- The paper establishes generative quantum advantage by demonstrating efficient learning and sampling algorithms on scalable quantum hardware.
- It introduces a deep-to-shallow circuit mapping and a divide-and-conquer sewing technique to overcome barren plateaus and excessive local minima in training.
- Experimental results on superconducting processors confirm high-fidelity sampling and circuit compression, outperforming classical methods at large scales.
Generative Quantum Advantage for Classical and Quantum Problems
Introduction and Motivation
The paper "Generative quantum advantage for classical and quantum problems" (2509.09033) rigorously establishes and experimentally demonstrates the concept of generative quantum advantage: the ability of quantum computers to efficiently learn and generate outputs from distributions that are classically intractable. Unlike prior works that focus solely on sampling or inference, this work closes the loop by showing that both learning and sampling can be performed efficiently in regimes where classical algorithms fail, with strong complexity-theoretic evidence and experimental validation.
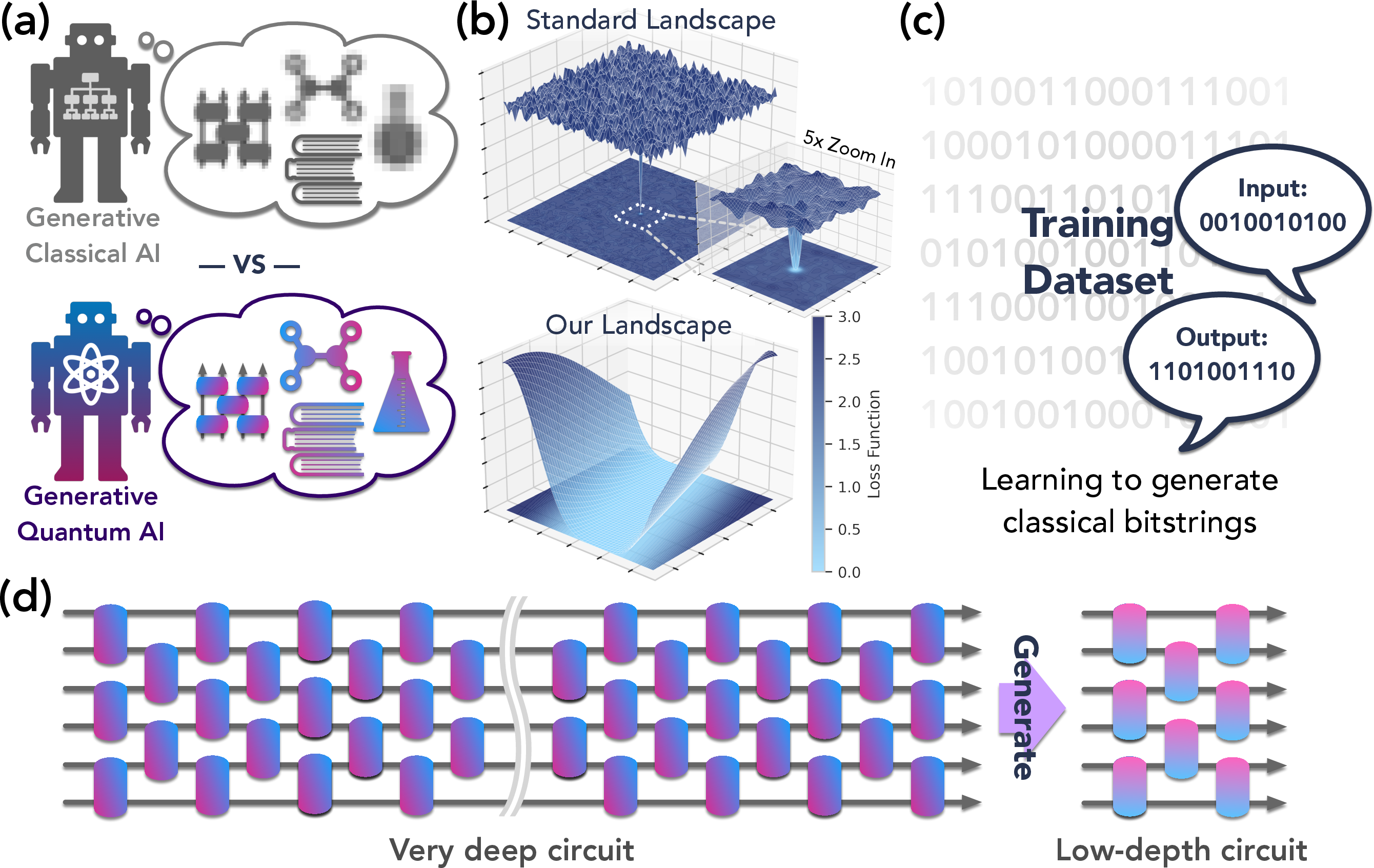
Figure 1: Overview of generative quantum advantage, highlighting efficient learning and sampling from classically hard distributions, improved optimization landscapes, and experimental scaling to hundreds of qubits.
