- The paper introduces a two-stage pipeline that standardizes synthetic data generation and uses iterative self-improvement to eliminate teacher model biases.
- The paper leverages rule-based filtering and F1-score thresholds to enhance annotation quality for texts, tables, and formulas.
- The paper demonstrates state-of-the-art performance on benchmarks, outperforming larger OCR models in complex document layout recognition.
Distillation-Free Vision-LLM Adaptation for Document Conversion: The POINTS-Reader Framework
Introduction
The POINTS-Reader framework addresses the persistent challenge of high-fidelity document conversion in vision-LLMs (VLMs), particularly for documents containing complex structures such as tables, mathematical formulas, and multi-column layouts. Existing approaches predominantly rely on knowledge distillation from large proprietary or open-source models, which introduces performance bottlenecks and propagates teacher model biases. POINTS-Reader circumvents these limitations by proposing a fully automated, distillation-free pipeline for dataset construction and model adaptation, enabling robust document conversion without external supervision.
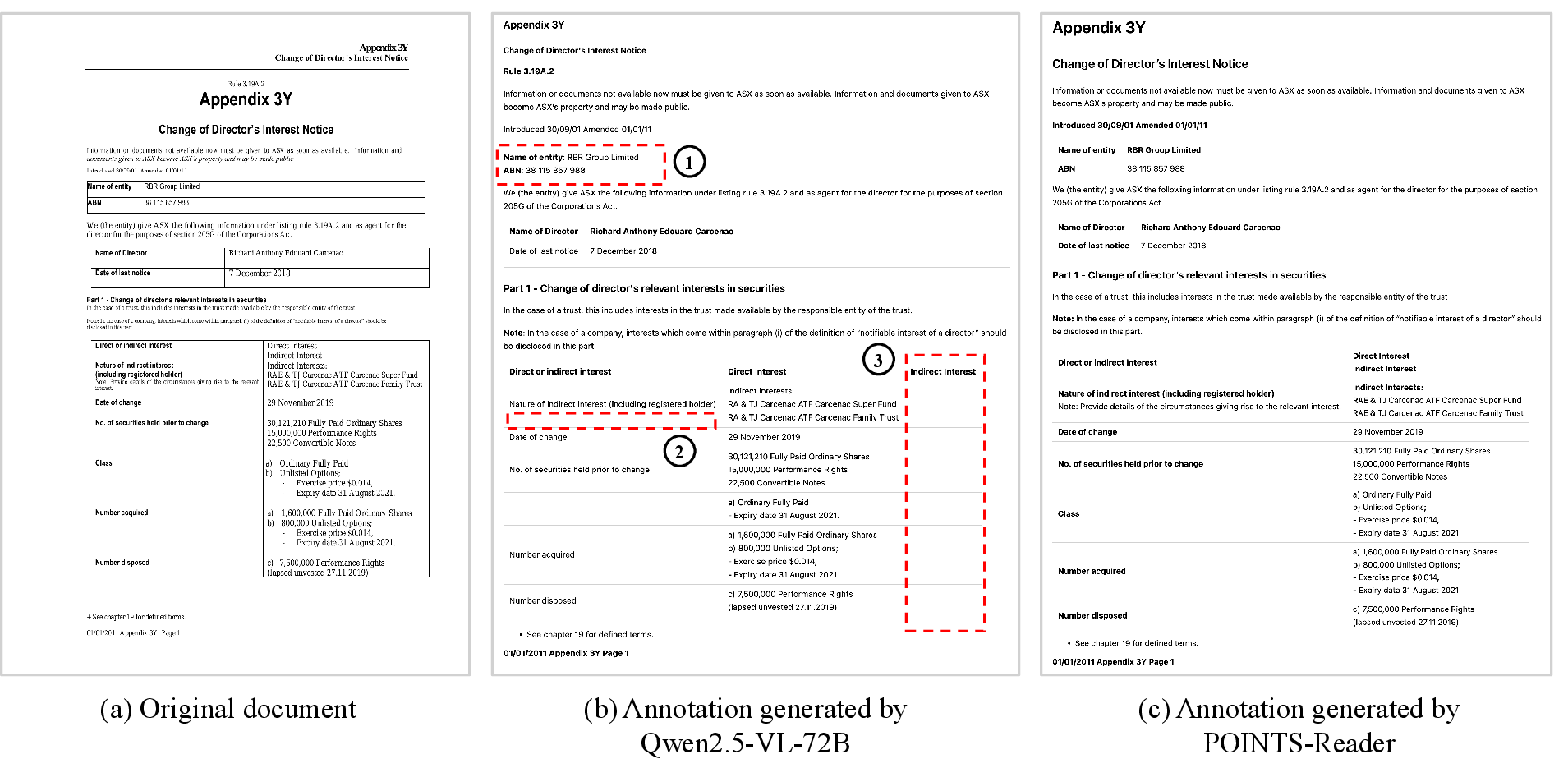
Figure 1: Example annotations generated by Qwen2.5-VL-72B and POINTS-Reader. Distillation may not reach the performance of the teacher model and can inherit its biases, such as (1) failure to recognize tables, (2) missing text, and (3) incorrect table structures.
