- The paper demonstrates that shifting from narrow, task-specific models to versatile foundation models enhances robustness by integrating generalized knowledge from extensive datasets.
- It employs occupancy networks and neural rendering to boost spatial reasoning while leveraging cross-modal techniques for multi-sensor fusion in dynamic environments.
- The survey proposes a novel framework that addresses challenges such as real-time latency, safety, and comprehensive evaluation to improve autonomous navigation.
Foundation Models for Autonomous Driving Perception
Introduction
"Foundation Models for Autonomous Driving Perception: A Survey Through Core Capabilities" takes a vital step in comprehensively analyzing the shift from narrow task-specific deep learning models to versatile, foundation models in autonomous driving perception. These models mark a significant transformation, addressing major challenges like generalization, scalability, and robustness to environmental changes. This survey categorizes these capabilities into four essential pillars: generalized knowledge, spatial understanding, multi-sensor robustness, and temporal reasoning. By proposing a novel framework around these pillars, the paper provides a capability-driven guide for developing models that meet the demands of dynamic driving environments.
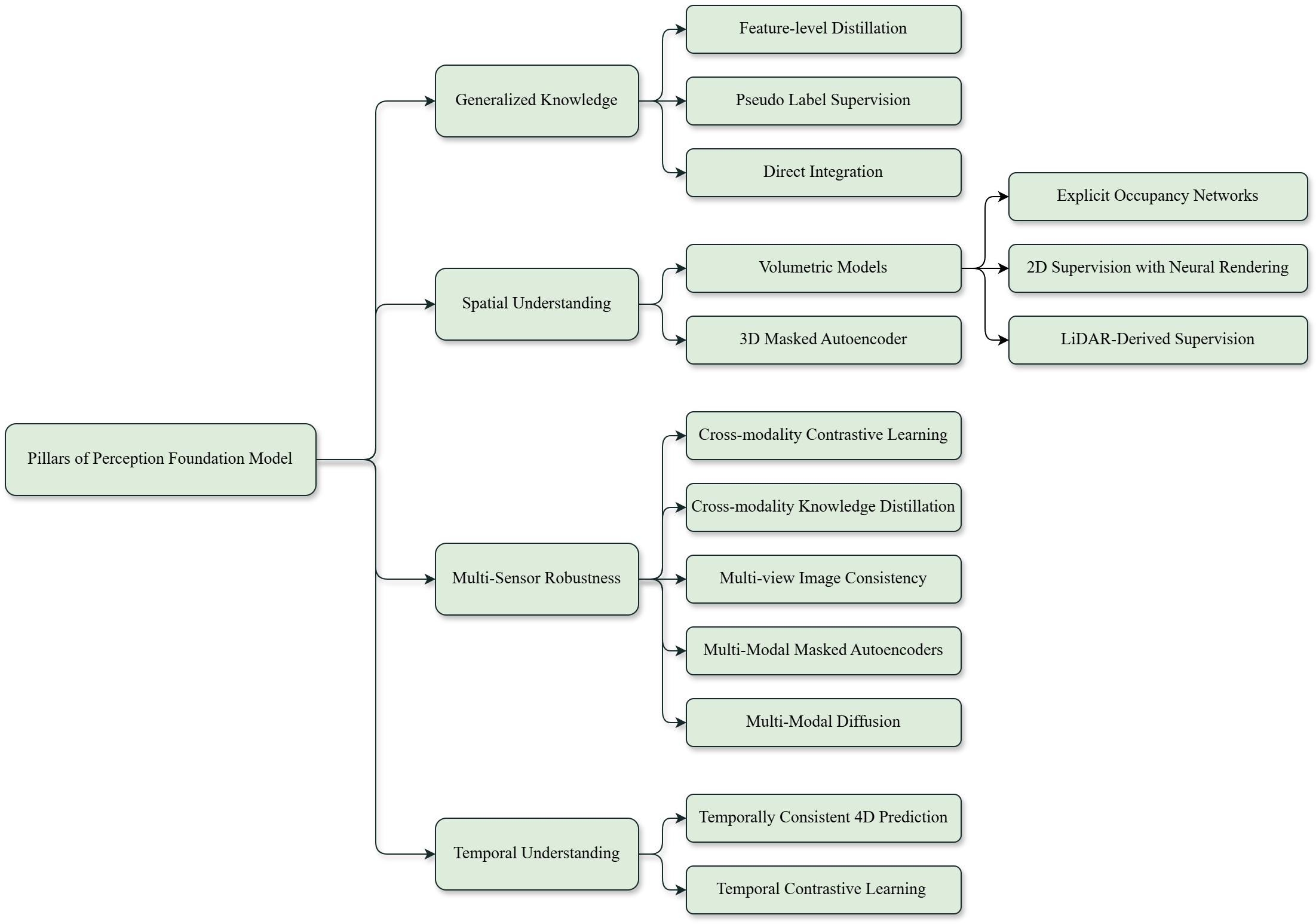
Figure 1: Overview of the four key pillars for foundation models in autonomous driving and the corresponding methods to achieve them.
