- The paper demonstrates that a streamlined 3D CNN outperforms RNNs, delivering lower lap times on visually intricate tracks.
- The methodology integrates RGB-D sensing and systematic ablation to optimize model depth and control robustness.
- Findings indicate that reduced model complexity enhances generalization, making 3D CNNs ideal for resource-limited autonomous systems.
Mini Autonomous Car Driving via 3D Convolutional Neural Networks: Architecture and Comparative Analysis
Introduction
This paper presents a systematic study on mini autonomous car (MAC) driving using Three-Dimensional Convolutional Neural Networks (3D CNNs), positioning the approach against established Recurrent Neural Network (RNN) baselines. Leveraging simulated environments provided by DonkeyCar, the methodology emphasizes RGB-D sensing, architectural ablation, and rigorous evaluation on tracks with varying complexity. Primary contributions include empirical evidence that appropriately modified 3D CNNs outperform RNNs on visually intricate circuits, and a detailed ablation analysis showing that reducing unnecessary model depth increases system efficacy.
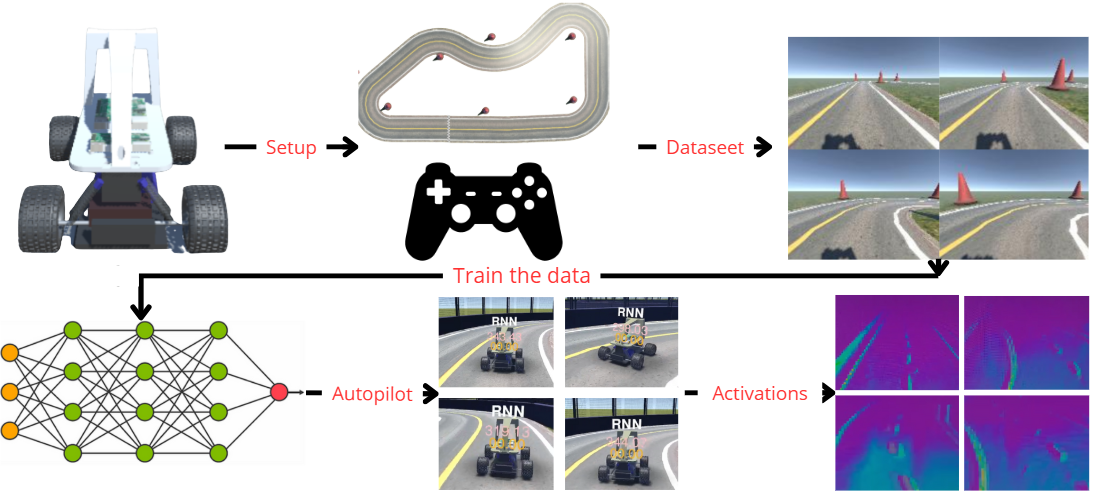
Figure 1: Block diagram outlining the end-to-end system pipeline for learning and autonomous driving task evaluation.
The research situates itself in the context of substantial work on behavior cloning and end-to-end deep learning for autonomous vehicles. However, while prior efforts have highlighted behavioral cloning's limits, architectural vulnerabilities, and simulation-to-real transfer issues, detailed RNN vs. 3D CNN benchmarking—especially with systematic ablation on MAC-scale simulated settings—has been largely absent. This work fills that empirical gap by dissecting model complexity vis-à-vis generalization and control robustness.
Network Architectures and Design
RNN and Modified Variants
The RNN baseline utilizes stacked LSTM layers following a convolutional feature extractor, adapted from the DonkeyCar framework.
