OneSearch: A Preliminary Exploration of the Unified End-to-End Generative Framework for E-commerce Search
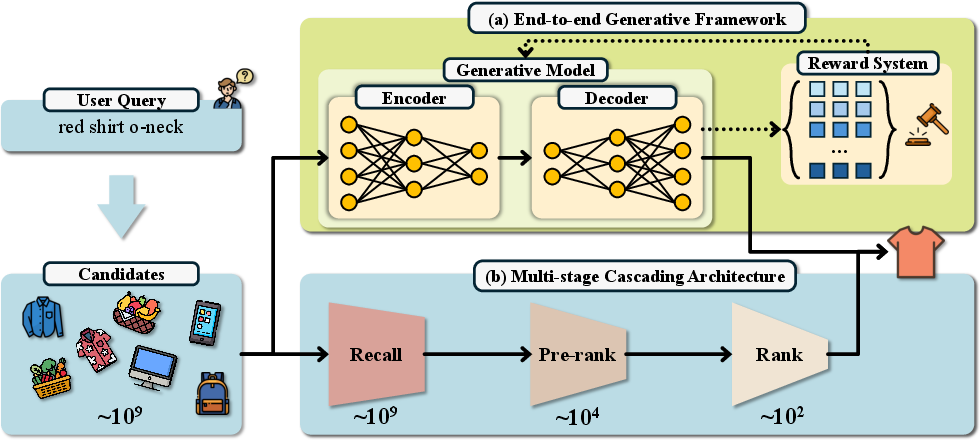
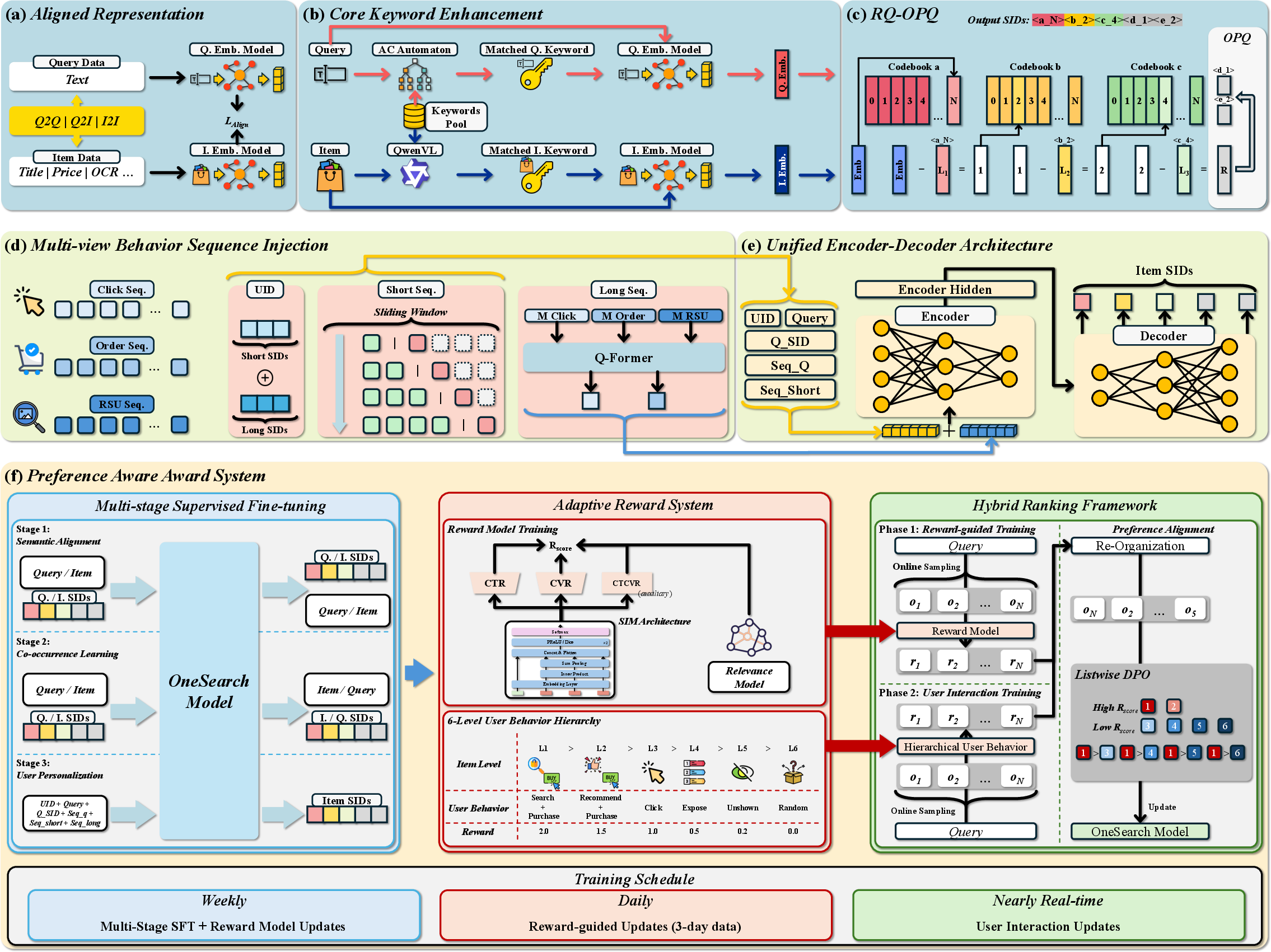
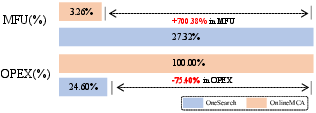
Abstract: Traditional e-commerce search systems employ multi-stage cascading architectures (MCA) that progressively filter items through recall, pre-ranking, and ranking stages. While effective at balancing computational efficiency with business conversion, these systems suffer from fragmented computation and optimization objective collisions across stages, which ultimately limit their performance ceiling. To address these, we propose \textbf{OneSearch}, the first industrial-deployed end-to-end generative framework for e-commerce search. This framework introduces three key innovations: (1) a Keyword-enhanced Hierarchical Quantization Encoding (KHQE) module, to preserve both hierarchical semantics and distinctive item attributes while maintaining strong query-item relevance constraints; (2) a multi-view user behavior sequence injection strategy that constructs behavior-driven user IDs and incorporates both explicit short-term and implicit long-term sequences to model user preferences comprehensively; and (3) a Preference-Aware Reward System (PARS) featuring multi-stage supervised fine-tuning and adaptive reward-weighted ranking to capture fine-grained user preferences. Extensive offline evaluations on large-scale industry datasets demonstrate OneSearch's superior performance for high-quality recall and ranking. The rigorous online A/B tests confirm its ability to enhance relevance in the same exposure