Two-Stage Data Construction Pipeline
The UWS standardizes output formats for plain text, tables, and mathematical formulas, mitigating the learning complexity associated with heterogeneous document element representations. Plain text is encoded in Markdown, tables in HTML (with CSS restricted to merged cell attributes), and formulas in LaTeX following KaTeX conventions. Synthetic data generation leverages LLMs with category-specific prompts to produce diverse document samples, which are rendered into images using headless Chrome. This process yields image-text pairs for initial fine-tuning of the VLM backbone (POINTS-1.5).
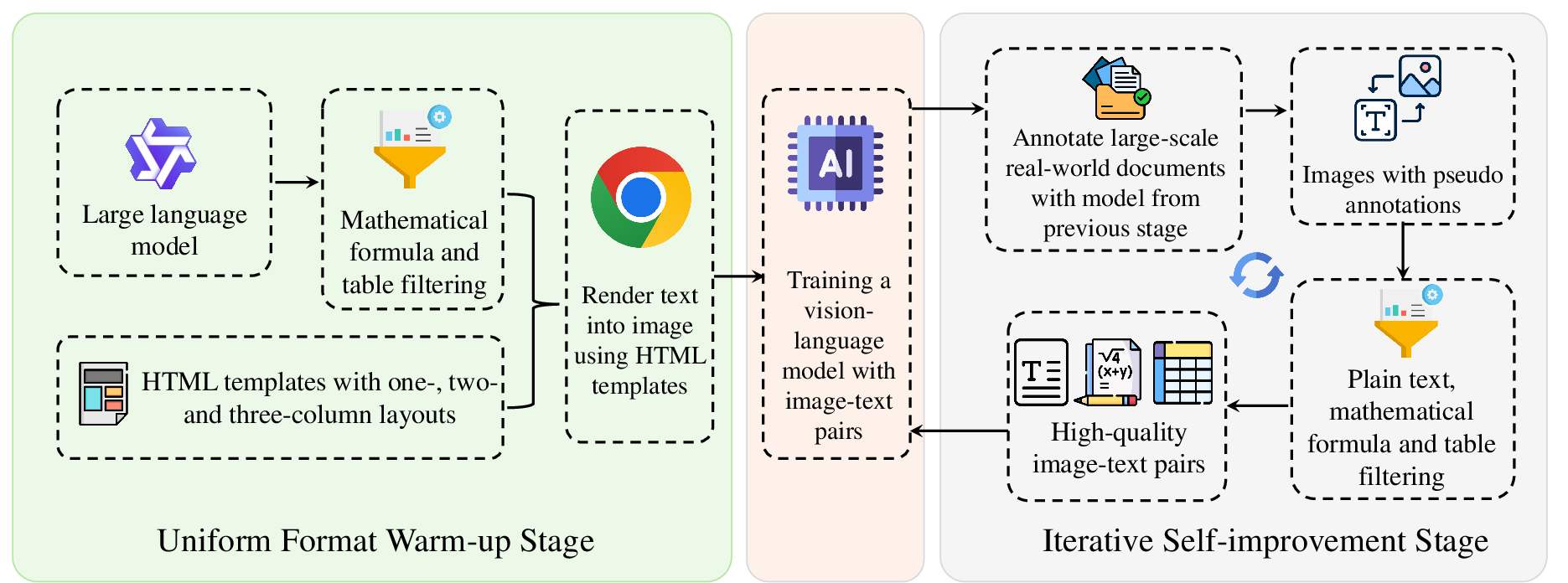
Figure 2: Demonstration of the two-stage pipeline to generate large-scale high quality dataset.
