Besting Good--Turing: Optimality of Non-Parametric Maximum Likelihood for Distribution Estimation
Published 9 Sep 2025 in math.ST, cs.IT, math.IT, stat.ME, and stat.TH | (2509.07355v1)
Abstract: When faced with a small sample from a large universe of possible outcomes, scientists often turn to the venerable Good--Turing estimator. Despite its pedigree, however, this estimator comes with considerable drawbacks, such as the need to hand-tune smoothing parameters and the lack of a precise optimality guarantee. We introduce a parameter-free estimator that bests Good--Turing in both theory and practice. Our method marries two classic ideas, namely Robbins's empirical Bayes and Kiefer--Wolfowitz non-parametric maximum likelihood estimation (NPMLE), to learn an implicit prior from data and then convert it into probability estimates. We prove that the resulting estimator attains the optimal instance-wise risk up to logarithmic factors in the competitive framework of Orlitsky and Suresh, and that the Good--Turing estimator is strictly suboptimal in the same framework. Our simulations on synthetic data and experiments with English corpora and U.S. Census data show that our estimator consistently outperforms both the Good--Turing estimator and explicit Bayes procedures.
The paper demonstrates that the NPMLE-based empirical Bayes estimator achieves optimal competitive regret, surpassing the Good–Turing method for distribution estimation.
It employs a parameter-free approach utilizing convex optimization and empirical Bayes to efficiently estimate discrete probability distributions from limited data.
Theoretical bounds and extensive empirical tests validate the method’s superior performance, offering robust solutions for high-dimensional, undersampled scenarios.
Optimality of Non-Parametric Maximum Likelihood for Distribution Estimation: Beyond Good–Turing
Introduction and Motivation
Estimating discrete probability distributions from limited samples is a central problem in statistics, information theory, and natural language processing. The Good–Turing estimator, originating from WWII cryptanalysis, has been a canonical method for this task, especially in the "rare events" regime where the alphabet size k is large relative to the sample size n. However, Good–Turing requires ad hoc smoothing and lacks a precise optimality guarantee. This paper introduces a parameter-free estimator based on non-parametric maximum likelihood estimation (NPMLE) and empirical Bayes, demonstrating both theoretical optimality and empirical superiority over Good–Turing in the competitive framework of Orlitsky and Suresh.
Problem Formulation and Competitive Framework
The estimation problem is formalized as follows: Given k-dimensional probability vector p⋆ and independent samples Ni∼Poi(npi⋆), the goal is to estimate p⋆ with minimal Kullback–Leibler (KL) risk. The classical minimax criterion is overly pessimistic for practical data, motivating the adoption of the competitive regret framework. Here, the estimator is compared to a permutation-invariant (PI) oracle, which knows p⋆ up to permutation. The regret is defined as
Reg(p)=p⋆∈Δksup[rn(p⋆,p)−rn(p⋆,pPI)],
where rn is the expected KL risk.
NPMLE-Based Empirical Bayes Estimator
The estimator leverages Robbins's empirical Bayes approach and the Kiefer–Wolfowitz NPMLE. The key steps are:
Empirical Bayes Model: Assume the Poisson means θi⋆=npi⋆ are i.i.d. from an unknown prior G on R+. The Bayes estimator for θ given Ni=y is
θG(y)=(y+1)fG(y)fG(y+1),
where fG(y) is the Poisson mixture marginal.
NPMLE for Prior Estimation: Estimate G by maximizing the likelihood over all probability measures on R+:
G=argGmaxi=1∑klogfG(Ni).
The solution is discrete with at most k atoms and can be efficiently computed via the Frank–Wolfe algorithm.
Distribution Estimation: The final estimator for p⋆ is
pi∝θG(Ni)+τ⋅1{Ni=0},
with a small regularization τ for unseen symbols.
Theoretical Guarantees and Separation from Good–Turing
The main theoretical result is that the NPMLE estimator achieves the optimal competitive regret up to logarithmic factors:
Reg(p)≤C(n−2/3∧nklog14(nk)).
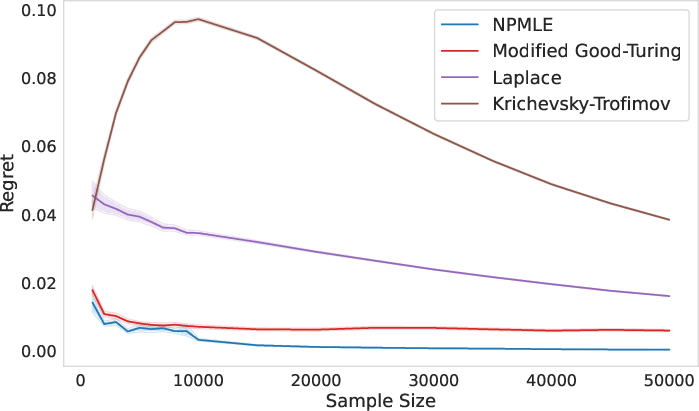
This matches the lower bound for any estimator up to polylogarithmic terms. In contrast, the Good–Turing estimator, even with smoothing and thresholding, is shown to be strictly suboptimal, with regret lower bounded by Ω((nlogn)−1/2) for large k.
