- The paper introduces a proactive data marking framework that detects unauthorized code usage in LLM training with a provable FDR guarantee.
- It employs a methodology that generates multiple semantically equivalent code variants through variable renaming and uses rank-based statistical tests for detection.
- Empirical results show over 90% detection success on small repositories while maintaining imperceptibility and negligible impact on model utility.
RepoMark: A Proactive Auditing Framework for Code LLM Data Usage
Motivation and Problem Setting
The proliferation of code LLMs trained on open-source repositories has introduced significant ethical and legal challenges, particularly regarding unauthorized data usage and compliance with open-source licenses. The lack of transparency in data collection for LLM training has led to increasing demands from developers and repository owners for mechanisms to audit whether their code has been used in model training. Existing data auditing approaches—both passive (membership inference) and proactive (data marking)—have notable limitations in the code domain, especially in terms of sample efficiency, semantic preservation, imperceptibility, and providing rigorous false detection rate (FDR) guarantees.
RepoMark Framework Overview
RepoMark introduces a proactive data marking and auditing framework specifically tailored for code LLMs. The core methodology is based on generating multiple semantically equivalent variants of each code file, publishing one at random, and later leveraging a rank-based statistical test to detect memorization in the target model. This approach is designed to satisfy four critical properties:
- Semantic Preservation: All code modifications retain original program semantics.
- Imperceptibility: Modifications are difficult for model trainers to detect and remove.
- Sample Efficiency: High detection accuracy is maintained even for small repositories (10–50 files).
- FDR Guarantee: The detection procedure provides a provable upper bound on the probability of false positives.
Marking and Detection Algorithms
Marking Process
RepoMark's marking algorithm operates by renaming local, single-token variables in code files. For each selected variable, an oracle code LLM is used to generate a set of m alternative variable names with similar predicted likelihoods. Each code file thus yields m semantically equivalent variants, differing only in the chosen variable name. The published version is selected uniformly at random, while the alternatives are retained privately.
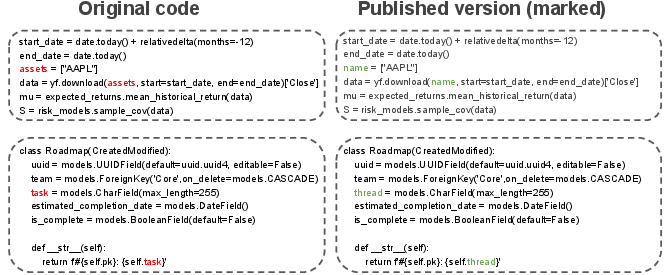
Figure 1: Examples of code marked with RepoMark, demonstrating semantic preservation and imperceptibility.
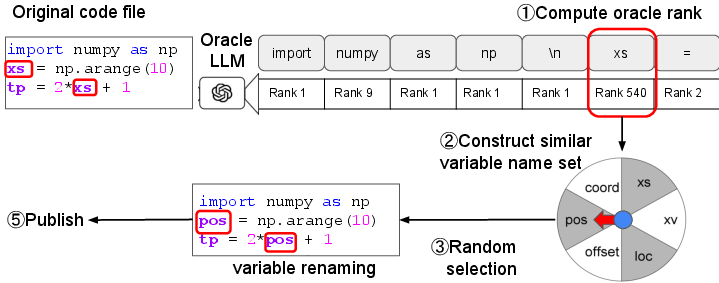
Figure 2: RepoMark's marking process for a single file, highlighting the renaming of a local variable.
Detection Process
During auditing, the repository owner queries the target code LLM with all m variants of each marked file and computes the loss for each. The rank of the published version's loss among all variants is recorded. Under the null hypothesis (H0) that the model was not trained on the marked data, these ranks are uniformly distributed. If the model was trained on the marked data, the published version's loss is biased toward lower ranks due to memorization.
The detection statistic is the sum of ranks across all marked positions. A hypothesis test is performed: if the rank sum is significantly lower than expected under H0, the model is flagged as having been trained on the marked data. The FDR is controlled by setting the rank sum threshold according to the cumulative distribution function of the sum of independent uniform random variables.
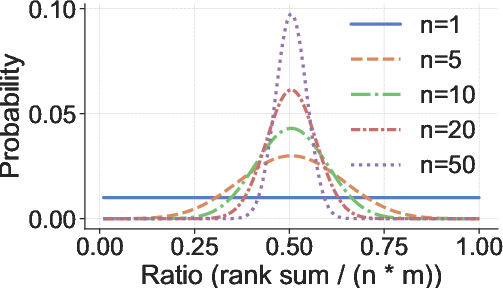
Figure 3: Distribution of the rank sum ratio under H0; concentration increases with the number of marks n.
