- The paper reveals a fundamental trade-off between validity and minimality in self-generated counterfactual explanations from LLMs.
- It employs controlled experiments on tabular datasets, using Gower's Distance to quantify the minimality of input changes.
- The study finds that no LLM consistently produces both valid and minimal explanations, challenging their reliability in high-stakes applications.
Limitations of Self-Generated Counterfactual Explanations in LLMs
Introduction
This paper systematically investigates the reliability of self-generated counterfactual explanations (SCEs) produced by LLMs. SCEs are intended to provide insight into a model's decision-making by modifying an input such that the model's prediction changes, ideally with minimal alteration. The study evaluates whether LLMs can generate SCEs that are both valid (i.e., actually flip the model's prediction) and minimal (i.e., make the smallest possible change to the input). The analysis is conducted across multiple LLMs, datasets, and prompt settings, revealing a fundamental trade-off between validity and minimality that current models are unable to resolve.
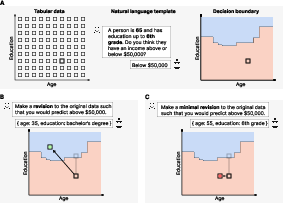
Figure 1: Study design for evaluating SCEs in tabular binary classification tasks, illustrating the concepts of validity and minimality.
Experimental Design and Methodology
The authors employ a controlled experimental setup using tabular datasets with discrete features, enabling exhaustive enumeration of the input space and precise measurement of minimality. Each data instance is converted into a natural language prompt, and LLMs are tasked with predicting a binary outcome (e.g., income above/below a threshold, house price above/below a threshold, presence/absence of heart disease). For each prediction, the model is then prompted to generate an SCE—an alternative input that would flip its prediction.
Two prompt settings are evaluated:
- Unconstrained: The model is simply asked to provide a counterfactual that would flip its prediction.
- Minimal: The model is explicitly instructed to make the smallest possible change, with minimality defined via Gower's Distance.
Validity is measured as the proportion of SCEs that actually flip the model's prediction when re-evaluated. Minimality is quantified as the excess distance (ED) between the original input and the SCE, relative to the true minimal counterfactual.
Main Findings: Validity-Minimality Trade-off
SCEs Are Valid but Not Minimal
In the unconstrained setting, LLMs consistently generate SCEs that are valid—i.e., they cross the decision boundary and flip the prediction. However, these SCEs are far from minimal, often making excessive changes to the input. For example, in the house price dataset, models frequently maximize all features (e.g., largest area, most bedrooms, etc.) to ensure the prediction flips, rather than identifying the minimal necessary change.
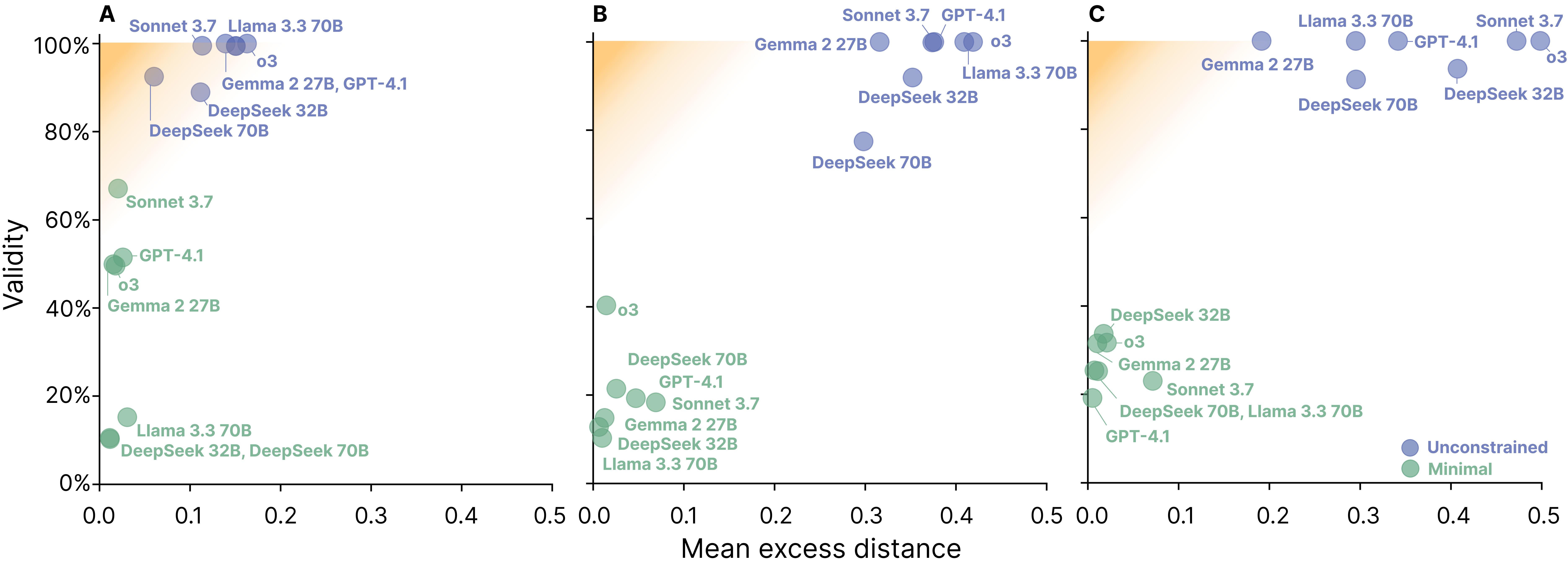
Figure 2: SCE validity and minimality for income, house prices, and heart disease datasets. Unconstrained prompts yield valid but non-minimal SCEs; minimal prompts yield more minimal but often invalid SCEs.
