- The paper introduces binary normalized layers that leverage dual precision (32-bit for training and 1-bit for inference) to maintain efficiency and performance.
- Experiments on convolutional and transformer models reveal that binary networks achieve similar validation accuracies and rapid convergence compared to traditional models.
- The approach offers significant memory reduction, enabling deployment on resource-constrained devices without sacrificing accuracy.
1 Bit is All We Need: Binary Normalized Neural Networks
Introduction
The paper presents a novel class of neural network models characterized by binary normalized layers, where all parameters are reduced to a single bit. This approach addresses the challenge of deploying large neural networks by drastically minimizing memory usage and enhancing computational efficiency. Compared to traditional models featuring 32-bit floating-point precision, these models employ binary normalized layers to maintain comparable performance while significantly reducing resource demands.
Binary Normalized Layers
Binary normalized layers are designed to operate with single-bit parameters, including kernel weights and biases. During training, these parameters maintain dual representations: full-precision 32-bit for gradient updates and 1-bit for forward computations. Through quantization, parameters transition from floating-point to binary using a threshold defined by the mean value, as formalized in Equation 1. This dual approach ensures effective training while achieving efficient, memory-reduced inference with entirely binarized parameters post-training.
Implementation of Binary Models
Image Classification with Convolutional Layers
Two binary convolutional models were configured for a multiclass image classification task using the Food-101 dataset, differing only in filter dimensions (3×3 and 5×5). All layers employ binary weights except activation functions, which are relu or softmax in classification layers. These models illustrate how binary normalized layers can preserve rapid convergence and comparable accuracy despite relying solely on 1-bit parameters.
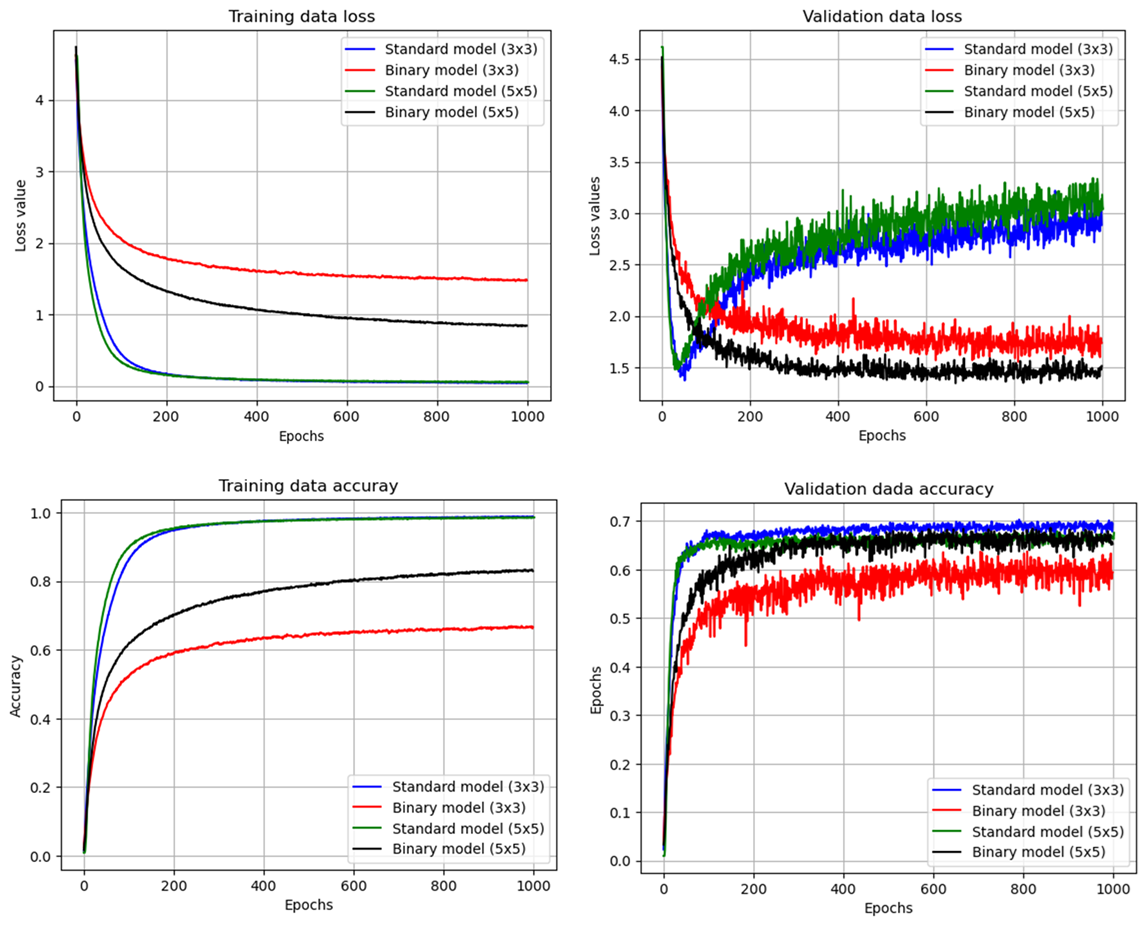
Figure 1: Training results of image classification problem with the convolutional models.