Scalability and Practical Considerations
RepoMark supports multiple marks per file, enabling scalability to large codebases. The independence of rank distributions under H0 is preserved even when multiple variables are renamed within a single file. The mark sparsity parameter K controls the density of marks, balancing detection power and imperceptibility.
The framework is compatible with restricted API settings (e.g., OpenAI API), where only top-k log-probabilities are accessible. By leveraging the API's logit bias feature, RepoMark can still recover the necessary rank information for up to m≤20 alternatives.
Empirical Evaluation
RepoMark is evaluated on multiple code LLMs (CodeParrot-1.5B, StarCoder2-3B, InCoder-6B) and datasets (CodeParrot, CodeSearchNet, CodeNet). The primary metric is detection success rate (DSR) at various FDR guarantees.
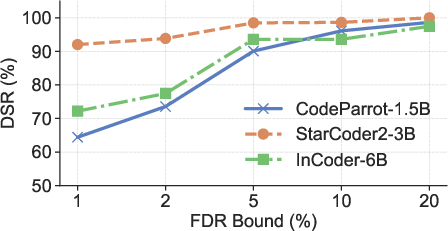
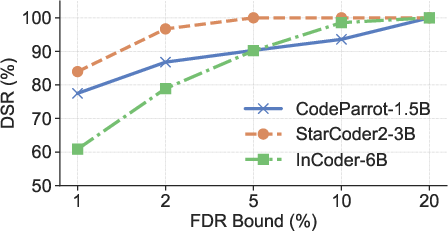
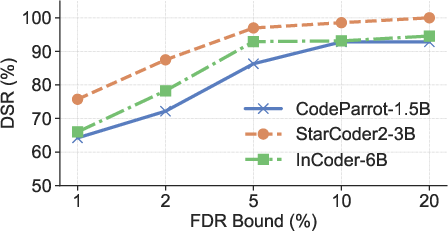
Figure 4: DSRs of RepoMark across three models and datasets under different FDR guarantees.
Key empirical findings include:
- High DSR: RepoMark achieves over 90% DSR on small repositories (20 files) at a strict 5% FDR, substantially outperforming all baselines (best prior data marking method achieves <55% DSR).
- Robustness: Performance is consistent across models and datasets, and remains strong even for repositories with as few as 10 files.
- Imperceptibility: Marked code exhibits minimal changes in CodeBLEU, edit distance, and perplexity compared to unmarked code.
- Negligible Impact on Model Utility: Training on marked code does not degrade LLM performance on standard code generation benchmarks.
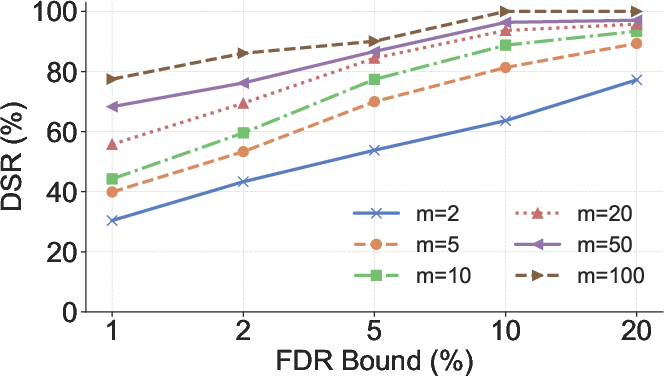
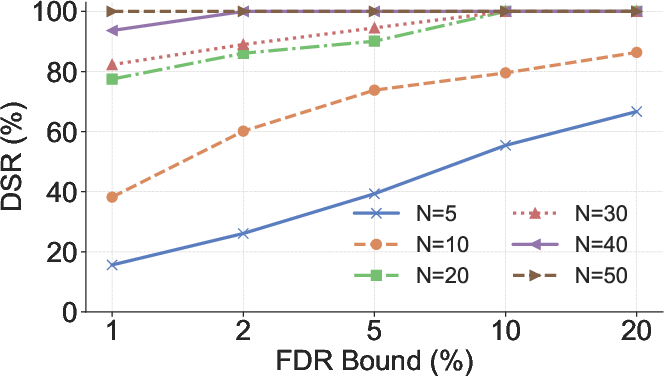
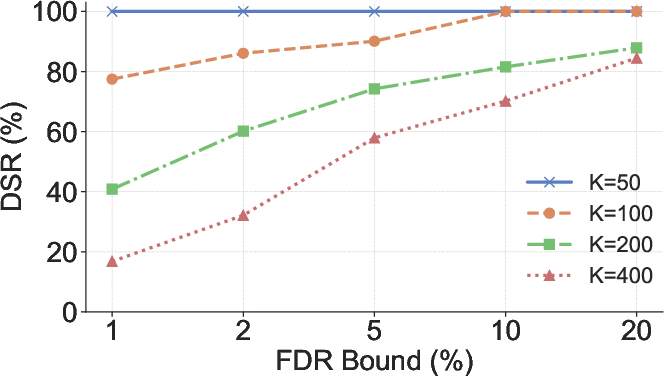
Figure 5: Impact of m (number of versions), N (repository file count), and K (mark sparsity) on DSR.
