- The paper demonstrates that adversarial motion priors (AMP) can enable lifelike walking in aesthetically constrained humanoids by overcoming stability challenges.
- It details a sim-to-real pipeline using domain randomization, motion retargeting with CMU Mocap, and PD controllers to manage a disproportionate center of mass.
- The reinforcement learning approach shows robust performance in dynamic environments, combining visual appeal with functional stability for entertainment robotics.
Learning to Walk in Costume: Adversarial Motion Priors for Aesthetically Constrained Humanoids
Introduction to Entertainment Humanoids
The paper introduces a reinforcement learning-based locomotion system tailored for Cosmo, a custom humanoid robot uniquely designed for entertainment applications. Unlike traditional humanoids, robots in the entertainment sector face significant challenges due to design choices that prioritize aesthetics over functional stability. These challenges include disproportionate body parts that affect the center of mass, limited sensing capabilities due to aesthetic shells, and restricted joint mobility due to protective coverings.
Cosmo embodies these challenges by lacking an onboard vision system and having an elevated center of mass, making it an ideal case study for testing conventional locomotion methods against learning-based alternatives. By leveraging Adversarial Motion Priors (AMP), the study aims to enable Cosmo to learn natural-looking movements while maintaining physical stability, addressing balancing, walking, and safe deployment constraints via tailored domain randomization techniques.

Figure 1: Cosmo: an entertainment humanoid robot with covers designed for a blockbuster movie. (Left): CAD Design. (Top): Using Isaac Gym's massively parallelized environments to train with different styles and terrain. (Bottom): Sim-to-Real demonstration of natural walking (see supplementary video).
Methods and Techniques
Motion Retargeting
Due to the morphological differences between humans and robots like Cosmo, motion retargeting is necessary to adapt human movement data to the robot's kinematic constraints. The paper utilizes the Rokoko plugin in Blender for this purpose, employing the CMU Mocap Dataset to build custom animation rigs matching Cosmo's proportions.
Imitation Learning with AMP
The paper frames the locomotion problem as a Partially Observable Markov Decision Process (POMDP) and aims to learn a policy that maps observations to actions. The learning process leverages AMP, which incorporates a discriminator network to differentiate motions from reference datasets, driving the policy to generate lifelike performance while ensuring task completion and physical constraint adherence.
By incorporating AMP with a comprehensive sim-to-real transfer pipeline that includes domain randomization and hardware tuning, the study tackles significant mechanical limitations and entertainment-focused design constraints.
Simulation and Domain Randomization
In addressing Cosmo's instability due to its large head, the authors employed NVIDIA's Isaac Sim for creating detailed simulations that analyze stability based on the center of mass and foot-ground contact points. They applied domain randomization strategies in training to ensure robustness against dynamic uncertainties and sensor noise.

Figure 2: Cosmo visualization: (left) arm range of motion and internal vs. exterior housing comparison; (right) mass distribution analysis highlighting the disproportionate head mass.
Practical Implementation
For hardware implementation, Cosmo employs Westwood Robotics actuators that enable precise torque control using internal sensing. The locomotion control leverages low-level PD controllers for translating policy to actuation. This setup ensures stable performance under the atypical mass distribution constraints posed by Cosmo's design.

Figure 3: Sim-to-Real pipeline: (a) Retargeting from diverse data sources, (b) Training, (c) Validation, (d) Deployment.
Experimental Results
Stability and Flexible Motion
The trained policy successfully demonstrates stable standing and walking, with various motion styles from basic standing to expressive walking exhibiting dynamic human-like qualities. The policy efficiently handles real-world physical constraints through AMP-influenced reinforcement learning (Figure 2).


