- The paper presents a zero-shot test-time planning framework that integrates particle and gradient guidance to enhance trajectory diversity and overcome local optima.
- It employs a bi-level sampling strategy with parent branching and sub-tree expansion to balance exploration and exploitation for complex control tasks.
- Experimental results in Maze2D, KUKA, and AntMaze environments show superior trajectory quality and performance compared to traditional planning methods.
Tree-Guided Diffusion Planner
Introduction
The paper introduces a novel zero-shot test-time planning framework using Tree-Guided Diffusion Planner (TDP) to solve complex control problems with pretrained diffusion models, a promising approach for test-time guided control tasks. The primary aim is to address existing challenges in trajectory sampling, particularly under non-convex, non-differentiable reward conditions that prove difficult for traditional gradient-based guidance methods.
Methodology
TDP is built on a bi-level sampling process that balances exploration and exploitation. The process is broken down into two levels:
- Parent Branching: This phase uses fixed-potential particle guidance (PG) to encourage diversity among sampled trajectories, addressing the in-distribution preference problem of diffusion models. By introducing repulsive forces between trajectories, TDP ensures broad exploration in the control state space.
- Sub-Tree Expansion: After generating diverse parent trajectories, TDP refines these through fast conditional denoising steps using task-specific gradient guidance. This sub-process enhances the dynamic feasibility and task relevance of the generated trajectories.
State Decomposition: A crucial component of TDP is state decomposition based on gradient signals, distinguishing between observation and control states. This enables a scalable and domain-agnostic approach to adapt trajectory generation at test time. Control states undergo particle guidance, while observation states are refined via gradient-based guidance.
Integrated Guidance Term: TDP uniquely integrates gradient guidance with particle guidance into a single model to simultaneously handle guidance and diversity, formulated as a joint conditional distribution.
Proposition: The paper demonstrates theoretically the advantage of TDP through a proposition elucidating the initialization problem in gradient guidance, contrasting the outcomes when initialized from standard Gaussian noise versus perturbed unconditional samples.
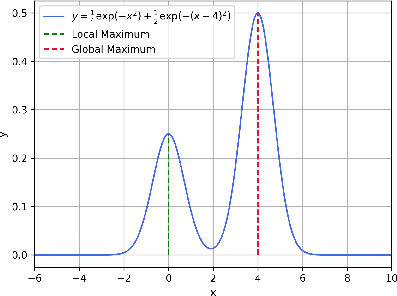
Figure 1: 1D Example of Local{additional_guidance}Global optimum existing reward problem, illustrating the tendency of gradient-based guidance to converge to local maxima.
Experimental Evaluation
Experiments are conducted across multiple environments:
- Maze2D Gold-Picking: TDP demonstrated improved trajectory sampling quality by successfully discovering hidden gold locations within complex mazes, outperforming methods like Monte-Carlo Sampling with Selection (MCSS) and Trajectory Aggregation Tree (TAT).
- KUKA Robot Arm Manipulation: TDP surpassed baselines in both pick-and-place (PnP) and the more complex Pick-and-Where-to-Place (PnWP) tasks, highlighting its effective handling of non-convex reward functions. TDP's performance reinforces the importance of its bi-level sampling strategy in bypassing local optima.

Figure 2: Diverse Trajectory Generation, showing trajectory distance measures and visualization, indicating superior exploratory capabilities of TDP over MCSS in PnWP tasks.
- AntMaze Multi-goal Exploration: TDP's robust handling of multi-goal scenarios was evident, achieving higher goal sequence match scores and fewer timesteps per goal compared to other methods.

Figure 3: AntMaze Multi-goal Exploration with TDP, showcasing improved prioritization and goal sequence accuracy over traditional planners.
Discussion and Conclusion
TDP successfully bridges the gap between traditional gradient guidance methods and the necessity for enhanced exploration-exploitation strategies in test-time guided planning. Its architectural innovations enable efficient adaptation without relying on task-specific training data, thereby generalizing across various challenging planning environments.
Future Directions: The study opens avenues for more efficient search strategies or incorporation of learned priors to further reduce computational overhead while maintaining robust exploration capabilities.
In conclusion, TDP offers a scalable, effective framework for handling complex diffusion model-based planning scenarios, highlighting its potential role in advancing real-world AI planning applications.

