- The paper proposes a modular framework that generates synthetic long-context data using task-specific prompt templates and enriched metadata.
- It details methods including multi-turn dialogues, document-grounded tasks, verifiable instruction-response tasks, and complex reasoning examples.
- The framework demonstrates scalability and model-agnostic design, with rigorous validation ensuring high dataset quality for LLM training.
Modular Techniques for Synthetic Long-Context Data Generation
The paper "Modular Techniques for Synthetic Long-Context Data Generation in LLM Training and Evaluation" focuses on generating diverse, high-quality, and verifiable datasets to facilitate the development of LLMs capable of handling long-context inputs. This essay provides an in-depth analysis of the methods, architecture, and implications presented in the paper.
Introduction
LLMs often struggle with long-context scenarios due to limitations in available datasets for training and evaluation. This paper introduces a modular framework for synthetic long-context data generation, harnessing the power of LLMs themselves to create data aligned with various training and alignment objectives. The framework adopts a prompt-based interaction model, encompassing paradigms such as multi-turn conversations, document-grounded tasks, verifiable instruction-response generation, and long-context reasoning, supported by prompt templates and enriched metadata.
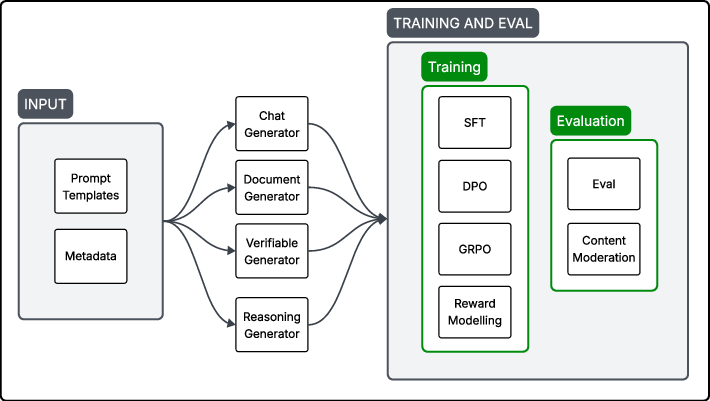
Figure 1: Overview of the long-context data generation framework. Prompt templates and metadata are used to guide four task-specific generators, producing outputs suited for training and evaluation.
Methodology
Framework Architecture
The framework targets four core generation paradigms, each contributing to the creation of diverse datasets for training long-context capabilities in LLMs. The system integrates structured prompts and metadata to optimize the generation process across these paradigms.
- Multi-Turn Conversational Dialogues: This paradigm generates extended interaction sequences to simulate rich, multi-turn conversations between AI and users.
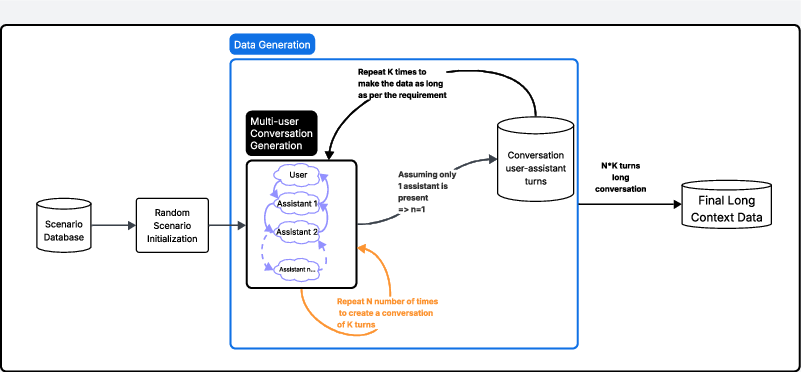
Figure 2: Recursive multi-turn conversation generation. A scenario is sampled and initialized to produce an initial conversation seed. The dialogue is expanded by recursively feeding the output back as seed input, producing progressively longer sequences across multiple assistant turns.
- Document-Grounded Input-Output Pairs: Emphasizing real-world task simulation, this modality uses synthetic documents to ground long-context instruction tasks.
- Verifiable Instruction-Response Tasks: This focuses on producing outputs that are structurally and semantically verifiable, crucial for reward modeling and alignment.
- Long-Context Reasoning Examples: Designed to stress-test models with complex reasoning requirements that span extensive input contexts.
Data Generation Techniques
The framework employs a modular architecture that supports scalability and adaptation to different domains and alignment objectives. It includes mechanisms for task-specific prompt engineering, guided by structured templates and enriched with metadata to ensure outputs are purpose-aligned and verifiable.
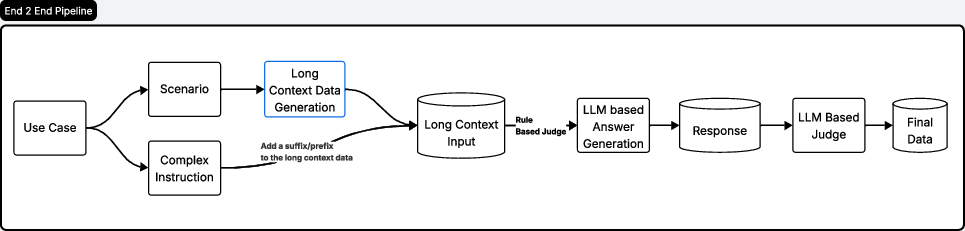
Figure 3: End-to-end pipeline for long-context data generation.
Design Considerations
Task-Specific Prompts
The paper highlights the importance of careful prompt design, incorporating rich metadata and structured scaffolding to enhance data quality. Key elements such as role-specific nuances, tone adjustments, and controlled diversity are considered to mitigate biases and enhance dataset realism.
Evaluation and Validation
The synthetic data undergoes rigorous validation to ensure it meets the required standards for coherence, relevance, and task fidelity. An LLM-based judge pipeline evaluates outputs against predefined criteria, ensuring the alignment of synthetic data with intended instructional objectives.
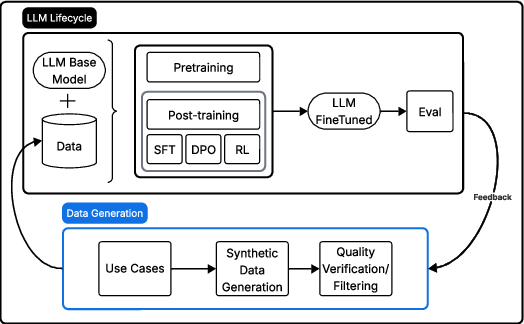
Figure 4: The LLM lifecycle highlighting the centrality of data generation in downstream training quality. Our framework targets the data generation sub-process (in blue), ensuring that synthetic examples are diverse, task-relevant, and verifiable.
Implications and Future Work
The proposed framework bridges a critical gap in LLM training by providing scalable methods for long-context data generation. Its model-agnostic nature and flexibility to adapt across domains make it suitable for applications requiring complex reasoning and multi-turn interactions.
Future developments may focus on refining the evaluation methods and exploring integration with emerging alignment paradigms such as RLHF and DPO. The framework offers a foundation for future exploration into synthetic data generation, emphasizing the growing importance of data-centric approaches to machine learning.
Conclusion
The research presents a comprehensive approach to synthetic data generation for long-context tasks, crucial for advancing the capabilities of LLMs. By systematically addressing the design and evaluation of long-context data, the framework supports alignment-driven LLM development, emphasizing scalable, verifiable, and diverse dataset creation. This paper's insights provide valuable contributions to the ongoing development and refinement of LLM training methodologies.