- The paper introduces H2OT, a novel hierarchical framework that prunes and recovers pose tokens in video transformers for efficient 3D human pose estimation.
- It employs a pyramidal token pruning strategy using methods like TPS and TRI, achieving up to 66 FPS with negligible accuracy loss.
- The approach significantly reduces computational cost by lowering FLOPs by up to 57.4% while maintaining state-of-the-art performance.
The paper introduces H2OT, a hierarchical, plug-and-play pruning-and-recovering framework designed to improve the efficiency of transformer-based 3D human pose estimation from videos. The approach systematically reduces computational redundancy in Video Pose Transformers (VPTs) by dynamically pruning pose tokens and subsequently recovering full-length sequences, enabling significant acceleration without compromising estimation accuracy.
Motivation and Background
Transformer-based architectures have established state-of-the-art performance in video-based 3D human pose estimation due to their capacity for modeling long-range dependencies. However, the quadratic complexity of self-attention with respect to the number of tokens (i.e., video frames) results in prohibitive computational costs, especially for long sequences (e.g., 243–351 frames). This computational burden limits the deployment of VPTs in resource-constrained environments.
Existing VPTs typically retain the full-length sequence throughout all transformer blocks, leading to redundant computation, as adjacent frames often contain highly similar pose information. Prior work (e.g., HoT) introduced a non-hierarchical hourglass paradigm for token pruning and recovery, but lacked a pyramidal, hierarchical design and imposed additional inference overhead.
H2OT Framework Overview
H2OT extends the hourglass paradigm by introducing a hierarchical, pyramidal pruning strategy, forming a "trophy-shaped" token flow through the network. The framework consists of two core modules:
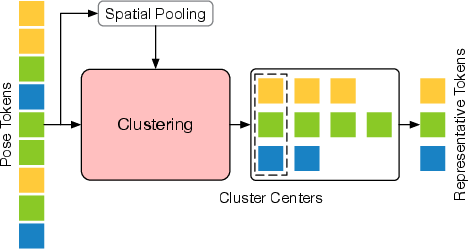
- Token Pruning Module (TPM): Progressively prunes pose tokens at multiple stages, selecting a small set of representative tokens to reduce redundancy.
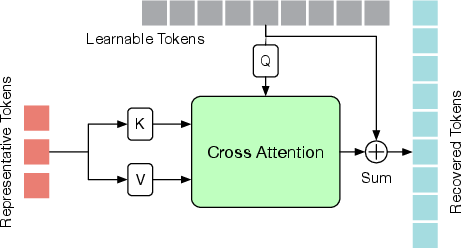
- Token Recovering Module (TRM): Recovers the full-length sequence from the pruned tokens, enabling dense 3D pose estimation for all frames.
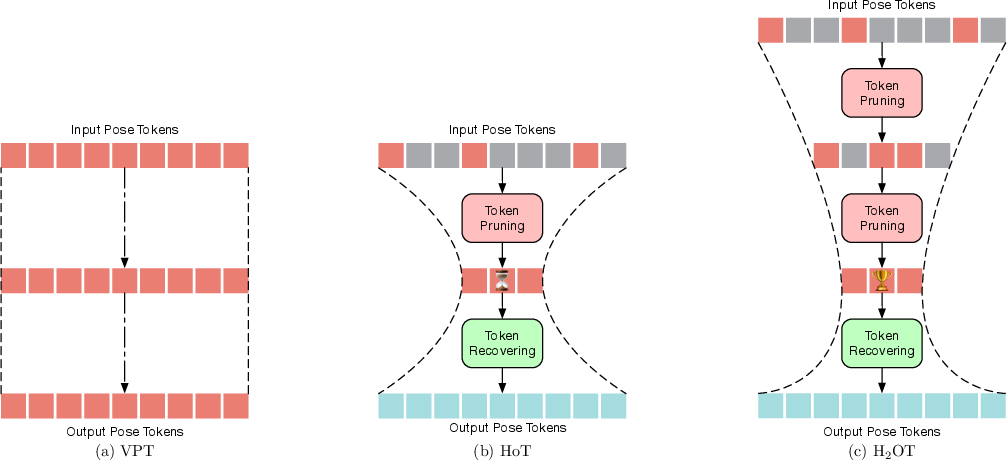
Figure 1: Comparison of VPT paradigms: (a) rectangle (full sequence), (b) hourglass (single-stage pruning), (c) H2OT's hierarchical pyramidal pruning.