Generalized Knowledge
Foundation models transition from being narrow and task-specific to becoming generalized architecture that leverage extensive datasets to cover a wide range of scenarios, including long-tail events. Methods such as feature distillation and pseudo-label supervision are primarily used to adapt vision foundation models (VFMs) and vision-LLMs (VLMs) for automotive perception tasks, such as instance segmentation and occupancy prediction. Incorporating generalized knowledge into perception stacks via vision models enables enhanced environmental understanding without relying extensively on annotations. These methods ensure a robust approach in this domain.
Spatial Understanding
Spatial awareness is crucial for autonomous driving, enabling models to develop coherent 3D representations of their environments. Techniques such as occupancy networks (Figure 2) and neural rendering mechanisms (Figure 3) contribute to comprehensive spatial reasoning. These models capture the spatial configuration of objects and predict their trajectories within an environment, allowing for seamless integration across perception tasks like object detection, segmentation, and motion prediction. As foundation models rely on 3D reconstruction methods, they better manage unstructured and varied environments.
Multi-sensor Robustness
Robust perception relies on multisensory fusion—a system's ability to integrate diverse data sources like cameras, LiDAR, and radar to enhance reliability under different environmental conditions. Key strategies involve cross-modality contrastive learning, knowledge distillation, and multi-modal masked autoencoders (Figure 4). These approaches allow models to maintain functional accuracy in adverse and variable conditions by harnessing complementary strengths of each sensor type.
Temporal Understanding
Temporal knowledge is essential for effective navigation in dynamic environments, including capturing object motions and predicting future states. Models that adopt temporally consistent 4D prediction (Figure 5) and contrastive learning (Figure 6) can anticipate future occurrences, optimize navigation strategies, and provide robust forecasts in autonomous systems. This capability is invaluable for navigating rapidly changing settings.
Challenges and Future Work
Key challenges persist in refining and deploying foundation models effectively. Important considerations include:
- Integration of Core Capabilities: Developing a coherent framework that seamlessly integrates generalized knowledge, spatial reasoning, multi-sensor robustness, and temporal understanding remains central to advancing foundation models.
- Real-time Latency Mitigation: Addressing the computational intensity and achieving real-time processing is crucial for integrating these models into autonomous systems.
- Robustness and Safety: Ensuring safety across diverse environments, reducing model hallucinations, and making consistent performance improvements against unforeseen scenarios.
- Benchmark Development: Enhancing evaluation through benchmarks that include corner cases will advance the capabilities of perception systems in real-world deployments.
Conclusion
Foundation models are poised to significantly transform autonomous driving perception, ensuring scalable and robust performance across complex environments. By emphasizing key capabilities like generalized knowledge and spatial understanding, the paper offers a conceptual framework to harmonize perception tasks, paving the way for future innovations in autonomous system design and deployment. Ensuring the effectiveness of these models will require addressing fundamental challenges around integration, real-time capabilities, and comprehensive evaluation methodologies.