Empirical results demonstrate that increasing data diversity—by incorporating samples with formulas, tables, and multi-column layouts—improves model performance across all document element categories. However, scaling synthetic data beyond 800,000 samples induces overfitting to artificial layouts, necessitating further adaptation to real-world distributions.
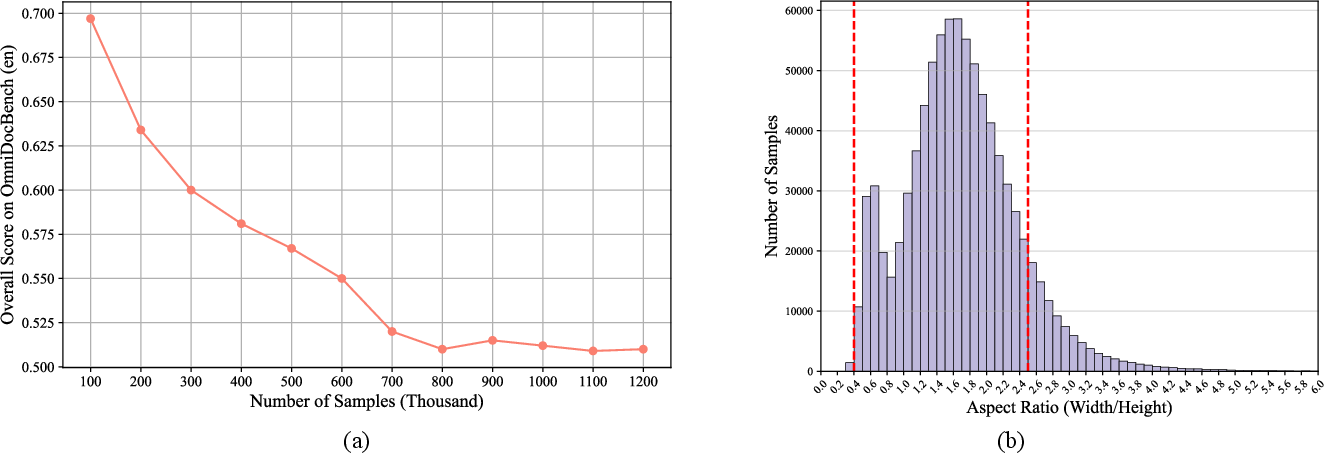
Figure 3: (a) Scaling curve of data generated during the uniform format warm-up stage (lower is better). (b) Distribution of aspect ratios (width/height) in the original dataset. Samples with aspect ratios beyond the red dotted line are filtered out.
Filtering out samples with abnormal aspect ratios (outside (52,25)) further enhances model generalization, aligning the synthetic data distribution with real-world document layouts.
Iterative Self-Improvement Stage (ISS)
ISS adapts the model to real-world data by leveraging self-generated annotations on large-scale document images (DocMatix). Annotation quality is ensured via rule-based filtering:
- Plain Text: F1-score computed against OCR references (PaddleOCR), with a threshold (optimal at 0.9) to discard low-quality samples.
- Tables: Structural validity checks (row/column consistency).
- Formulas: Syntactic correctness validation.
Filtered high-quality samples are used for retraining, and the process is iterated, resulting in progressive improvements in both model accuracy and data quality.
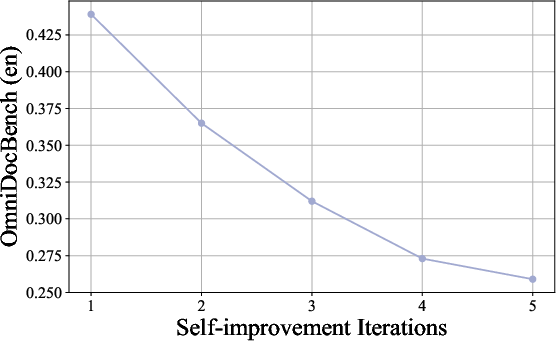
Figure 4: Model performance steady improves during the self-improvement stage.
