- The paper introduces AdventureBench, a comprehensive benchmark designed to evaluate GUI agents on solving complete narrative story arcs across diverse adventure game subgenres.
- It presents the COAST framework that decomposes gameplay into a Seek-Map-Solve cycle and employs persistent clue memory to bridge long-term observation-behavior gaps.
- Empirical results reveal that even state-of-the-art models struggle with planning, perception, and lateral reasoning, highlighting a significant performance gap with humans.
AdventureBench: A Comprehensive Benchmark for GUI Agents in Full-Arc Adventure Games
Motivation and Benchmark Design
The paper introduces AdventureBench, a large-scale benchmark specifically designed to evaluate the capabilities of GUI agents—particularly those powered by LLMs and VLMs—in solving full story arcs in classic adventure games. Unlike prior benchmarks, which are limited in both diversity and narrative scope, AdventureBench comprises 34 Flash-based adventure games spanning multiple subgenres (mystery/detective, hidden object, room escape, visual novel, simulation). The benchmark is constructed to stress-test agents' abilities in long-horizon planning, memory, and reasoning, with a particular focus on the observation-behavior gap: the challenge of acting on information observed many steps earlier.

Figure 1: AdventureBench consists of 34 Flash-based classic adventure games and supports automatic evaluation of the GUI agent using CUA-as-a-Judge.
The selection of Flash games is motivated by their compact, self-contained story arcs (typically solvable by humans in under two hours), which makes them tractable for both human and agent evaluation. The games are chosen to maximize diversity in both gameplay mechanics and cognitive demands, as evidenced by the inter- and intra-subgenre analyses.
The Observation-Behavior Gap
A central challenge highlighted by AdventureBench is the observation-behavior gap: the temporal lag between when an agent observes a clue and when it must act on it, often hundreds of steps later. Human gameplay data collected for the benchmark demonstrates that players routinely bridge gaps of 100–400+ steps between observation and action, especially in mystery and room escape games.
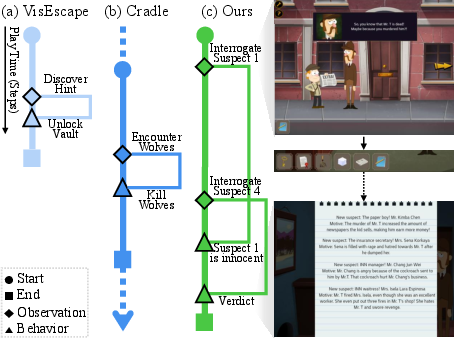
Figure 2: Comparison of gameplay progression across (a) VisEscape, (b) Cradle, and (c) AdventureBench. Prior benchmarks focus on short-term objectives or include short story arcs, limiting their ability to fully evaluate agents’ capacity to manage the long-term observation-behavior gap. In contrast, AdventureBench emphasizes completion of full story arcs involving long-term objectives, exemplified by suspect interrogations leading to a verdict.
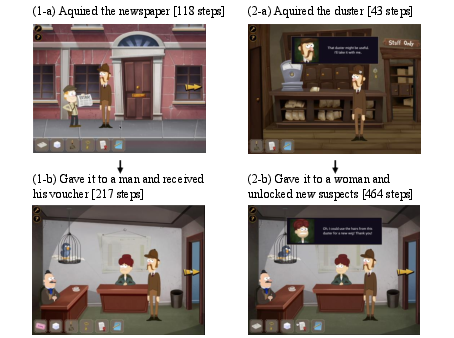
Figure 3: Examples illustrating the long-term observation-behavior gap from human player demonstrations in Sherlock Holmes: The Tea Shop Murder Mystery. (1-a) The player acquired a newspaper after 118 steps. (1-b) The player gave the newspaper to a man and received a voucher after 217 steps, resulting in a step gap of 99 between acquiring the newspaper and receiving the voucher. (2-a) The player acquired a duster after 43 steps. (2-b) The player gave the duster to a woman, unlocking new suspects after 464 steps, with a step gap of 421 between acquiring the duster and unlocking new suspects.
This property is largely absent from prior benchmarks, which either focus on short-term tasks or artificially constructed environments with minimal narrative dependencies.
Automated Evaluation: CUA-as-a-Judge
Manual evaluation of agent progress in complex games is a major bottleneck. The paper introduces CUA-as-a-Judge, an automated evaluation agent built on top of Claude-3.7-Sonnet's computer-use capabilities. This agent interacts with the game environment post-episode, verifying milestone completion by executing GUI actions (e.g., opening inventory, checking scores) and comparing observed states to predefined success criteria.
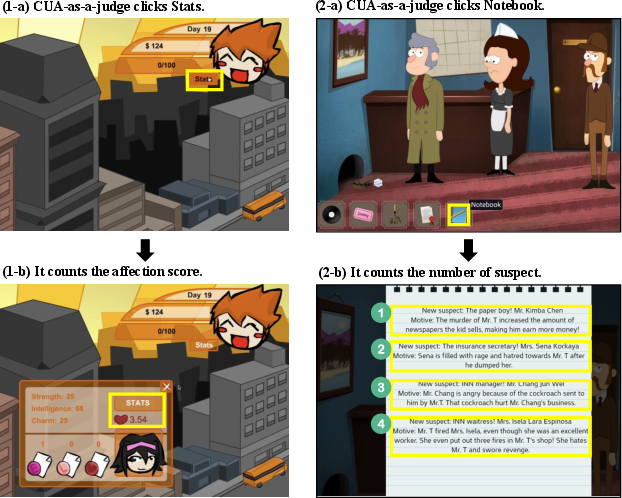
Figure 4: CUA-as-a-Judge verifies game progress by interacting with the environment. Left: (1-a) The judge clicks the Stats'' button in Pico Sim Date to (1-b) verify the character's affection score. Right: (2-a) The judge clicks theNotebook'' item in Sherlock Holmes: The Tea Shop Murder Mystery to (2-b) count the number of suspects (5) identified by the player, confirming milestone completion.