SCEs Are Minimal but Rarely Valid
When explicitly prompted for minimality, LLMs tend to make overly conservative edits that frequently fail to cross the decision boundary, resulting in SCEs that are minimal but invalid. This is particularly evident in higher-dimensional datasets, where the probability of a small edit flipping the prediction is low. The mean validity drops sharply in the minimal setting, while the mean excess distance of valid SCEs improves.
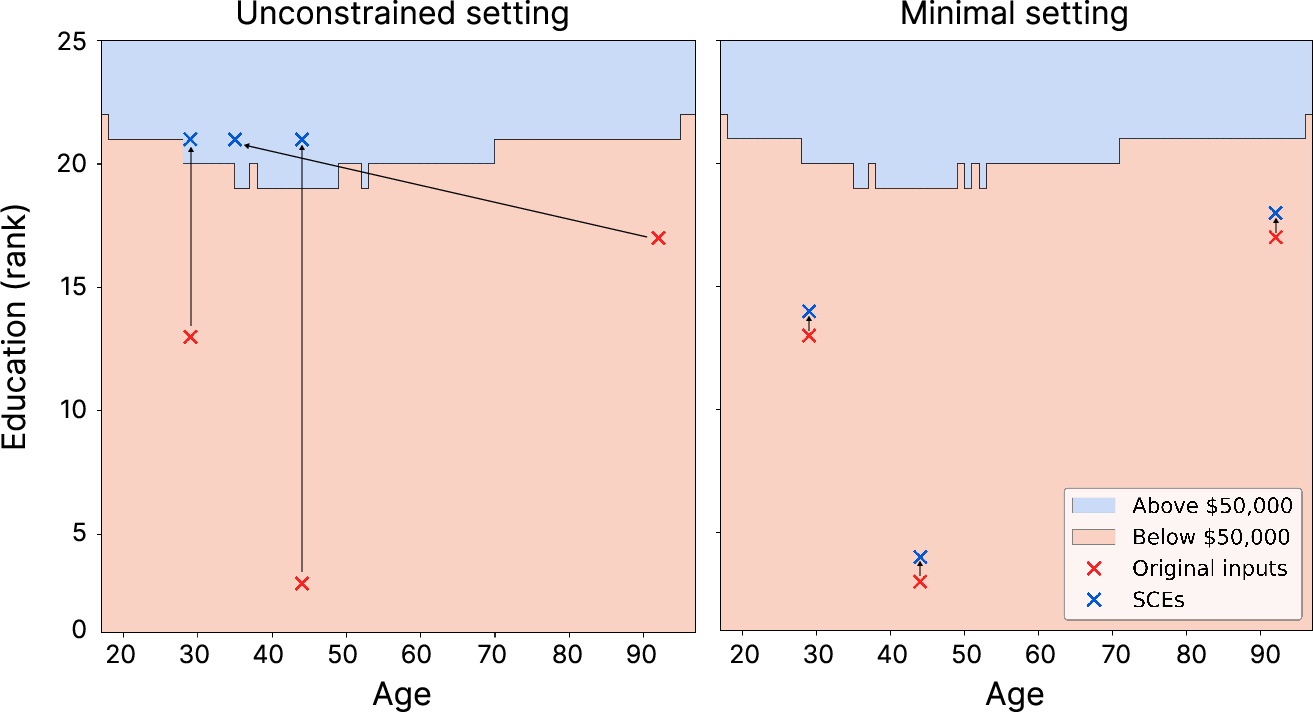
Figure 3: Llama 3.3 70B's SCEs on the income dataset. Unconstrained SCEs are valid but non-minimal; minimal SCEs are often invalid due to insufficient change.
