16-32 TC peak throughput is so high that TCs are easily starved of data. We propose a Fast and Scalable Tensor core Euclidean Distance (FaSTED) algorithm. To achieve high computational throughput, we design FaSTED for significant hierarchical reuse of data and maximize memory utilization at every level (global memory, shared memory, and registers). We apply FaSTED to the application of similarity searches, which typically employ an indexing data structure to eliminate superfluous Euclidean distance calculations. We compare to the state-of-the-art (SOTA) TC Euclidean distance algorithm in the literature that employs FP64, as well as to two single precision (FP32) CUDA core algorithms that both employ an index. We find that across four real-world high-dimensional datasets spanning 128-960 dimensions, the mixed-precision brute force approach achieves a speedup over the SOTA algorithms of 2.5-51x. We also quantify the accuracy loss of our mixed precision algorithm to be less than <0.06% when compared to the FP64 baseline.
The paper presents FaSTED, a mixed-precision algorithm that leverages FP16-32 GPU Tensor Cores to compute Euclidean distances at high throughput.
It reformulates distance computation into matrix operations, employing hierarchical data reuse and asynchronous memory transfers for efficiency.
The approach achieves up to 154 TFLOPS, outperforming state-of-the-art methods on both synthetic and real-world datasets with negligible accuracy loss.
Fast and Scalable Mixed Precision Euclidean Distance Calculations Using GPU Tensor Cores
Introduction and Motivation
The computation of Euclidean distances is a core operation in a wide range of data analytics and machine learning workloads, including similarity search, clustering, and outlier detection. The increasing dimensionality and scale of modern datasets have made the efficient calculation of these distances a significant computational bottleneck. While GPUs have long been leveraged for their parallelism, the advent of Tensor Cores (TCs) in modern NVIDIA GPUs has introduced new opportunities for accelerating matrix operations, particularly when using mixed-precision arithmetic. However, exploiting TCs for non-standard matrix operations, such as Euclidean distance calculations, presents unique challenges due to memory bandwidth limitations and the need for high data reuse.
This paper introduces FaSTED (Fast and Scalable Tensor core Euclidean Distance), a mixed-precision algorithm that leverages FP16-32 TCs to compute Euclidean distances at high throughput. The work systematically addresses the memory and data reuse bottlenecks that have limited the performance of prior approaches, and demonstrates substantial speedups over both TC-based and CUDA core-based state-of-the-art (SOTA) algorithms.
Algorithmic Design and Implementation
FaSTED is designed to maximize the utilization of FP16-32 TCs on NVIDIA A100 GPUs, which offer a peak throughput of 312 TFLOPS for FP16-32 operations. The algorithm targets the brute-force computation of all pairwise Euclidean distances in a dataset, a scenario with O(∣D∣2) complexity, but is also applicable as a subroutine in more complex analytics pipelines.
The core computational strategy is to reformulate the Euclidean distance calculation as a series of matrix operations amenable to TC acceleration. Specifically, the distance between two points pi and pj in d-dimensional space is computed as:
This formulation allows the use of TCs for the inner product term, with precomputed squared norms for the additive terms. The implementation leverages low-level PTX instructions for fine-grained control over memory access and register usage, as the higher-level WMMAAPI is insufficiently flexible for the required memory layouts and tile sizes.
Key optimizations include:
Hierarchical Data Reuse: Data is staged from global memory to shared memory and then to registers, with careful tiling to ensure each value is reused enough times to saturate TC throughput.
Asynchronous Memory Transfers: The use of cuda::memcpy_async and pipelined execution hides memory latency and reduces register pressure.
Bank-Conflict-Free Shared Memory Layouts: XOR-based swizzling ensures that shared memory accesses are fully coalesced and free of bank conflicts during TC fragment loading.
Block and Warp Tiling: The computation is organized into block tiles (128×128) and warp tiles (64×64), with multiple blocks per SM to maximize occupancy and hide instruction latency.
Performance Evaluation
Throughput Scaling with Dataset Size and Dimensionality
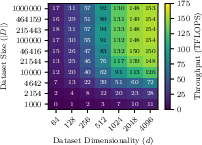
FaSTED achieves near-peak TC throughput with moderate dataset sizes and dimensionalities. The algorithm reaches 154 TFLOPS (49% of theoretical peak) on the A100 GPU for datasets with ∣D∣≥46,416 and d≥2048, with minimal sensitivity to further increases in size or dimensionality.