position, achieving statistically significant improvements: +1.67\% item CTR, +2.40\% buyer, and +3.22\% order volume. Furthermore, OneSearch reduces operational expenditure by 75.40\% and improves Model FLOPs Utilization from 3.26\% to 27.32\%. The system has been successfully deployed across multiple search scenarios in Kuaishou, serving millions of users, generating tens of millions of PVs daily.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be directly actionable for future research.
- Data transparency and reproducibility: Provide full dataset specifications (query and item counts, time windows, language mix, category distribution, prevalence of long-tail queries/items, and cold-start proportions), train/validation/test splits, and sampling strategies used across SFT stages and reward-model training.
- Detailed evaluation protocol: Report comprehensive offline metrics (e.g., NDCG, MAP, recall/precision at multiple cutoffs, calibration metrics) beyond Recall@10/MRR@10, along with per-query breakdowns (short vs. long queries, head vs. tail queries, attribute-heavy vs. minimal queries) to evidence relevance and personalization.
- Statistical rigor of A/B tests: Document sample sizes, traffic allocation per scenario, confidence intervals, and exact statistical tests (including p-values) for all online metrics to substantiate “statistically significant” improvements.
- Latency and serving SLOs: Quantify end-to-end latency (mean, P95, P99), throughput, and memory footprint under production loads for constrained vs. unconstrained beam search, and compare to MCA across different search entry points (homepage, mall, detail page).