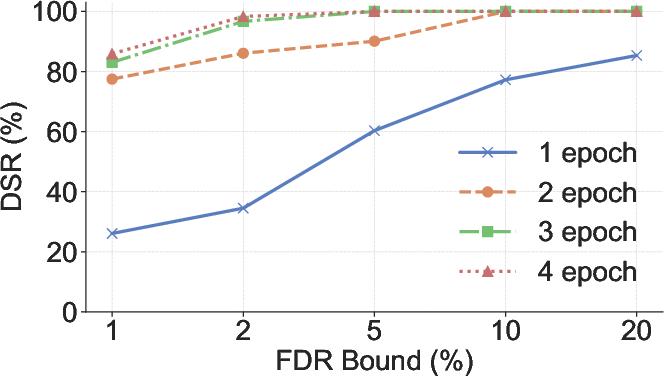
Figure 6: DSR as a function of training epochs, illustrating the relationship between memorization and detection power.
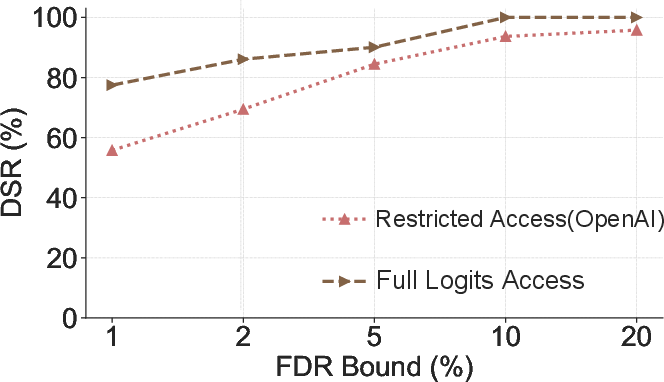
Figure 7: Detection performance under full logits access and restricted OpenAI API settings.
Security and Countermeasures
RepoMark demonstrates resilience against several potential countermeasures:
- Early Stopping: Reducing training epochs decreases DSR but also impairs model convergence, limiting the effectiveness of this defense.
- Dataset Filtering: Standard backdoor detection techniques (activation clustering, spectral signature) are ineffective at removing RepoMark's marks.
- Aggressive Variable Renaming: Even with 100% renaming of candidate variables, DSR remains above 65%, and such renaming degrades model performance and code readability.
Deployment Overhead
RepoMark's marking and detection procedures are computationally efficient. Marking a repository of 20 files takes approximately 15.6 seconds. Storage overhead is negligible, and detection costs are low even for large repositories, both under full and restricted API access.
Implications and Future Directions
RepoMark provides a practical, theoretically grounded solution for code repository owners to audit the usage of their data in code LLM training. The framework's provable FDR guarantee is particularly significant for legal and ethical compliance, as it enables probabilistic evidence of data misuse with quantifiable risk of false accusation.
The approach is extensible to other data modalities and could be adapted for broader data provenance and copyright enforcement in machine learning. Future work may explore more sophisticated semantic-preserving transformations, adaptive marking strategies, and integration with version control systems for continuous auditing.
Conclusion
RepoMark establishes a new standard for proactive data usage auditing in the code LLM domain, combining semantic-preserving, imperceptible marking with rigorous statistical detection and FDR control. Its strong empirical performance, robustness to countermeasures, and practical deployment characteristics position it as a viable tool for enhancing transparency and accountability in LLM training pipelines. The framework's generality and theoretical guarantees suggest broad applicability to future AI data governance challenges.