Benchmarking Optimizers for Large Language Model Pretraining
Abstract: The recent development of LLMs has been accompanied by an effervescence of novel ideas and methods to better optimize the loss of deep learning models. Claims from those methods are myriad: from faster convergence to removing reliance on certain hyperparameters. However, the diverse experimental protocols used to validate these claims make direct comparisons between methods challenging. This study presents a comprehensive evaluation of recent optimization techniques across standardized LLM pretraining scenarios, systematically varying model size, batch size, and training duration. Through careful tuning of each method, we provide guidance to practitioners on which optimizer is best suited for each scenario. For researchers, our work highlights promising directions for future optimization research. Finally, by releasing our code and making all experiments fully reproducible, we hope our efforts can help the development and rigorous benchmarking of future methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Benchmarking Optimizers for LLM Pretraining”
What is this paper about?
This paper compares many different “optimizers” (the rules that tell a neural network how to adjust itself while learning) to find out which ones work best for training LLMs. The authors run fair, careful tests on models of different sizes, with different batch sizes, and for different training lengths, and they share all their code so others can repeat the tests.
What questions are the authors trying to answer?
- Which optimizer is best for training LLMs, depending on model size, batch size, and how long you train?
- Do new optimizers actually beat the classic AdamW optimizer in real, fair tests?
- Which training choices (like warmup, weight decay, or learning rate schedules) make the biggest difference?
- How should practitioners pick and tune an optimizer in practice?
How did they test this? (In simple terms)
Think of training a model like teaching someone to guess the next word in a sentence. An optimizer is the study strategy they use to improve with each guess.
Here’s what the authors did:
- They trained Llama-style LLMs of different sizes (from 124 million to 720 million parameters, plus a Mixture-of-Experts model).
- The models learned on a large, cleaned text dataset (FineWeb), predicting the next token (piece of text). Lower “validation loss” means better predictions.
- They tried 11 optimizers, including:
- AdamW (the standard)
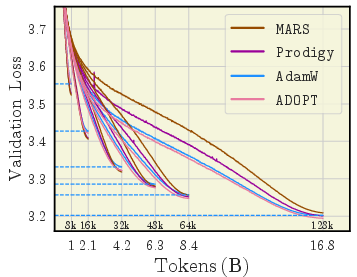
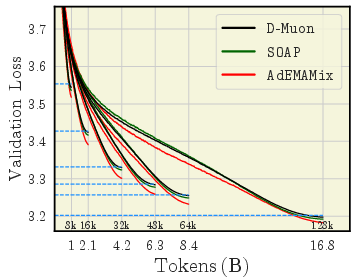
- AdEMAMix, ADOPT, SOAP, MARS (newer methods)
- Lion and Signum (sign-based optimizers)
- Muon and D-Muon (a fixed version of Muon)
- Prodigy and SF-AdamW (aim to need fewer manual settings)
- Sophia (a second-order-style method)
- They carefully tuned each optimizer’s settings (like learning rate and momentum) near a common training length (based on “Chinchilla” scaling, a rule-of-thumb for how long to train a model), then checked how well those settings held up when training longer.
- They also ran “ablations,” which are focused tests where you change one thing at a time:
- Weight decay (a way to keep the model’s numbers from getting too large—like keeping your room tidy so it doesn’t get messy)
- Warmup (start with small learning steps, then speed up)
- Learning rate schedules (how the step size shrinks over time: cosine, linear, or WSD)
- Learning rate sensitivity (how picky a method is about the step size)
- Other details like gradient clipping and initialization
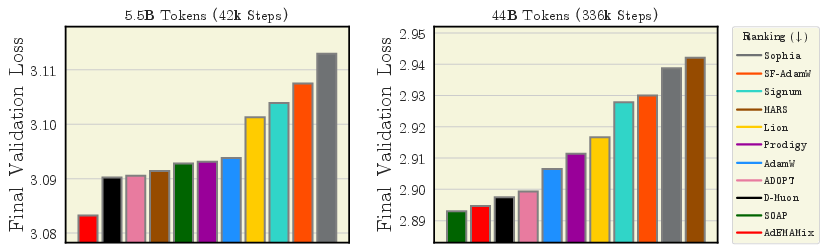
What did they find, and why does it matter?