No Model Satisfies Both Criteria
Across all models and datasets, no LLM is able to consistently generate SCEs that are both valid and minimal. The exact match rate—i.e., the proportion of SCEs that are both valid and exactly minimal—remains below 32% in all cases, and is typically much lower.
Robustness and Ablation Analyses
The validity-minimality trade-off is robust to several experimental variations:
- Distance Metric: The trade-off persists across Gower, L1, L2, and semantic (embedding-based) distance metrics.
- Prompt Variations: Generating 20 paraphrased versions of each prompt does not materially affect the results.
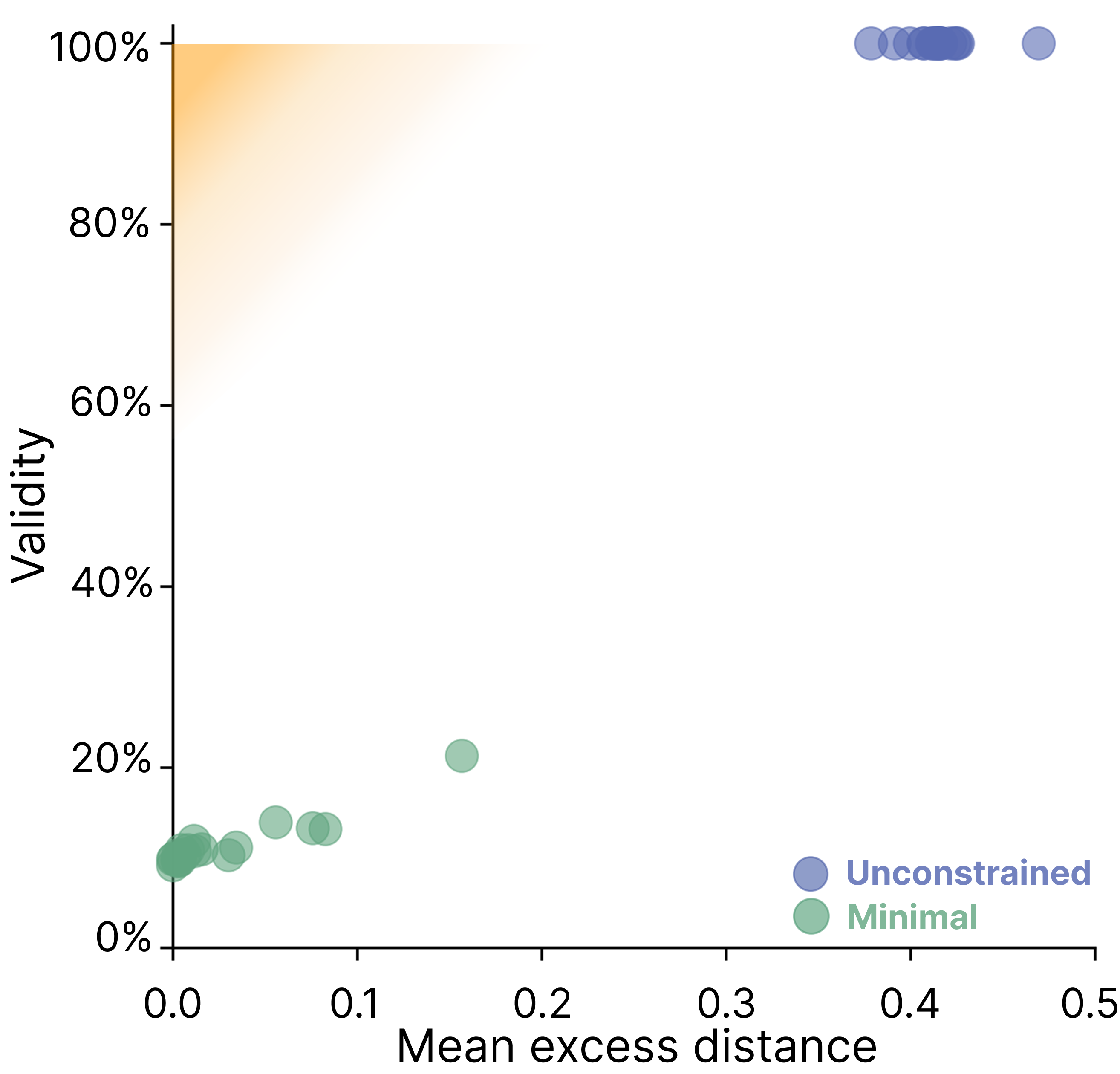
Figure 4: Robustness of SCE validity and minimality to prompt perturbations; performance is stable across prompt variations.
- Temperature: Increasing generation temperature does not resolve the trade-off.