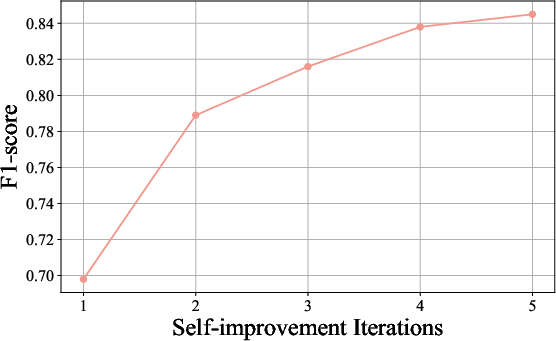
Figure 5: The F1-score steadily improves during the self-improvement stage. The score is computed prior to data filtering.
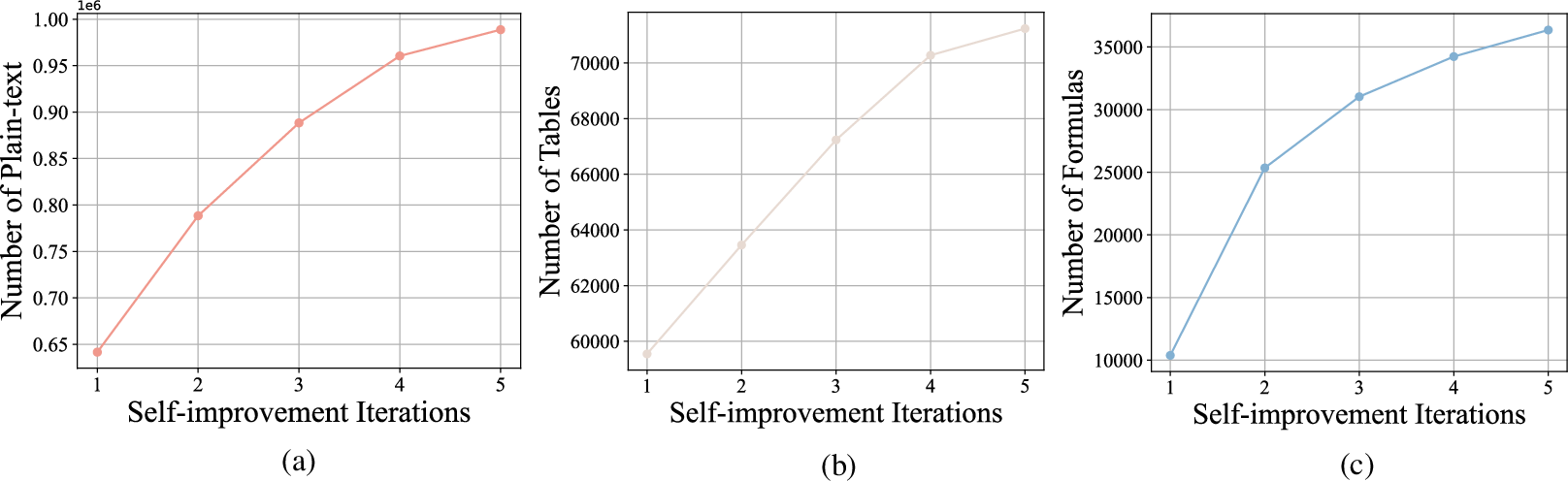
Figure 6: The number of samples after filtering consistently increases.(a) The number of retained samples containing only plain text increases after filtering. (b) The number of retained samples containing tables increases after filtering. (c) The number of retained samples containing tables increases after filtering.
Ablation studies confirm the critical role of filtering strategies and F1-score thresholds in maintaining data quality and diversity. Initializing model weights from the pre-trained backbone, rather than previous noisy iterations, yields superior performance.
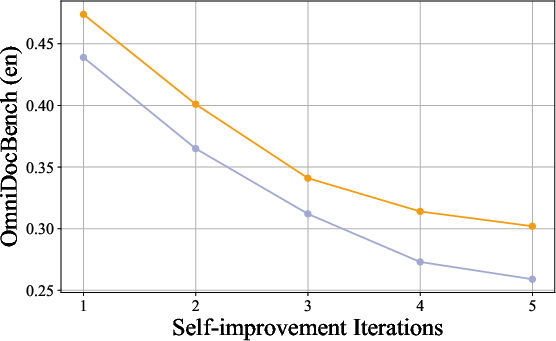
Figure 7: Loading weights from a previous model can degrade performance. The orange line and the purple line represent the performance of models initialized from the previous version and the pre-trained model, respectively.