Here are the main takeaways, written plainly:
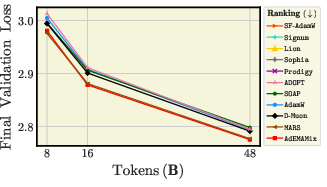
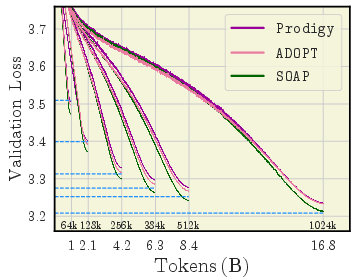
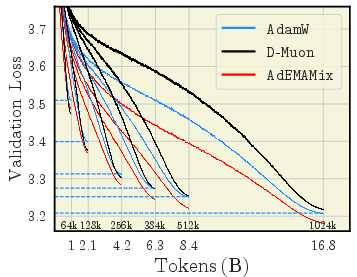
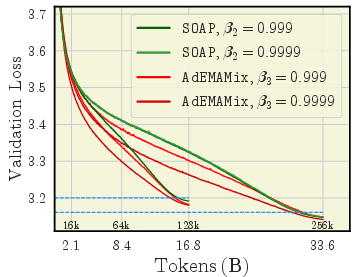
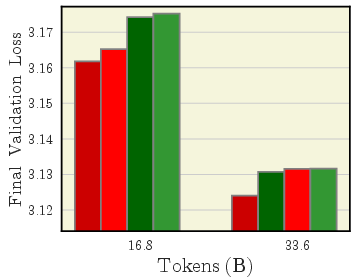
- AdEMAMix is a star performer
- It consistently ranks among the best across many settings and training lengths.
- For big models and long runs, it often wins.
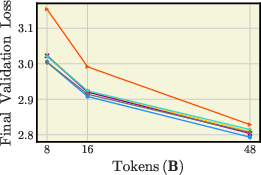
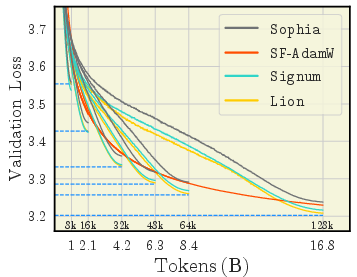
- Batch size changes who the winners are
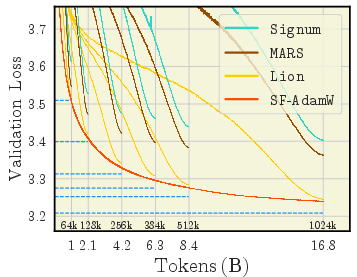
- With small batches: sign-based methods (Lion, Signum) and MARS don’t do great; Sophia can even become unstable.
- With large batches: Lion, Signum, MARS, and Prodigy improve a lot and can beat AdamW in shorter runs. AdEMAMix still stays strong.
- At 720M parameters with 1M-token batches: AdEMAMix and MARS are top performers.
- D-Muon > Muon (because of proper weight decay)
- A version of Muon called D-Muon, which applies weight decay correctly, performs clearly better than the original Muon.
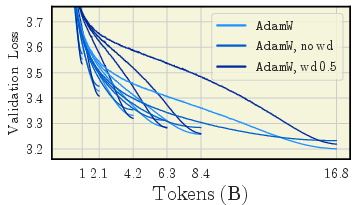
- Weight decay really matters
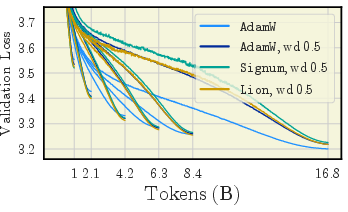
- For short training: using a larger weight decay (around 0.5) can noticeably improve results.
- For long training: a moderate weight decay (around 0.1) works best.
- No weight decay is usually a bad idea; performance gets worse, especially as training goes longer.