Figure 4: AMP policies with styles for balancing, model-based walking and walking with swagger.
The study achieves robust balancing capabilities despite Cosmo's challenging morphology, using domain randomization to bridge the sim-to-real gap. The resulting locomotion and disturbance rejection validate the efficacy of AMP in producing human-like adaptability in aesthetic-centric designs.
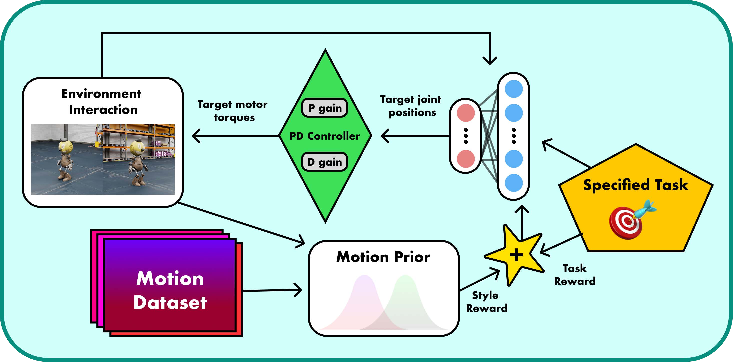
Figure 5: Joint tracking and disturbance rejection. Shaded regions indicate disturbance periods.
Conclusion
This research effectively demonstrates the potential of learning-based frameworks, particularly Adversarial Motion Priors, to address unique stability and motion challenges in aesthetically constrained humanoid robots. By showcasing how AMP-guided reinforcement learning can surpass conventional control approaches, this study opens new possibilities for combining aesthetic appeal with functional performance in entertainment robotics.
Although prioritizing stability and expressiveness over agility, the approach aligns optimally with entertainment applications where visual plausibility and hardware preservation are critical. Future work could focus on comparative analyses with traditional controllers and explore broader applicability across diverse morphologies within the entertainment sector.
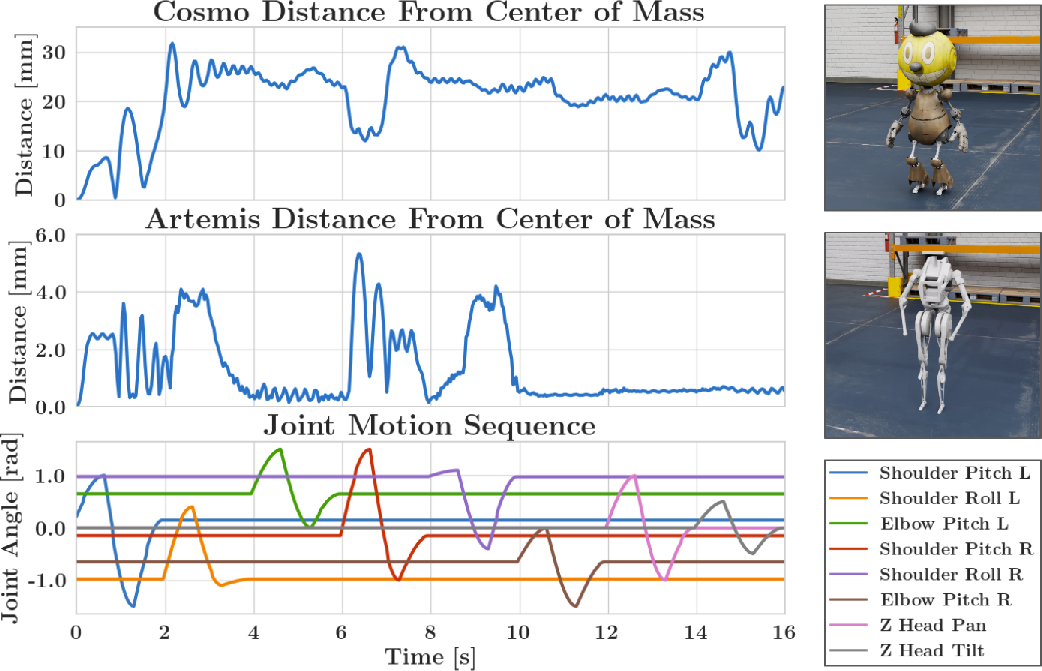
Figure 6: Joint command tracking, body-local velocity and joint torque tracking for natural walking.