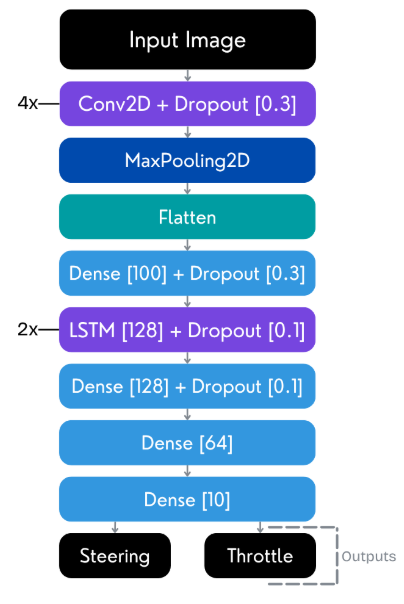
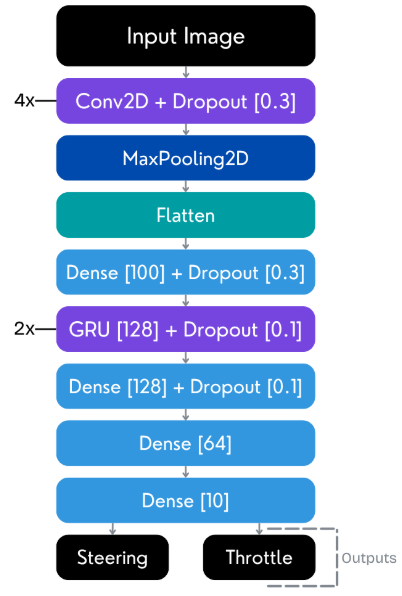
Figure 2: RNN model schematic, depicting convolutional encoding followed by LSTM sequence modeling, suited for sequential perception-to-control policies.
A modified variant replaces LSTMs with GRUs to reduce parameter count and computational depth while maintaining recurrent processing capability.
3D CNN and Residual Modifications
The principal innovation lies in the adoption of 3D CNNs for end-to-end video-based driving. These models capture both spatial and temporal correlations in the driving video stream, using spatiotemporal convolutions as primary feature extractors.