- Using “decoupled” weight decay (the modern, correct way) is important, especially for some optimizers like Signum.
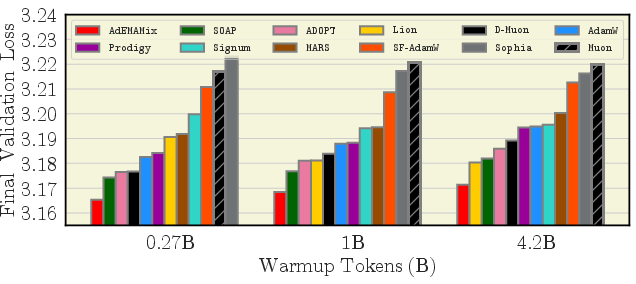
- Warmup is optimizer-dependent
- A longer warmup helps certain methods (Signum, Sophia, SF-AdamW), and can even make Lion surpass AdamW in some cases.
- Other methods do fine with shorter, standard warmups.
- Learning rate schedules: cosine usually wins
- Cosine scheduling tended to work best across optimizers.
- A few exceptions exist (e.g., Muon sometimes liked WSD), but cosine was the safest choice overall.
- Learning rate sensitivity
- Many optimizers had a clear “sweet spot” for learning rate found in short runs that still worked well in longer runs.
- Sign-based methods and Sophia often diverged (crashed) if the learning rate was set too high.
- MARS was unusually stable across a wide range of learning rates.
- They trained 2,900 models and spent about 30,000 GPU hours
- That’s a lot—so the comparisons are broad and careful.
- All code and configs are released for reproducibility.
What does this mean going forward?
- For people training LLMs:
- If you want a strong and reliable choice, try AdEMAMix.
- If you use very large batches, consider Lion, Signum, MARS, or Prodigy—they can become very competitive.
- Don’t forget weight decay: use about 0.5 for short runs, and about 0.1 for long runs. Avoid zero.
- Prefer cosine learning rate schedules unless you have a strong reason not to.
- If you use Muon, use D-Muon instead (it fixes important weight decay behavior).
- Tune warmup length based on the optimizer; longer warmup can help some methods a lot.
- For researchers:
- Batch size has a big effect on which optimizer looks best—future papers should report results across batch sizes.
- Stability issues (like Sophia’s divergence at small batches/long runs) are important to address.
- Weight decay design (and correct implementation) strongly shapes outcomes—don’t overlook it.
- The open-source benchmark provides a fair playground to test new ideas and make solid comparisons.
Overall, this paper gives a clear, up-to-date map of which optimizers work best for LLM pretraining in different situations, and it offers practical advice backed by large, careful experiments.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper and could guide future research:
- Scaling to frontier LLMs: Results are limited to dense models up to 720M parameters and a single 520M MoE; it remains unknown whether optimizer rankings and hyperparameter recommendations hold for 1–70B+ parameter models and modern large MoEs (varying experts, capacity factor, routing, load-balancing).
- Sequence length generality: All experiments use sequence length 512; the impact of longer contexts (2k–32k+), curriculum of context length, and positional encoding choices on optimizer stability and performance is not evaluated.
- Dataset and domain coverage: Benchmarks focus on a FineWeb subset with GPT-2 tokenization; transferability to other corpora (e.g., The Pile, C4, multilingual/web/code mixtures), tokenizers (SentencePiece/BPE sizes), and data quality regimes (dedup levels, contamination) is unknown.
- Downstream performance correlation: The study centers on validation loss; how optimizer choice affects downstream zero-shot/few-shot tasks, calibration, and robustness—and how well loss improvements predict downstream gains across optimizers—remains open.
- Statistical robustness: Variance across random seeds, data orders, and initialization seeds is not reported; ranking stability under multi-seed evaluation and confidence intervals is unquantified.
- Wall-clock and systems metrics: There is no systematic comparison of step-time, throughput, memory footprint, and communication overhead (e.g., SOAP preconditioning cost, Muon orthogonalization steps, D-Muon communication efficiency). Compute-to-quality Pareto analyses are missing.