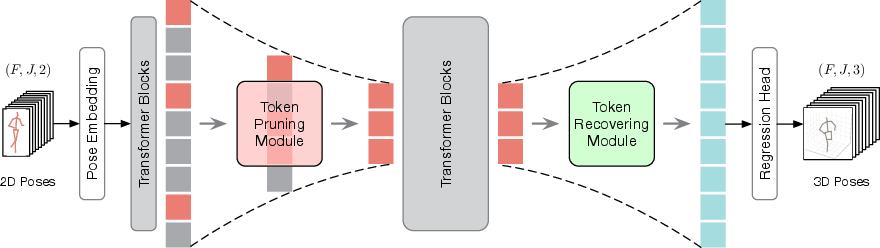
Figure 2: H2OT architecture overview, showing the integration of TPM and TRM within a standard VPT pipeline.
Token Pruning Module (TPM)
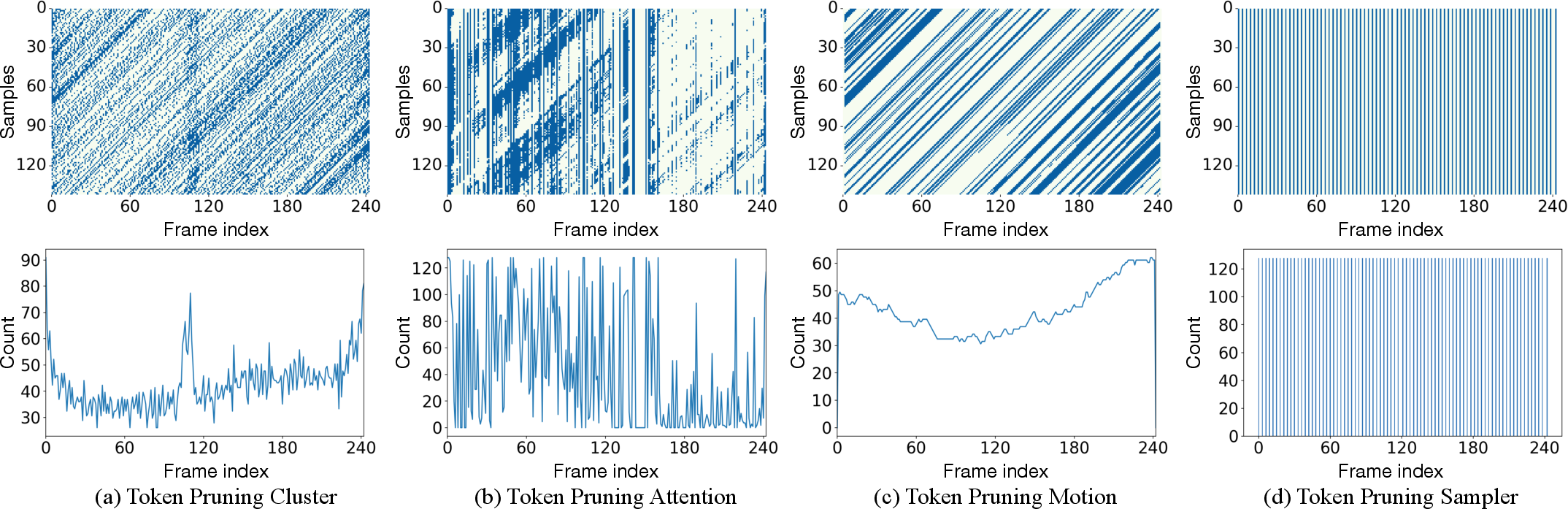
TPM is responsible for reducing the number of tokens in the intermediate transformer blocks. The hierarchical design prunes tokens at multiple depths, creating a pyramidal feature hierarchy. Four token selection strategies are explored:
Empirical analysis demonstrates that TPS, when combined with efficient recovery, achieves the best trade-off between speed and accuracy, as it is parameter-free and preserves token order for fast interpolation.