Theoretical Framework for Generative Quantum Advantage
Definitions and Tasks
The paper formalizes generative quantum advantage as the regime where quantum computers can learn to generate outputs (classical bitstrings, quantum states, or compressed circuits) substantially better than any classical computer, in terms of sample complexity, accuracy, or computational resources. Three canonical tasks are defined:
- Learning to generate bitstrings: Given p(y∣x), learn a model that generates y from x.
- Learning to generate compressed simulation circuits: Given a circuit C for U, learn a low-depth circuit C′ for the same U.
- Learning to generate quantum states: Given access to U, learn a model that maps ∣ψ⟩→U∣ψ⟩.
The paper proves that for certain families of quantum models (notably shallow QNNs and instantaneously deep QNNs, IDQNNs), learning is classically efficient but inference (sampling) is classically hard, under standard complexity assumptions.
Deep-to-Shallow Circuit Mapping
A central technical contribution is the exact mapping between deep quantum circuits and shallow circuits (IDQNNs), leveraging measurement-based quantum computation and circuit universality. This mapping enables efficient classical training of shallow models that, when executed on quantum hardware, sample from distributions that are provably hard for classical algorithms.
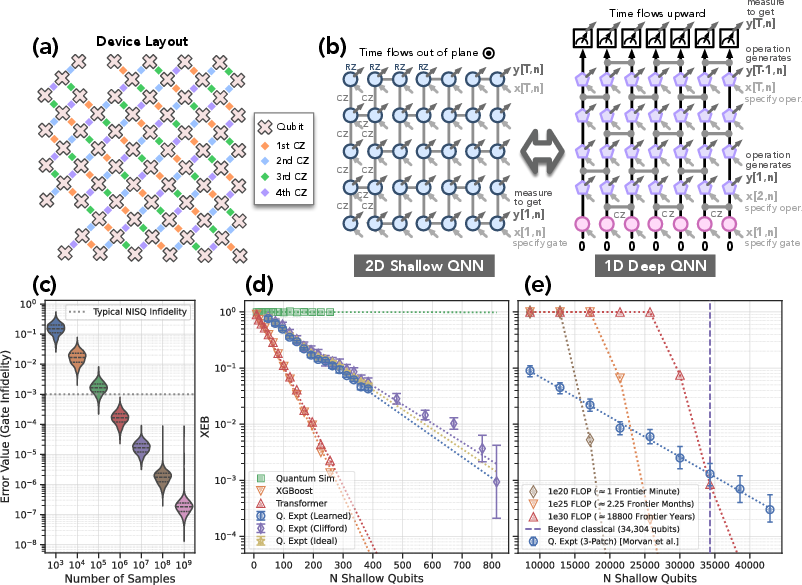
Figure 2: Experimental device layout and mapping between shallow and deep circuits, enabling efficient training and inference on up to 816 shallow qubits.
Optimization Landscape and Divide-and-Conquer Learning
Landscape Pathologies in Standard Approaches
The paper rigorously analyzes the optimization landscape for training quantum generative models. Standard approaches suffer from exponentially many suboptimal local minima and barren plateaus, even for problems with strong inductive bias and local cost functions. This is formalized for SWAP circuits, where the probability of successful training decays exponentially with system size.
Sewing Technique and Landscape Improvement
To overcome these pathologies, the authors employ a divide-and-conquer strategy using the sewing technique: decomposing the global unitary into local circuit pieces, training each piece independently, and coherently combining them with ancilla qubits. This approach provably eliminates barren plateaus and reduces the number of local minima to a constant, making random-restart gradient descent efficient.