Empirical Evaluation
Extensive experiments on synthetic and real data validate the theoretical findings:
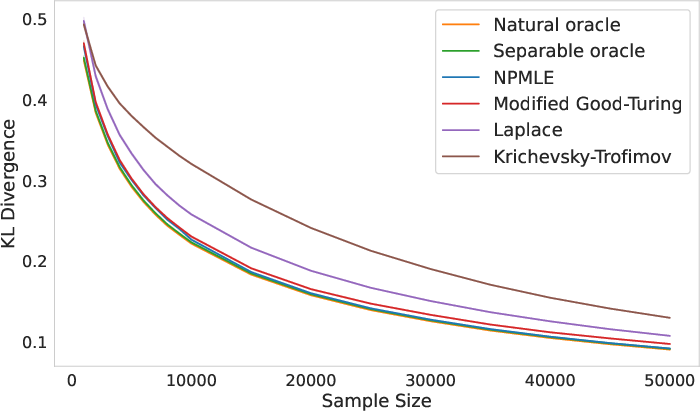
Synthetic Distributions: Across uniform, step, Zipf, and Dirichlet distributions, NPMLE consistently outperforms Good–Turing in KL regret, especially as n increases. For heavy-tailed distributions, NPMLE matches or surpasses Good–Turing as sample size grows.
Natural Language and Census Data: On English corpora (e.g., Hamlet, Lord of the Rings) and US Census datasets, NPMLE achieves lower KL regret than Good–Turing, Laplace, and Krichevsky–Trofimov estimators.
Out-of-Sample Generalization: A Bayes estimator pretrained on Hamlet generalizes well to other Shakespearean plays, often outperforming in-sample NPMLE and Good–Turing, but fails to generalize to unrelated corpora (e.g., Lord of the Rings), indicating the learned prior captures corpus-specific structure.
Figure 1: KL risk comparison across estimators, demonstrating the superior performance of NPMLE over Good–Turing and classical Bayesian estimators.
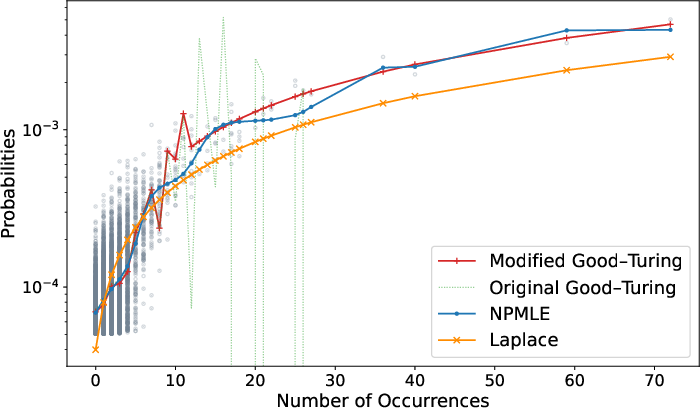
Figure 2: Smoothing effect of distribution estimators on Zipf data; NPMLE and Laplace estimators yield monotonic, strictly positive estimates, unlike Good–Turing.
Structural and Computational Properties
Monotonicity and Smoothing: NPMLE and Laplace estimators produce strictly positive, monotonic estimates as a function of empirical count, in contrast to the jagged, sometimes zero-valued Good–Turing estimates.
Computational Tractability: The NPMLE can be efficiently computed via convex optimization (Frank–Wolfe/vertex direction method), with support size O(n) independent of k.
Parameter-Free Operation: The estimator is essentially tuning-free; the regularization parameter for unseen symbols has negligible empirical impact.
Proof Techniques and Oracle Analysis
The regret analysis introduces a novel mean-field approximation, comparing the NPMLE estimator to a separable oracle (Bayes estimator with empirical prior) and then bounding the gap to the PI oracle. The analysis leverages recent advances in empirical Bayes theory and information-theoretic inequalities for permutation mixtures, yielding dimension-free bounds up to logarithmic factors.
Implications and Future Directions
Practical Impact: The NPMLE estimator provides a robust, parameter-free alternative to Good–Turing for distribution estimation in high-dimensional, undersampled regimes, with direct applications in language modeling, genomics, and ecology.
Theoretical Significance: The work establishes the competitive optimality of NPMLE in the Orlitsky–Suresh framework, clarifies the limitations of Good–Turing, and connects empirical Bayes, nonparametric likelihood, and compound decision theory.
Open Problems: Achieving truly dimension-free regret bounds (removing logarithmic dependence on k), extending the theory to the multinomial model, and developing NPMLE-based N-gram estimators for language modeling are identified as promising directions.
Conclusion
This paper rigorously demonstrates that the NPMLE-based empirical Bayes estimator not only bests the Good–Turing estimator in both theory and practice but also achieves the optimal competitive regret for discrete distribution estimation. The approach is computationally efficient, parameter-free, and broadly applicable, with strong implications for statistical learning in high-dimensional, data-scarce settings. The theoretical framework and empirical results set a new standard for distribution estimation and open avenues for further research in empirical Bayes and nonparametric inference.