Inclusion of UWS-generated data during ISS further boosts model accuracy due to its high annotation fidelity.
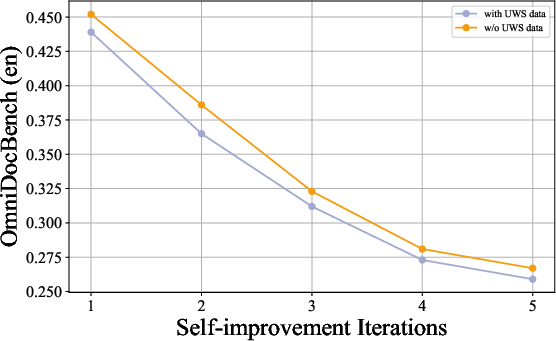
Figure 8: Including data generated in the UWS into the ISS will benefits the performance of the model. We include data generated from UWS by default during the iterative self-improvement stage.
Dataset Analysis and Distribution
The final training set comprises over 1.1M high-quality samples, with a significant proportion containing only plain text and a minority containing tables or formulas. Token length distribution analysis reveals most samples are under 1,000 tokens, and attempts to balance sample types via up/down-sampling degrade performance due to reduced diversity and overfitting.
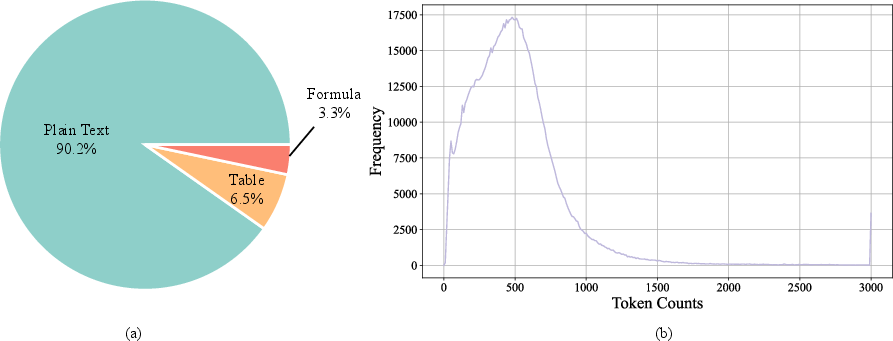
Figure 9: Distribution of data in the final iteration of the Self-improvement Stage. (a) shows the proportion of samples containing only plain text, formulas, and tables. (b) presents the distribution of sample counts with respect to different token lengths.
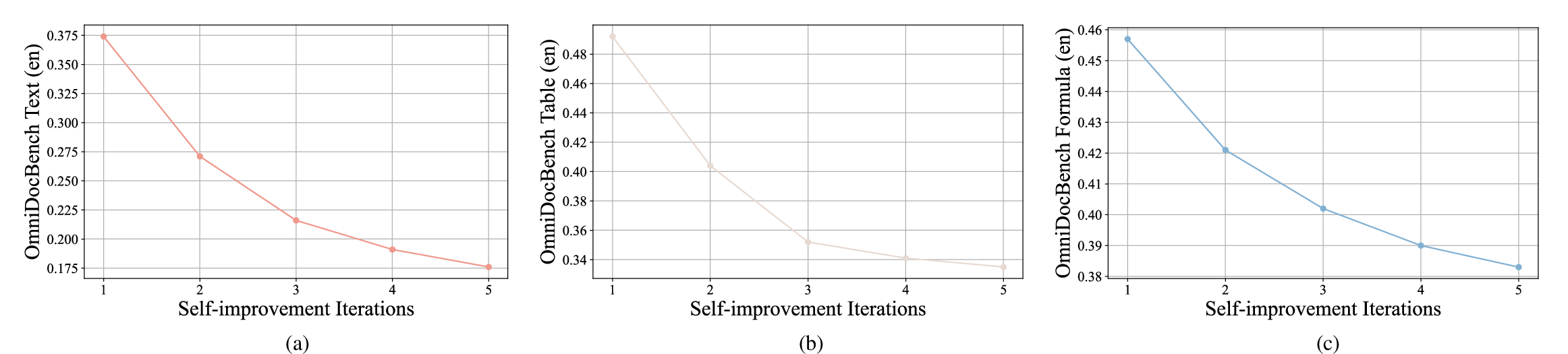
Figure 10: Steady improvement of performance on plain text, table and formula during the self-improvement stage.