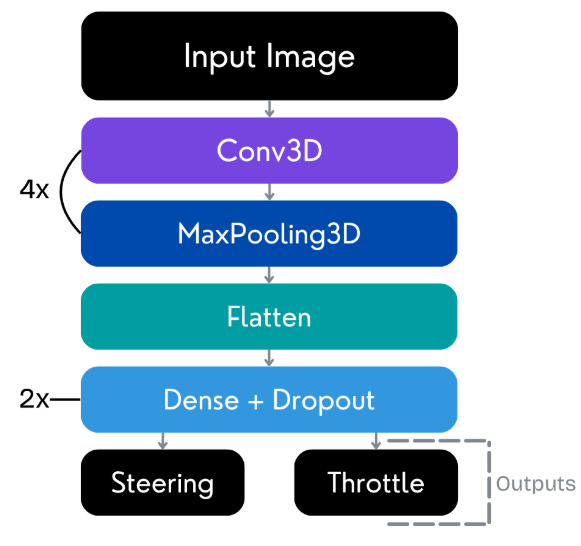
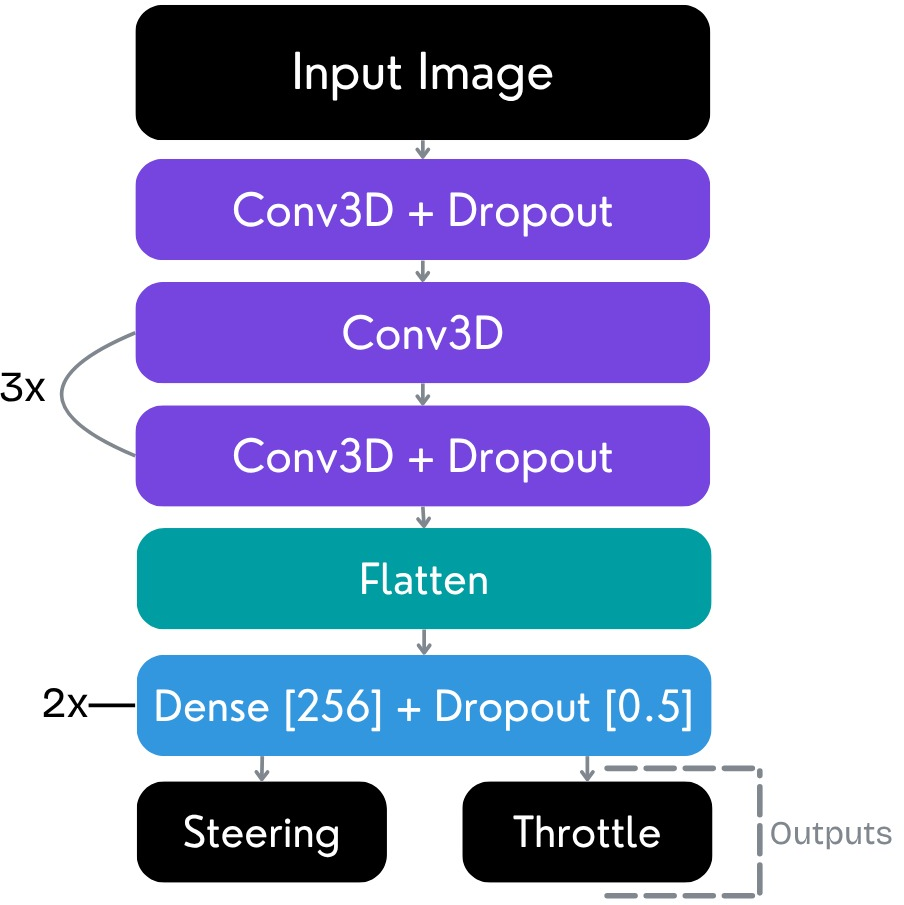
Figure 3: 3D CNN architecture from the DonkeyCar framework, applying joint spatial-temporal processing for efficient driving policy learning.
A modified residual 3D CNN integrates residual blocks with BatchNorm and LeakyReLU activations, inspired by ResNet principles to facilitate optimization in deep neural networks while mitigating vanishing gradients and overfitting.
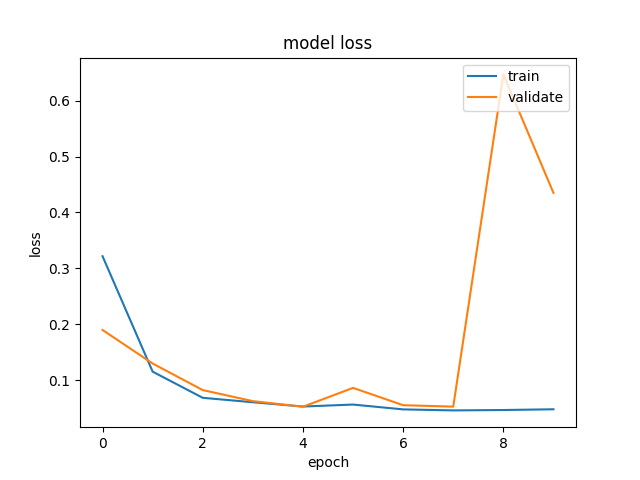
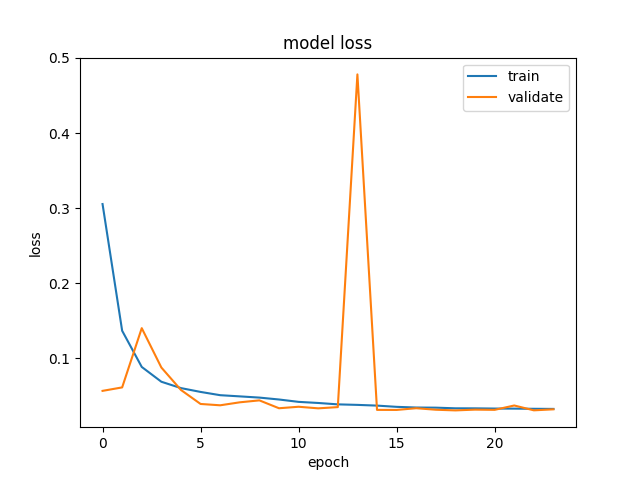
Figure 4: Model with an additional 3D convolutional layer used in the ablation study to probe network depth impact.