- Tuning budget fairness: The equivalence of search budgets and search spaces across optimizers is unclear; ranking sensitivity to tuning budget, search strategy (manual vs. automated), and hyperparameter priors is not analyzed.
- Hyperparameter transferability: While tuned near Chinchilla-optimal and reused, a systematic study of hyperparameter transfer across model sizes, batch sizes, datasets, and training horizons is missing; guidelines or scaling laws (e.g., for betas) are not formalized.
- Very long-horizon training: Results extend to 16.8–33.6B tokens for 124M and limited horizons for larger models; optimizer ranking at substantially longer horizons (compute-optimal for modern scaling laws) is unknown.
- Learning-rate schedules: Only cosine, linear, and WSD are studied; effects of other schedules (e.g., OneCycle, step, exponential, sqrt decay, warm restarts) and end-LR ratios beyond 0.01× are not explored.
- Warmup design space: Warmup experiments are linear and mostly at 124M; the benefits of alternative warmup shapes (cosine/exponential), per-parameter warmup, or warmup scheduling at larger scales remain untested.
- Weight decay policy: Although decoupled weight decay is ablated, the paper does not assess layer-wise WD, parameter-group exclusions (e.g., norms/bias/embeddings), WD schedules, or optimizer-specific WD formulations; downstream and calibration effects of large WD are unclear.
- Gradient clipping specifics: The type (global vs per-parameter/layer), thresholds, and adaptive strategies for clipping—and their optimizer-specific impacts—are not systematically mapped.
- Precision and numerics: The interaction between optimizer choice and numerical formats (bf16/fp16/fp8), dynamic loss scaling, and kernel implementations is not evaluated; ranking stability under mixed precision is unknown.
- MoE-specific behaviors: Only one MoE configuration is tested; optimizer effects on router dynamics (entropy, load balance), capacity factors, expert counts, and expert dropout are not studied.
- Schedule-free/continual training: Schedule-free optimizers are not evaluated in true continual pretraining scenarios (non-decaying LR, non-stationary data); their practical advantages remain unquantified.
- Broader optimizer coverage: Popular large-batch or memory-efficient methods (e.g., LAMB, AdaFactor, Adagrad variants, 8-bit optimizers) are absent; it is unknown how they compare under the standardized setup.
- Robustness and failure modes: While some divergences (e.g., Sophia) are noted, there is no systematic “stability map” of failure regions (lr, betas, batch, warmup, clip) per optimizer or standardized mitigation strategies.
- Interpretability of differences: No mechanistic analysis (e.g., gradient-noise scale, curvature/Hessian spectra, sharpness, update direction statistics) is provided to explain why certain optimizers (e.g., AdEMAMix) outperform others across regimes.
- Architecture sensitivity: Results are for a specific Llama-like, RMSNorm, SwiGLU, RoPE setup; sensitivity to architectural variants (LayerNorm placement, activation functions, attention kernels, normalization types) is not explored.
- Data ordering and curriculum: The influence of data shuffling, token repetition, curriculum (by length/difficulty), and epoching strategies on optimizer performance is not studied.
- Objective variations: The conclusion that z-loss “has little impact” is based on limited ablation; other objectives (label smoothing, entropy regularization, auxiliary losses) and their optimizer interactions are largely unexplored.
- Per-parameter-group settings: Beyond a Signum WD fix, there is no thorough exploration of per-layer/per-group LR, momentum, or WD (e.g., embedding vs attention/MLP vs norms) and their effect on optimizer rankings.
- Compute accounting granularity: Although compute cost is “accounted,” the paper does not provide standardized, reproducible wall-clock budgets or FLOP-normalized comparisons that jointly consider speed and quality across hardware/software stacks.
- Reproducibility across frameworks: Results are shown in one codebase; cross-framework replication (Megatron/DeepSpeed/OLMo/LLaMA recipes) to test sensitivity to fused kernels and implementation details is missing.
- Generalization across tasks: Only autoregressive LM pretraining is considered; transfer to masked LM, seq2seq, instruction tuning, or RLHF remains untested.
Collections
Sign up for free to add this paper to one or more collections.