Token Recovering Module (TRM)
TRM restores the full-length sequence required for dense 3D pose estimation. Two recovery strategies are proposed:
Integration with VPT Pipelines
H2OT is designed to be model-agnostic and can be integrated into both seq2seq and seq2frame VPT pipelines:
- Seq2seq: TPM prunes tokens after initial transformer blocks; TRM recovers the full sequence before the regression head, enabling efficient, dense 3D pose estimation.
- Seq2frame: Only TPM is used; the center frame's token is always retained to ensure accurate regression for the target frame.
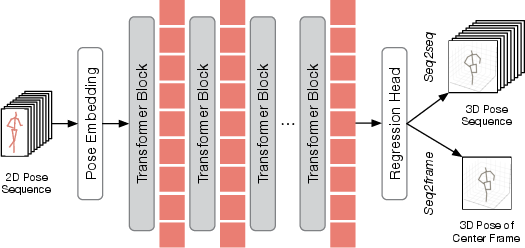
Figure 5: Standard VPT architecture, highlighting the insertion points for TPM and TRM.
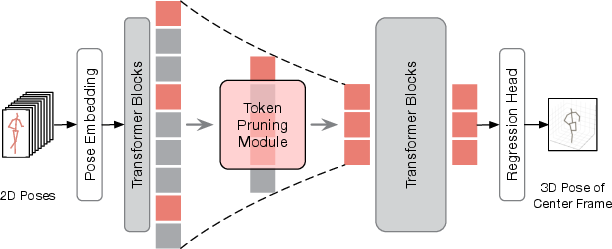
Figure 6: H2OT applied to the seq2frame pipeline, with TPM selecting representative tokens and regression performed on the center frame.
Empirical Evaluation
Ablation Studies
Comprehensive ablations on Human3.6M demonstrate:
Comparison with State-of-the-Art
H2OT, when integrated with leading VPTs (MHFormer, MixSTE, MotionBERT, MotionAGFormer), consistently reduces FLOPs by 36–63% and increases FPS by 44–88%, with no significant degradation in MPJPE. In some cases, accuracy is improved due to reduced overfitting to redundant frames.
- Human3.6M: H2OT w. MixSTE achieves 40.5mm MPJPE (vs. 40.9mm for baseline) with 57.4% fewer FLOPs.
- MPI-INF-3DHP: Comparable or improved PCK/AUC/MPJPE across all tested models.
Robustness and Generalization
- Low-FPS Scenarios: H2OT maintains competitive performance even as input FPS is reduced, confirming its robustness to varying temporal resolutions.
- Diffusion-based VPTs: H2OT is compatible with diffusion-based pose estimators, yielding similar efficiency gains.
Qualitative Analysis

Figure 8: Qualitative results on challenging in-the-wild videos, demonstrating accurate 3D pose estimation.