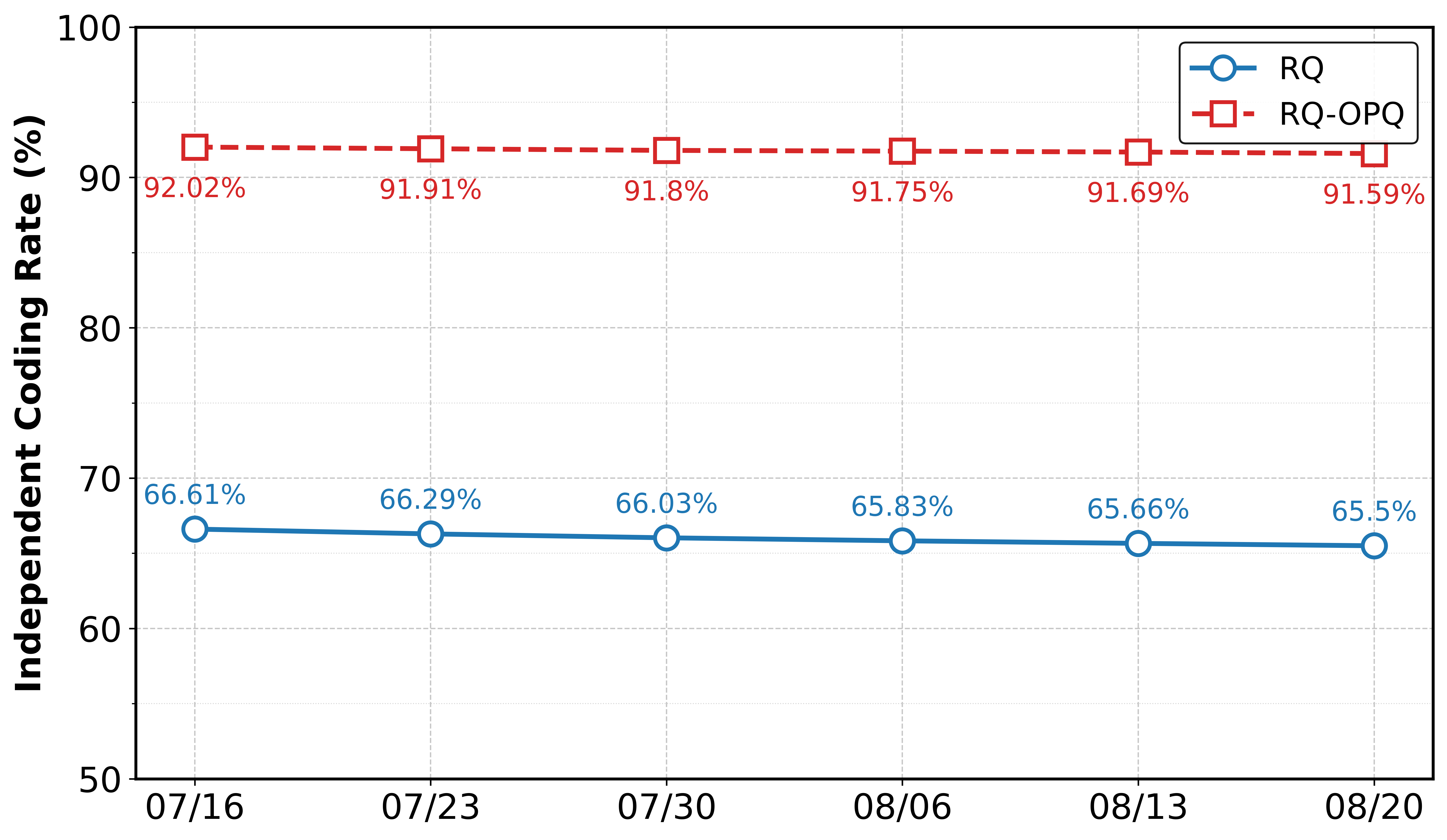
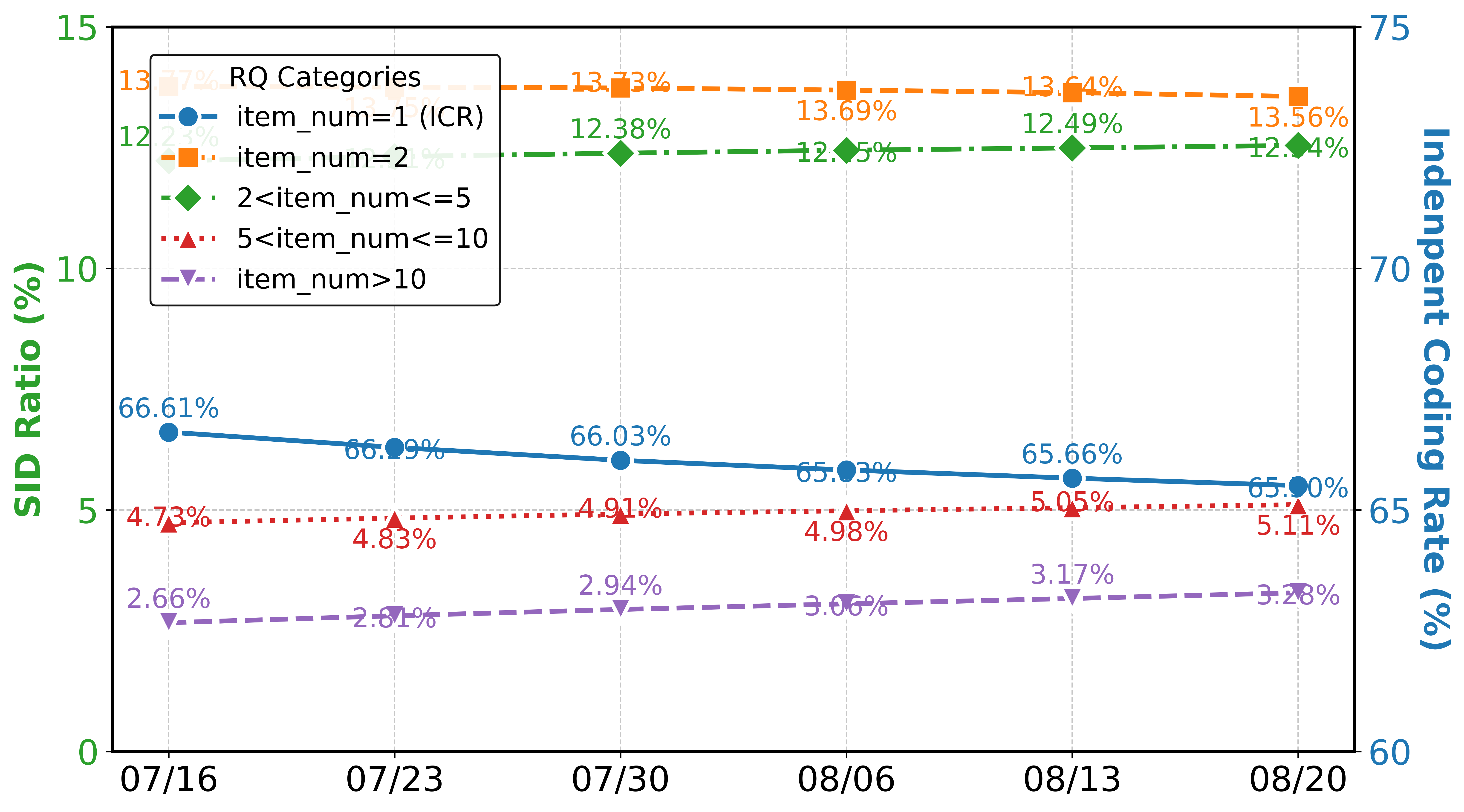
- SID-to-item resolution and collision handling: Specify how generated SIDs map to concrete items when multiple items share hierarchical SIDs, the role of OPQ codes in disambiguation, fallback strategies for invalid/unavailable/out-of-stock items, and tie-breaking rules in list construction.
- Vocabulary/codebook dynamics under catalog churn: Describe incremental or online codebook update strategies, SID stability under frequent item additions/removals (e.g., large shopping festivals), and mechanisms to avoid catastrophic remapping or drift.
- Missing attribute taxonomy and NER reliability: The paper references “18 structured attributes” but does not enumerate them. Provide the exact attribute list, NER model details, accuracy/coverage per attribute, domain-specific errors (e.g., multi-attribute conflicts), and the impact of NER failures on KHQE effectiveness.