Figure 2: The number of TFLOPS achieved using FaSTED as a function of dataset size (∣D∣) and dimensionality (d) on the Synth class of datasets. The maximum throughput was 154 TFLOPS with a standard deviation of 0.02.
Comparison with Prior TC and CUDA Core Algorithms
FaSTED is compared against TED-Join-Brute (FP64, TC-based), TED-Join-Index (FP64, TC-based with index), GDS-Join (FP32, CUDA core-based), and MiSTIC (FP32, CUDA core-based). The results show that:
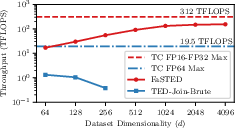
FaSTED outperforms TED-Join-Brute by up to an order of magnitude in TFLOPS, especially as dimensionality increases. TED-Join-Brute's performance degrades with higher d due to shared memory bank conflicts and WMMA API limitations, while FaSTED maintains high throughput.
Figure 4: Comparison of derived TFLOPS (log scale) for TED-Join-Brute (FP64) and FaSTED (FP16-32) as a function of data dimensionality, using the Synth dataset of size ∣D∣=105.
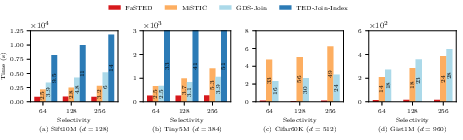
On real-world datasets (Sift10M, Tiny5M, Cifar60K, Gist1M), FaSTED achieves speedups of 2.5x–51x over SOTA index-supported algorithms, despite performing more distance calculations. The speedup increases with selectivity, as index-based methods lose their pruning advantage.
Figure 6: Comparison of FaSTED to SOTA GPU index-supported similarity search algorithms (MiSTIC, GDS-Join, TED-Join-Index) on four real-world datasets, showing total end-to-end response time.
Impact of Optimizations
A leave-one-out ablation study demonstrates that hierarchical tiling, asynchronous memory transfers, and bank-conflict-free shared memory layouts are all critical for achieving high throughput. Disabling any of these optimizations results in substantial performance degradation, with the warp tile optimization being the most impactful.
Numerical Accuracy
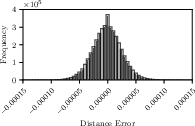
Despite using mixed precision (FP16-32), FaSTED exhibits negligible accuracy loss compared to FP64 baselines. The maximum observed accuracy loss is less than 0.06% in neighbor set overlap, and the mean error in computed distances is on the order of 10−6, with no measurable bias.
Figure 8: The distribution of the errors in the distance measurements for the Cifar60K dataset is shown.
Practical and Theoretical Implications
The results demonstrate that, with careful algorithmic and systems-level optimization, mixed-precision TCs can be effectively exploited for non-standard matrix operations such as Euclidean distance calculations. The approach is robust to dataset size and dimensionality, and the negligible accuracy loss makes it suitable for a wide range of analytics and machine learning applications.
The findings also highlight the limitations of current TC programming abstractions (e.g., WMMA API) for non-GEMM workloads, motivating further development of low-level programming techniques and hardware support for more flexible memory access patterns.
From a practical perspective, FaSTED enables brute-force similarity search and related operations at scales previously infeasible on a single GPU, obviating the need for complex indexing in high-selectivity or high-dimensional regimes. The approach is directly applicable to k-NN search, clustering, and other algorithms that rely on large-scale distance computations.
Future Directions
Potential avenues for future work include:
Integration with Indexing: Incorporating index structures to prune the search space while maintaining TC utilization could further improve performance for low-selectivity queries.
Hardware-Aware Scaling: Adapting the algorithm for multi-GPU and distributed environments, as well as for future GPU architectures with higher TC throughput and memory bandwidth.
Generalization to Other Metrics: Extending the approach to other distance metrics (e.g., cosine, Mahalanobis) and to non-Euclidean spaces.
Dynamic Precision Scaling: Investigating adaptive precision strategies to balance accuracy and performance based on dataset characteristics.
Conclusion
This work presents a comprehensive solution for high-throughput, mixed-precision Euclidean distance computation on GPU Tensor Cores. By addressing the key bottlenecks of memory bandwidth and data reuse, and by leveraging low-level hardware features, FaSTED achieves substantial speedups over existing methods with minimal accuracy loss. The approach sets a new standard for brute-force distance computation and provides a foundation for further advances in GPU-accelerated data analytics and machine learning.