- The paper introduces the VC-measure to efficiently summarize the posterior for variable selection in Bayesian tree ensembles.
- It leverages a clustering-based thresholding strategy to improve precision and recall over traditional permutation methods.
- Empirical evaluations on Feynman equations validate that the VC-measure enhances F1 scores while reducing computational overhead.
Posterior Summarization for Variable Selection in Bayesian Tree Ensembles
Introduction
The challenge of variable selection is central to both statistical analysis and machine learning, particularly when dealing with nonparametric models where complexity is prevalant. Bayesian tree ensembles, notably Bayesian additive regression trees (BART) and their enhanced variants like DART, are well-regarded for their predictive prowess and interpretable metrics for determining variable importance. This paper dissects Bayesian tree ensemble methods into their foundational segments: model choice dependent on tree prior and posterior summary. It scrutinizes existing strategies such as permutation-based inference, priors that induce sparsity, and clustering-centric selection approaches. The research underscores the principal role of posterior summarization in determining variable importance, which is often underappreciated. Consequently, this paper introduces the VC-measure (Variable Count and its rank variant), a posterior summary that is computation-light and seamlessly integrates with diverse BART variants, providing a consistent enhancement in F1 scores across various prior types.
Methodology
The proposal introduces the VC-measure as a simplified yet effective approach to posterior summarization. This measure is designed to be a plug-in component, enriching the selection process for variables without necessitating additional sampling beyond routine model fitting. The VC-measure promises to circumvent the complications associated with the median probability model and the computational load demanded by permutation-based methods, establishing itself as an efficient alternative.
Upon empirical evaluation:
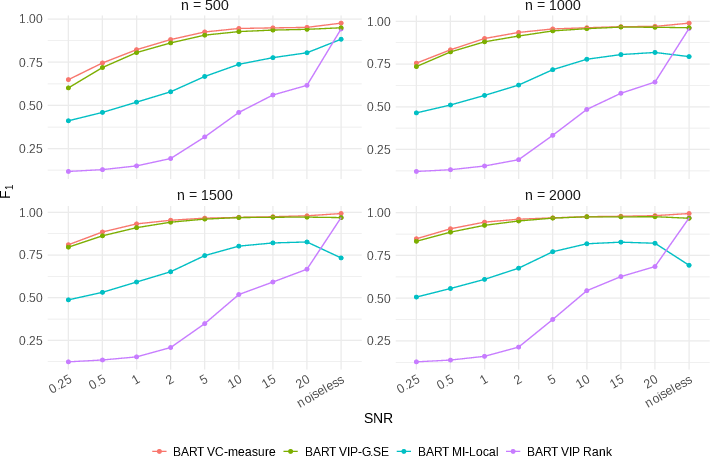
Figure 1: F_1 score comparison among variable importance measures for BART prior. Points indicate the average F_1 scores over 100 Feynman equations, each with 10 replicates.
The results consistently highlight the superiority of VC-measure compared to existing permutation-based methods. Notably, VC-measure demonstrates remarkable uniformity and resilience in improving the F1 metrics across both mainstream and niche tree ensemble priors.
Experimentation and Results
This research encompasses extensive experimental assessments using the Feynman Symbolic Regression Database which features a collection of 100 nonlinear equations, sampled multiple times to ensure data reliability and robustness. Across various configurations of signal-to-noise ratios (SNR) and sample sizes:
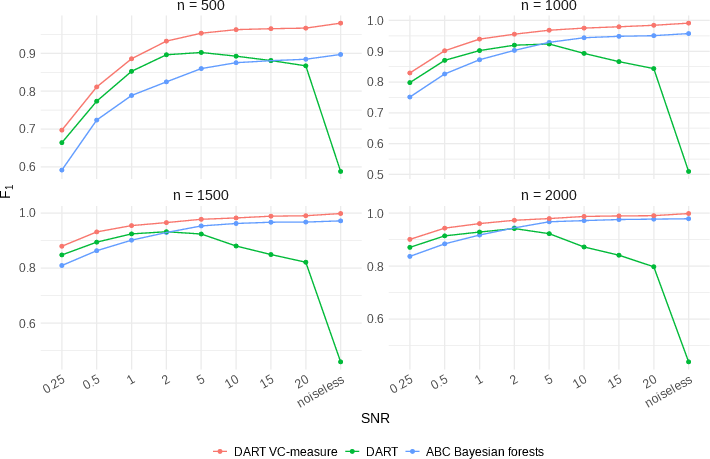
Figure 2: F_1 score comparison among MPVIP-suitable priors. Points indicate the average F_1 scores over 100 Feynman equations, each with 10 replicates.
Implementations of the VC-measure within DART configurations consistently led to improved selection metrics and demonstrated the benefit of the clustering-based thresholding strategy—a testament to its practicality and theoretical soundness. The VC-measure's performance shines through especially when contrasted with traditional permutation methods, offering a significant computational edge without compromising on precision.
Discussion
The research concludes by affirming that posterior summaries play a pivotal role in variable selection, a concept heralded through the successful implementation of the VC-measure. The study underscores the method’s utility in enhancing recall, precision, and overall analytical efficiency, establishing a balanced approach to the formidable dilemma of variable selection in tree ensemble models.
Conclusion
The integration of VC-measure within Bayesian tree ensemble frameworks marks a substantial shift in posterior summarization methodology. By harmonizing computational efficiency with precision and recall, this measure lays the foundation for refined variable selection processes, proving to be a valuable asset in statistical and machine learning applications. Future endeavors could focus on expanding this foundational approach to accommodate diversified datasets and advanced modeling scenarios, potentially widening the horizons of Bayesian data analysis.