The paper configures binary transformer models for token prediction tasks using the WikiText-103-raw dataset. Two variants—small and large—are tested to evaluate performance relative to standard 32-bit models. The binary models integrated transformer blocks with attention mechanisms and MLP heads, demonstrating that increased model complexity can be supported even with reduced precision parameters.
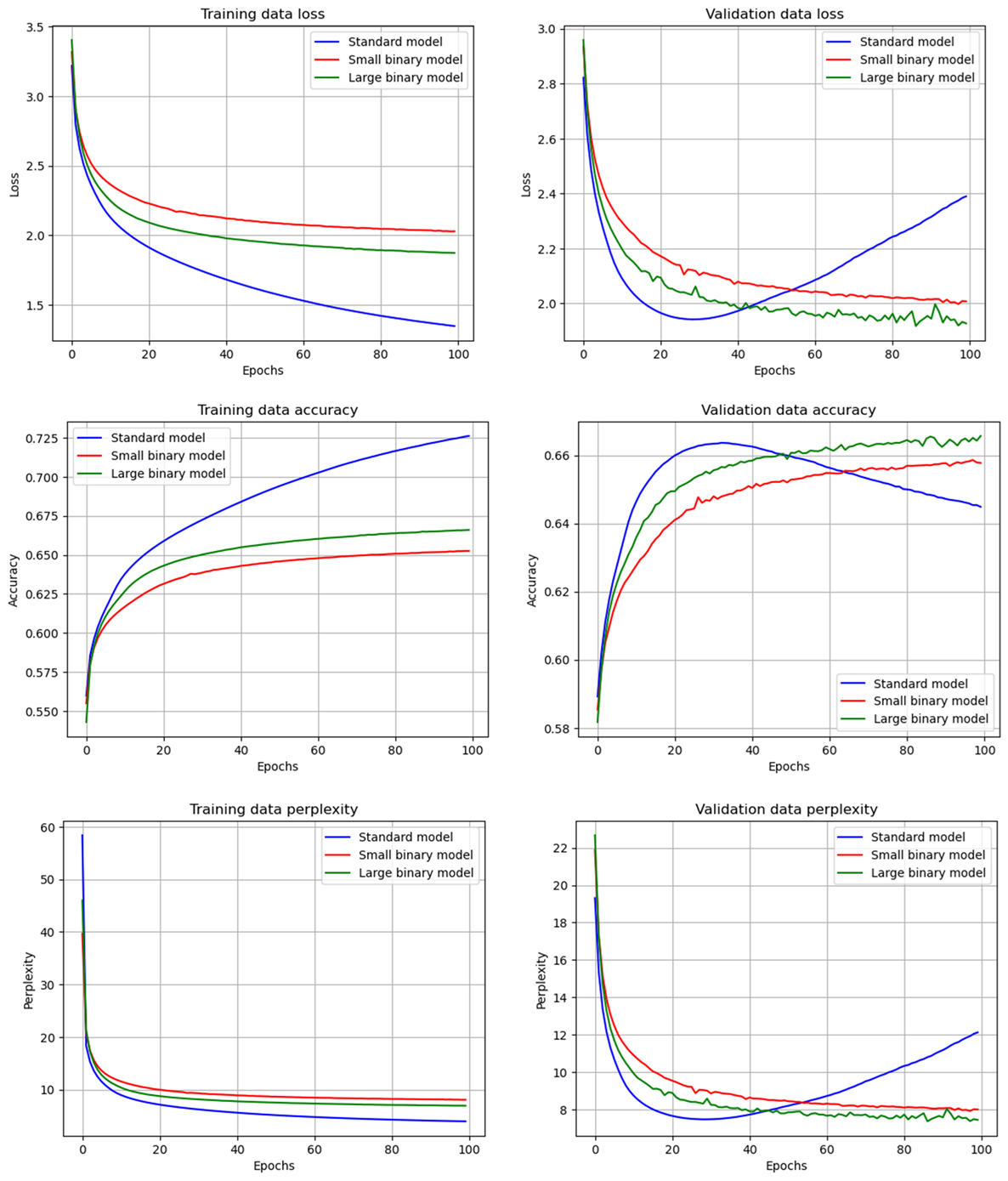
Figure 2: Training results of the language decoders.
The binary models demonstrate effective training stability and performance comparable to conventional models in both image classification and language decoder tasks. In the convolutional models, binary architectures achieved validation accuracies close to their float-based counterparts with minimal training epochs. The language decoding results showed similar performance between binary and standard models, with large binary models exceeding the standard model's metrics. These results indicate that scaling binary networks with more units allows them to match the efficacy of higher-precision models.
Implications and Future Work
The reduction in memory usage to 1/32 of traditional models presents substantial implications for deploying AI on resource-constrained devices, such as mobile platforms and CPUs. Additionally, this approach could lead to increased complexity in model architectures without the associated increase in computational burden. Future work may focus on refining activation precision and exploring efficient implementations of single-bit operations, which could further amplify these models' computational gains and extend their applicability to larger-scale AI tasks in embedded environments.
Conclusion
Binary normalized neural networks embody a significant step towards optimizing neural networks for practical deployment across diverse hardware environments. By reducing parameters to a single bit without compromising performance, these models promise a substantial leap in deploying AI technologies beyond data centers. Continued exploration into optimizing these models' training algorithms and activation precisions is anticipated to accelerate their adoption in scenarios where computational resources are limited, offering more expansive AI capabilities.