- Keyword extraction robustness: Evaluate Qwen-VL’s keyword extraction error rates, domain shift (e.g., noisy seller content, multi-lingual listings), adversarial/spam susceptibility, and performance under incomplete or image-only item content.
- Query understanding limits: Assess handling of negation (e.g., “not brand X”), compositional constraints (color + size + material), typos/code-switching/morphological variants, and rare attribute values; specify any explicit constraint-checking beyond SID matching.
- Cold-start performance: Include targeted experiments for cold-start users/items/queries, quantify gains vs. MCA, and analyze the impact of default behavior sequences (popularity-based) on personalization quality and popularity bias.
- Bias and debiasing in reward signals: CTR/CVR-based rewards are exposure-biased. Introduce counterfactual estimators (e.g., IPS/DR), position bias correction, and temporal drift handling; compare calibrated vs. debiased rewards and measure fairness impacts (e.g., across sellers/categories).
- Diversity and serendipity: Analyze whether end-to-end generation reduces catalog diversity or increases homogeneity; introduce and report diversity metrics (e.g., intra-list diversity, coverage) and trade-offs with CTR/CVR.
- Safety and business constraints: Clarify how OneSearch enforces business rules (e.g., seller fairness, regulatory constraints, prohibited items), avoids unsafe generations, and integrates inventory/price changes and deduplication in real time.
- Multi-modal utilization gaps: Beyond keyword extraction via Qwen-VL and OCR, the generative model does not appear to ingest image/video features end-to-end. Explore multi-modal encoders for item and query representations and quantify gains.
- Ablation and sensitivity analyses: Present ablations isolating the impact of KHQE (keyword enhancement, RQ layers, L3-balanced k-means), OPQ code size choices, short vs. long sequence injections, and reward model weights (including the amplified relevance term; 10× λ4), with sensitivity curves.
- Constrained vs. unconstrained decoding: Provide empirical comparisons on accuracy, relevance, invalid SID rate, diversity, and latency trade-offs across beam widths and constraints; define fallback mechanisms for unconstrained decoding.
- SFT stage interdependencies: Detail training schedules, hyperparameters, sample sizes per stage, curriculum effects, and convergence diagnostics; quantify how each SFT stage contributes to final relevance/personalization and whether skipping stages degrades performance.
- Stability and continual learning: Investigate catastrophic forgetting and stability when updating models/reward signals, and propose/measure continual learning strategies under shifting user behavior and catalog seasonality.
- Reward model architecture and training details: Specify the three-tower model architecture, features, hyperparameters, negative sampling strategy, and the exact computation of the offline relevance score SRel; compare using the MCA ranking model as a proxy vs. bespoke reward training.
- List-wise DPO training details: Define δ, α, reference model selection, negative set construction, and training stability; report the impact of list-wise DPO vs. pairwise alternatives on ranking quality and robustness.
- Generalization across domains and languages: Evaluate transferability to other marketplaces, languages, and verticals with different attribute structures; analyze adaptation costs and performance under cross-domain deployment.
- Privacy and compliance: Discuss storage/retention of long behavior sequences, user-ID construction from behavior, opt-out mechanisms, and compliance with privacy regulations; quantify privacy-preserving alternatives (e.g., on-device computation, federated learning).
- Failure case analysis: Provide qualitative and quantitative analyses of typical failure modes (e.g., attribute mismatch, brand mismatches, overfitting to recent clicks, poor tail-query handling) to guide targeted mitigation strategies.
- MFU/OPEX claims: Define Model FLOPs Utilization explicitly (measurement method, baselines, hardware specs) and decompose OPEX savings (compute, storage, network, engineering overhead) to enable independent validation and replication.
- Benchmarking vs. strong baselines: Compare OneSearch end-to-end performance against state-of-the-art GR baselines tailored to search (e.g., GRAM, GenR-PO) and strong MCA variants, using unified protocols and identical traffic slices.
- Operational integration details: Document caching strategies, user-state freshness, consistency across microservices, failure recovery, and monitoring/alerting for production deployment to inform reliability engineering practices.
Collections
Sign up for free to add this paper to one or more collections.