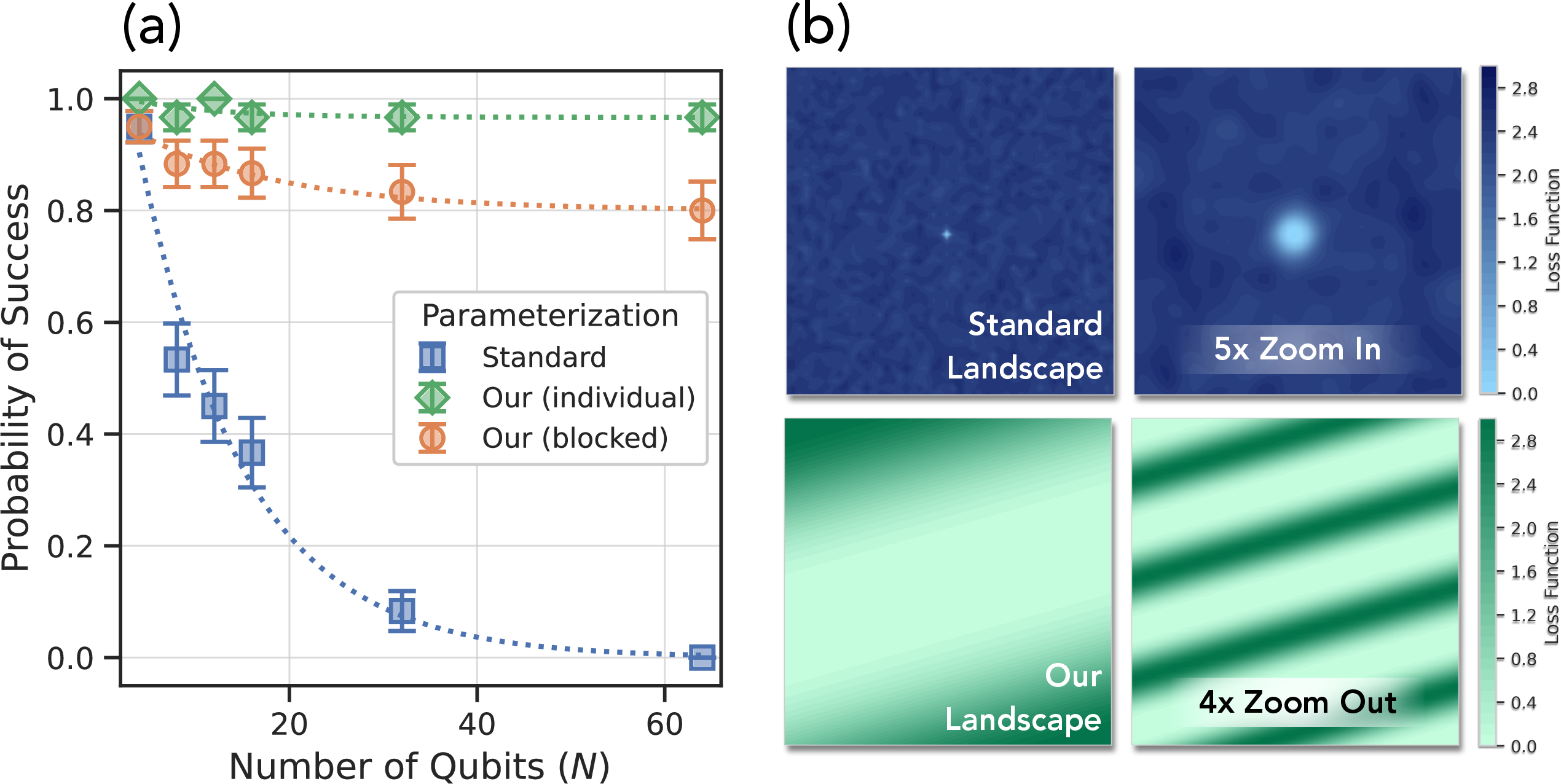
Figure 3: Probability of successful training and visualization of optimization landscapes, showing exponential improvement with divide-and-conquer sewing.
Experimental Demonstrations
Learning Classically Hard Bitstring Distributions
Using a 68-qubit superconducting processor, the authors implement IDQNNs to learn and sample from distributions that are classically hard to simulate. Classical models (transformers, XGBoost) are trained on the same data, but their performance degrades rapidly with system size, as quantified by XEB scores. Quantum models maintain high fidelity even with hardware noise, and the mapping to deep circuits enables scaling to 816 shallow qubits and inference for circuits corresponding to over 34,000 shallow qubits.
Figure 2: Experimental results for training and inference on classically hard distributions, with quantum models outperforming classical baselines and supercomputer simulations.