Benchmarking and Comparative Evaluation
POINTS-Reader is evaluated on OmniDocBench and Fox benchmarks, demonstrating state-of-the-art performance across plain text, tables, and formulas. Notably, it surpasses larger models such as Qwen2.5-VL-72B on table recognition and outperforms proprietary expert OCR models (e.g., Mistral OCR, GOT-OCR) on multiple metrics. Direct distillation from Qwen2.5-VL-72B yields inferior results compared to the distillation-free approach, highlighting the efficacy of the proposed pipeline.
Figure 1: Example annotations generated by Qwen2.5-VL-72B and POINTS-Reader. Distillation may not reach the performance of the teacher model and can inherit its biases, such as (1) failure to recognize tables, (2) missing text, and (3) incorrect table structures.
Case Studies and Qualitative Analysis
Iterative self-improvement leads to substantial annotation quality gains, as evidenced by case studies comparing model outputs from initial and final iterations. The model demonstrates improved handling of complex layouts, accurate table structure extraction, and robust formula recognition.

Figure 11: Case study of samples evolved during the self-improvement stage. The first figure shows the original document, the second figure presents the annotation generated by the model in the first iteration, and the last figure displays the annotation produced by the model in the final iteration.

Figure 12: Case study of samples evolved during the self-improvement stage. The first figure shows the original document, the second figure presents the annotation generated by the model in the first iteration, and the last figure displays the annotation produced by the model in the final iteration.
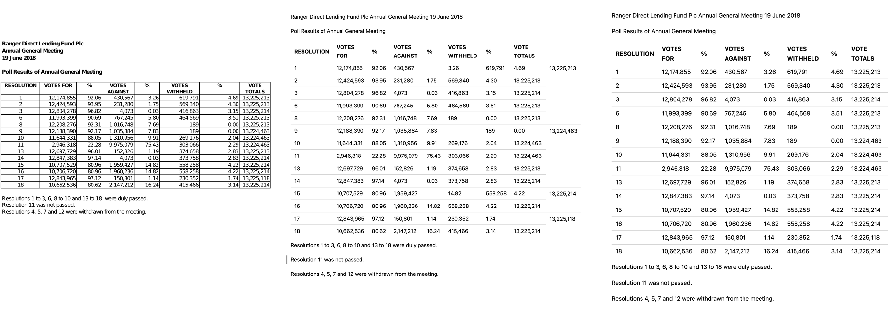
Figure 13: Case study of samples evolved during the self-improvement stage. The first figure shows the original document, the second figure presents the annotation generated by the model in the first iteration, and the last figure displays the annotation produced by the model in the final iteration.
Implementation Considerations
POINTS-Reader is trained on 64 Nvidia H800 GPUs, with 1M samples requiring approximately 7 hours. Inference on 2M DocMatix samples takes 10 hours. The model is deployed using SGLang, supporting a maximum context length of 8192 tokens. The pipeline is fully automated, requiring no manual annotation or external supervision, and is publicly available for reproducibility and further research.
Limitations and Future Directions
POINTS-Reader currently supports only English and printed fonts, limiting its applicability to multilingual and handwritten document conversion. Future work will focus on extending language coverage, improving handwritten text recognition, and incorporating image extraction capabilities. Additionally, further strategies to increase data diversity and address sample imbalance are necessary to push performance beyond the observed plateau.
Conclusion
POINTS-Reader introduces a robust, distillation-free framework for vision-LLM adaptation in document conversion tasks. By leveraging a two-stage pipeline—synthetic data warm-up and iterative self-improvement with rigorous filtering—the model achieves state-of-the-art performance, surpassing both general-purpose and expert models, including those of significantly larger scale. The approach demonstrates that high-quality, diverse, and well-filtered training data are critical for effective end-to-end document conversion, and that reliance on distillation from external models is not necessary for competitive results. The framework sets a new standard for automated dataset construction and model adaptation in document understanding, with clear implications for future research in scalable, language-agnostic, and structure-aware VLMs.