Empirical validation shows that CUA-as-a-Judge achieves 94% agreement with human annotators, with near-perfect correlation on milestone completion rates, enabling scalable and reproducible evaluation.
The COAST Framework: Bridging Long-Term Dependencies
To address the observation-behavior gap, the authors propose COAST (Clue-Oriented Agent for Sequential Tasks), a modular agentic framework that explicitly manages long-term clue memory and decomposes gameplay into a Seek-Map-Solve cycle:

Figure 5: Overview of COAST Framework with Seek-Map-Solve Cycle.
- Clue Seeker: Proactively explores the environment to collect clues, storing them in a persistent memory buffer.
- Clue Mapper: Periodically analyzes the memory and trajectory to generate plausible subtask hypotheses by matching clues to past observations, leveraging abductive and lateral reasoning.
- Problem Solver: Executes subtasks derived from clue-observation mappings, updating the resolved goal set and memory.
This architecture is instantiated using Claude-3.7-Sonnet Computer-Use for perception and action, with all modules communicating via structured prompts and JSON-based memory representations. The clue memory is unbounded in practice, as the total token count remains well within modern LLM context limits.
Experimental Results and Analysis
A comprehensive evaluation is conducted across seven agent configurations, including proprietary end-to-end agents (Claude-3.7-Sonnet Computer-Use, OpenAI CUA), open-source models (UI-TARS-1.5-7B), and modular frameworks (Cradle, Agent S2) with various VLM backbones and GUI grounding modules.
Key findings:
Failure Modes
Three primary failure patterns are identified:
- Weak Planning: Agents repeat actions, revisit locations, and fail to leverage past clues for future planning.
- Poor Visual Perception: Agents misinterpret non-standard layouts, leading to missed interactions even in visually simple games.
- Deficient Lateral Thinking: Agents struggle with creative, non-obvious subtask generation, often failing to connect clues to their eventual use.
COAST Improvements
COAST demonstrates measurable improvements:
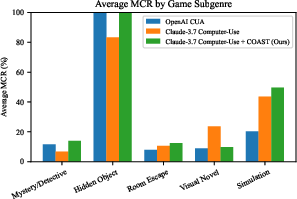
- Milestone completion rate increases by up to 2.78 percentage points over the best baseline.
- Success rate increases by 5.88 percentage points, with the largest gains in subgenres with substantial observation-behavior gaps (mystery/detective, room escape).
- Ablation studies confirm that all three modules (Seeker, Mapper, Solver) are necessary for optimal performance; removing the Mapper, in particular, degrades performance in clue-rich games.
However, COAST does not consistently outperform baselines in visual novel subgenres, where the observation-behavior gap is minimal and resource management dominates.
Failure Analysis
Manual inspection reveals that COAST mitigates planning and lateral thinking failures but does not address perception errors (inherited from the backbone VLM) or resource management issues in simulation-heavy games.
Practical and Theoretical Implications
Practical Implications:
- Benchmarking: AdventureBench provides a scalable, diverse, and challenging testbed for GUI agents, with automated evaluation and a focus on long-horizon, narrative-driven tasks.
- Agent Design: The COAST framework demonstrates the necessity of explicit long-term memory and structured subtask planning for progress in complex environments.
- Evaluation: CUA-as-a-Judge enables reproducible, fine-grained assessment of agent progress, reducing reliance on costly human annotation.
Theoretical Implications:
- The persistent gap between human and agent performance, even with advanced LLMs, highlights fundamental limitations in current architectures' ability to bridge long-term dependencies and perform abductive/lateral reasoning.
- The knowing-doing gap is empirically demonstrated: even when LLMs have access to contaminated (pretrained) knowledge about a game, they fail to translate this into effective action sequences.
Limitations and Future Directions
- Manual Milestone Definition: While the process is lightweight, it is not fully scalable or genre-agnostic. Future work could automate milestone extraction via narrative flow analysis or structured story representations.
- Genre Coverage: The benchmark is not directly applicable to fast-paced, reflex-oriented games (e.g., platformers), as CUA-as-a-Judge relies on discrete, verifiable milestones.
- Memory Scalability: COAST currently stores all clues; as action horizons increase, memory management strategies (summarization, retrieval, forgetting) will become necessary.
- API Cost: Large-scale evaluation with proprietary models is expensive, underscoring the need for efficient open-source agents.
Conclusion
AdventureBench establishes a new standard for evaluating GUI agents in complex, narrative-driven environments, exposing critical deficiencies in current LLM-based agents' planning, perception, and reasoning capabilities. The COAST framework offers a principled approach to bridging long-term dependencies, but a substantial gap to human-level performance remains. The benchmark, evaluation tools, and agentic insights provided by this work will inform the next generation of research on generalist, memory-augmented, and reasoning-capable agents.