Circuit Compression and Hidden Structure Discovery
The sewing technique is further applied to learn compressed representations of quantum circuits for physical simulation. Even when a constant-depth representation is promised, classical compilers cannot efficiently find it unless BPP=BQP. The experiments demonstrate high-fidelity learning and inference for both short and long-time dynamics, exploiting hidden structure in the Hamiltonian.
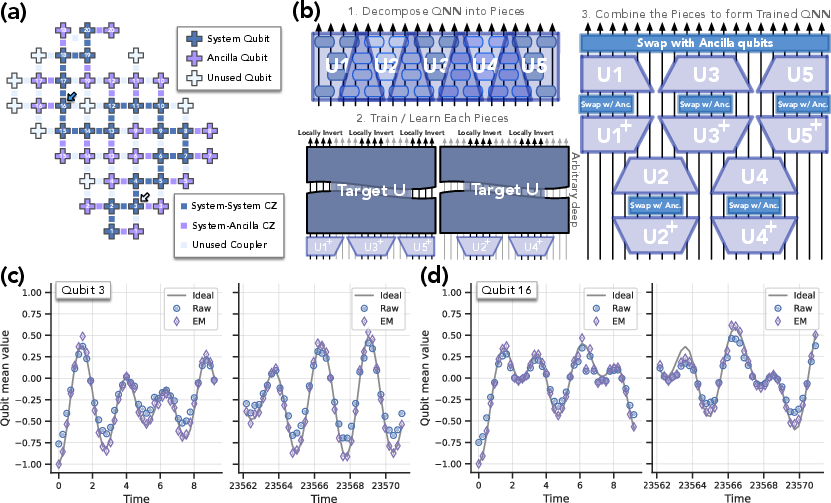
Figure 4: Experimental layout and results for learning quantum generative models via sewing, demonstrating high-quality inference for both short and long evolution times.
Numerical Experiments on Optimization Landscapes
Numerical experiments confirm the theoretical predictions: standard training is exponentially unlikely to succeed, while divide-and-conquer learning with sewing achieves high success probability for any system size. Landscape visualizations show the transition from chaotic terrain to benign basins of attraction.
Figure 3: Empirical probability of success and landscape visualization for SWAP circuit learning, validating the theoretical landscape analysis.
Implementation Details and Practical Considerations
- Training: Classical training of shallow QNNs and IDQNNs is efficient, requiring only polynomially many samples for local parameter estimation. For IDQNNs, local measurement statistics suffice to determine parameters.
- Inference: Sampling from the trained quantum model requires quantum hardware; classical simulation is infeasible for large system sizes due to entanglement and circuit depth.
- Hardware: Experiments are performed on a Sycamore-class superconducting processor with typical single-qubit and two-qubit gate errors of 10−3 and 10−2, respectively. Error mitigation is applied in inference.
- Scaling: The deep-to-shallow mapping enables scaling to hundreds of qubits, with resource requirements dominated by quantum hardware for inference.
- Classical Baselines: Classical ML models (transformers, boosting) are competitive only for small system sizes; quantum-inspired tensor network methods may extend classical simulation but are limited by entanglement growth.
Implications and Future Directions
The results establish that generative quantum advantage is achievable for both classical and quantum tasks, with efficient learning and sampling in regimes inaccessible to classical computation. This has direct implications for quantum-enhanced generative modeling, quantum circuit compilation, and simulation of complex physical systems.
Theoretically, the work motivates further exploration of model classes that are both efficiently trainable and classically hard to sample from, especially for real-world data distributions. Practically, it suggests that quantum machine learning may achieve empirical advantage by leveraging trainability and hardware efficiency, even before full fault tolerance.
Potential future developments include:
- Generalization to models supporting floating-point and integer data for classical ML compatibility.
- Identification of practical data distributions and sensing modalities that maximize quantum advantage.
- Empirical studies of emergent trainability and hardware efficiency in quantum generative models.
Conclusion
This paper provides a rigorous and comprehensive foundation for generative quantum advantage, combining complexity-theoretic proofs, landscape analysis, and large-scale experimental demonstrations. The divide-and-conquer sewing technique is shown to be essential for efficient training, and the deep-to-shallow mapping enables practical scaling. The results have significant implications for quantum machine learning, generative modeling, and quantum simulation, and set the stage for future empirical and theoretical advances in quantum-enhanced AI.