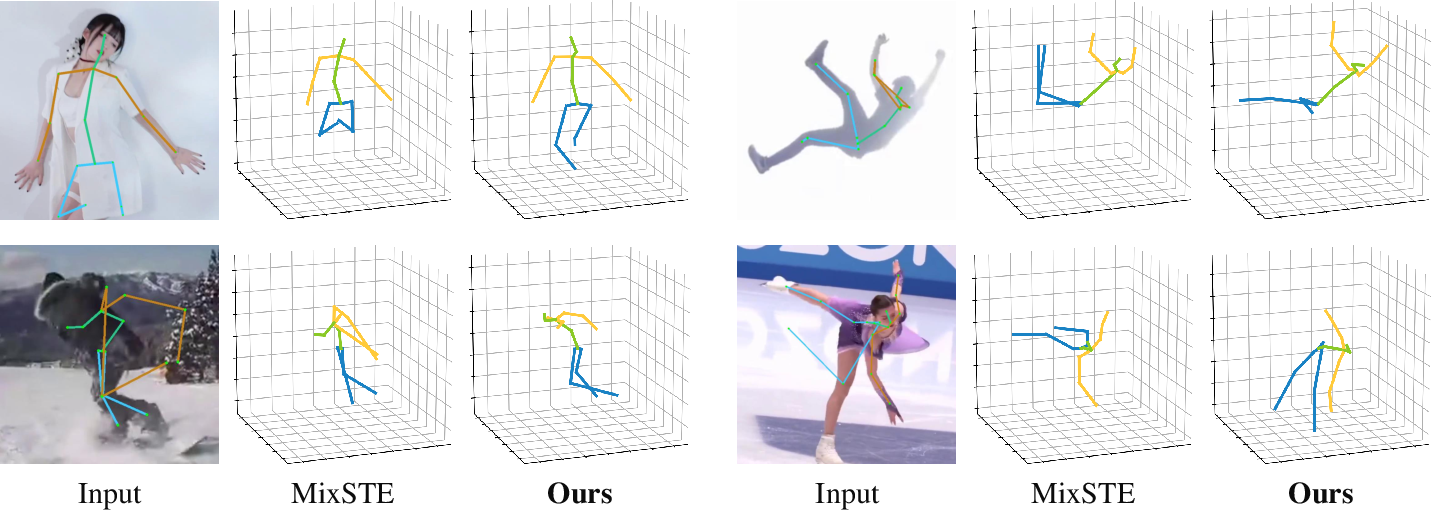
Figure 9: Failure cases in scenarios with occlusion, rare poses, or 2D detector errors.

Figure 10: Visualization of token selection and recovery: red frames/tokens are selected, gray are pruned, and 3D pose recovery is highlighted.
Implementation Considerations
- Computational Requirements: H2OT is compatible with standard PyTorch-based VPT implementations. The hierarchical pruning and recovery modules are lightweight and introduce minimal overhead.
- Hyperparameter Selection: The number and placement of pruning stages (r, b) can be tuned to balance speed and accuracy for specific deployment constraints.
- Deployment: The framework is suitable for real-time applications and resource-constrained devices, given its substantial reduction in memory and compute requirements.
Theoretical and Practical Implications
H2OT demonstrates that full-length token retention in VPTs is unnecessary for accurate 3D pose estimation. Hierarchical token pruning, combined with efficient recovery, enables significant acceleration and memory savings. This paradigm is generalizable to other sequence modeling tasks where temporal redundancy is prevalent.
The findings challenge the prevailing assumption that longer input sequences always yield better performance in transformer-based video models. Instead, careful token selection and recovery can yield equivalent or superior results with a fraction of the computational cost.
Future Directions
- Adaptive Pruning Policies: Learning data-dependent, task-specific pruning schedules could further optimize the trade-off between efficiency and accuracy.
- Extension to Other Modalities: The hierarchical pruning-recovery paradigm may be applicable to video action recognition, video captioning, or other dense prediction tasks.
- Integration with Efficient Attention Mechanisms: Combining H2OT with sparse or linear attention variants could yield further efficiency gains.
Conclusion
H2OT provides a principled, hierarchical approach to token pruning and recovery in video pose transformers, enabling substantial efficiency improvements without sacrificing accuracy. The framework is model-agnostic, robust across datasets and pipelines, and offers a practical solution for deploying high-performance 3D human pose estimation in real-world, resource-constrained environments.