Experimental Setup
Data was collected by manual driving on two simulated tracks of differing complexity in the DonkeyCar environment, with images captured at 20 FPS and labeled with corresponding steering/throttle control actions.


Figure 5: Combined aerial and track-level visualization of the challenging Mini Monaco driving scenario used for high-complexity evaluation.
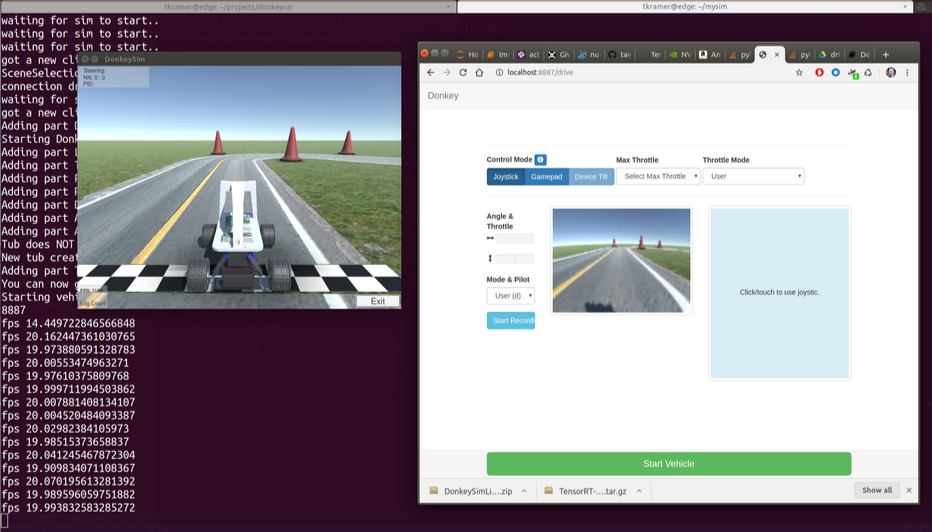
Figure 6: Donkey simulator setup, showing perception from the virtual vehicle and track configuration for synchronized data acquisition.
Two scenarios were evaluated:
- Mini Monaco: Closed, wall-bounded, visually complex, challenging for generalization.
- Generated Track: Open, simpler, fewer dynamic obstacles.
Results and Analysis
The modified 3D CNN, with a reduced number of layers, consistently achieved lower average lap times and greater consistency in track-following than all RNN variants on Mini Monaco. On simpler tracks, both RNN and 3D CNN models showed high performance, but the 3D CNN was more susceptible to overfitting due to redundant capacity.
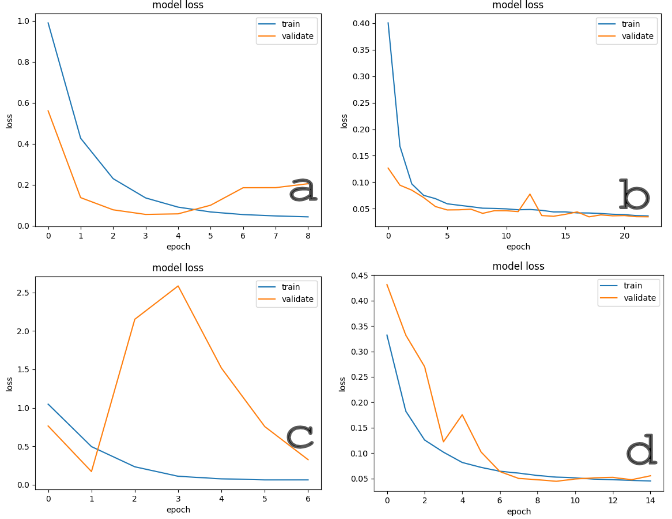
Figure 7: Training curves for multiple 3D CNN architectures, illustrating convergence rate, loss volatility, and comparative generalization on distinct tracks.