- Decision Boundary Consistency: The models' decision boundaries are stable under prompt perturbations, except in a narrow region near the boundary, and this does not explain the observed failures.
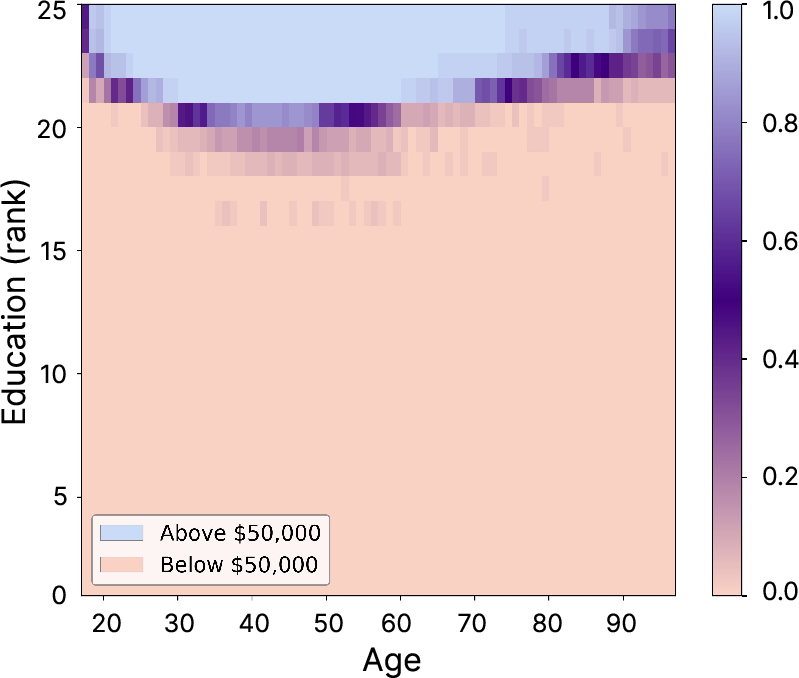
Figure 5: Decision boundary consistency across 50 prompt perturbations; instability is limited to a narrow region.
Analysis of Limiting Factors
The authors investigate three necessary (but not sufficient) conditions for successful SCE generation:
- Decision Boundary Consistency: As above, boundaries are stable.
- Operationalization of Distance: Most models, especially those with explicit reasoning capabilities, can accurately compute Gower's Distance and select the closest candidate SCE.

Figure 6: DeepSeek-R1 70B correctly operationalizes Gower's Distance but does not attempt self-prediction in its reasoning trace.
- Self-Prediction: Models do not spontaneously engage in self-prediction—i.e., they do not attempt to simulate their own behavior in a new context window. Even when explicitly prompted to do so, aggregate performance does not improve, and self-predictions are often incorrect.
Implications for Explainability and Deployment
The findings have significant implications for the use of SCEs as an explainability tool in LLMs:
- Ineffectiveness of SCEs: At best, SCEs provide trivial or uninformative explanations, as models default to making large, non-specific changes to inputs.
- Potential for Misleading Explanations: At worst, SCEs can be misleading, especially in high-stakes domains (e.g., clinical decision support), where users may rely on invalid or non-minimal counterfactuals to guide actions.
- Lack of Self-Modeling: The inability of LLMs to accurately self-predict their own behavior in alternative contexts suggests a fundamental limitation rooted in current pretraining and post-training objectives, which do not incentivize the development of a self-model.
Theoretical and Practical Implications
Theoretically, the results challenge the assumption that LLMs' self-explanations are faithful or actionable. The observed trade-off is not an artifact of prompt design, distance metric, or model stochasticity, but appears intrinsic to current LLM architectures and training regimes. Practically, this calls into question the deployment of SCE-based explainability in any setting where reliability and faithfulness are required.
The study also highlights the need for new learning objectives or architectural modifications that explicitly incentivize accurate self-prediction and self-modeling, potentially drawing on insights from metacognition research in humans and other AI systems.
Future Directions
Future research should explore:
- Alternative Training Objectives: Incorporating self-modeling or metacognitive objectives during pretraining or fine-tuning.
- Evaluation on Real-World, High-Dimensional Data: Extending the analysis to more complex, less constrained domains.
- Integration with External Verification: Combining SCEs with external verification or search-based methods to ensure both validity and minimality.
- Human-in-the-Loop Evaluation: Assessing the practical impact of SCE failures on end-user decision-making.
Conclusion
This work demonstrates a robust and persistent trade-off between validity and minimality in self-generated counterfactual explanations from LLMs. Current models are unable to reliably generate SCEs that are both valid and minimal, limiting their utility as explainability tools and raising concerns about their deployment in high-stakes applications. Addressing these limitations will require fundamental advances in model training and self-modeling capabilities.