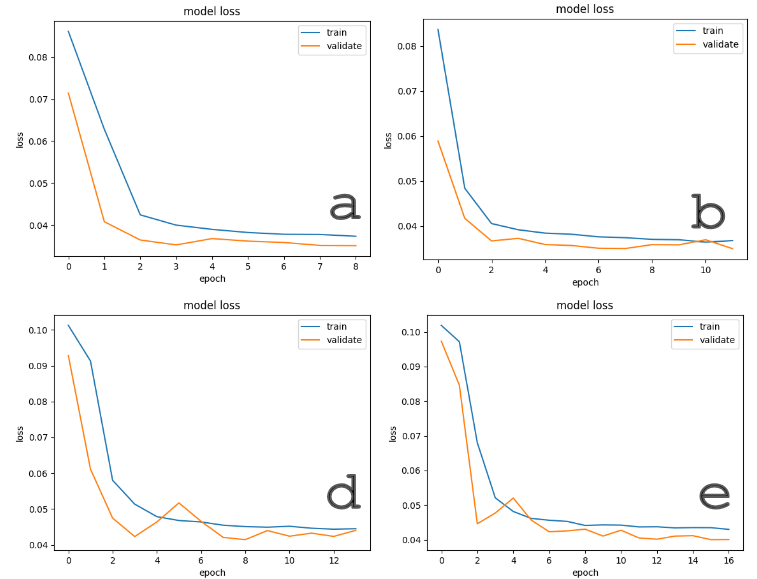
Figure 8: Training dynamics of RNN and modified RNN models across both environments, demonstrating stability and limited overfitting even in visually complex settings.
Key findings:
- The modified 3D CNN with one fewer 3D convolutional layer yielded a 34.10s average lap time on Mini Monaco, outperforming deeper variants (overfit, failed to generalize) and RNNs (36.24s–36.56s).
- RNN models, especially the GRU-modified version, exhibited robust adaptation and consistent, but not superior, lap times on both tracks.
Ablation Insights
The ablation study confirms that overparameterization in 3D CNNs for this domain leads to decreased performance and increased overfitting. Reducing model complexity provided the optimal speed-accuracy tradeoff for intricate environments, while excessive model depth neither improved learning nor generalization.
Theoretical and Practical Implications
The evidence establishes that spatial-temporal architectures like 3D CNNs can surpass recurrent models for visually complex, video-based autonomous driving tasks in simulation, provided overfitting is stringently controlled. Model simplicity, rather than depth, is favored in settings with repetitive structure and high-dimensional sensor input. This finding directly informs embedded deployment, where computational resources are constrained.
On a theoretical level, the results reinforce the necessity of model selection and capacity-matching to data complexity, especially in closed-loop control systems where generalization trumps memorization.
Future Directions
- Systematic transfer learning to real-world MACs, leveraging the established simulation-trained 3D CNNs.
- Extension to transformer architectures for attention-based integration of spatial and temporal cues.
- Adaptive model compression and quantization to facilitate on-device deployment.
- Multi-sensor fusion and exploration of meta-learning for rapid adaptation to novel tracks.
Conclusion
The study demonstrates that appropriately designed and tuned 3D CNNs outperform RNNs for end-to-end autonomous driving in visually complex simulation environments, with lighter architectures exhibiting more favorable generalization and control. These insights have immediate implications for resource-constrained deployment on physical MAC platforms and point to critical dimensions for future model innovation in autonomous systems research.