RAPTOR: A Foundation Policy for Quadrotor Control
Abstract: Humans are remarkably data-efficient when adapting to new unseen conditions, like driving a new car. In contrast, modern robotic control systems, like neural network policies trained using Reinforcement Learning (RL), are highly specialized for single environments. Because of this overfitting, they are known to break down even under small differences like the Simulation-to-Reality (Sim2Real) gap and require system identification and retraining for even minimal changes to the system. In this work, we present RAPTOR, a method for training a highly adaptive foundation policy for quadrotor control. Our method enables training a single, end-to-end neural-network policy to control a wide variety of quadrotors. We test 10 different real quadrotors from 32 g to 2.4 kg that also differ in motor type (brushed vs. brushless), frame type (soft vs. rigid), propeller type (2/3/4-blade), and flight controller (PX4/Betaflight/Crazyflie/M5StampFly). We find that a tiny, three-layer policy with only 2084 parameters is sufficient for zero-shot adaptation to a wide variety of platforms. The adaptation through In-Context Learning is made possible by using a recurrence in the hidden layer. The policy is trained through a novel Meta-Imitation Learning algorithm, where we sample 1000 quadrotors and train a teacher policy for each of them using Reinforcement Learning. Subsequently, the 1000 teachers are distilled into a single, adaptive student policy. We find that within milliseconds, the resulting foundation policy adapts zero-shot to unseen quadrotors. We extensively test the capabilities of the foundation policy under numerous conditions (trajectory tracking, indoor/outdoor, wind disturbance, poking, different propellers).


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces RAPTOR, a tiny but powerful “brain” for flying robots called quadrotors (drones with four propellers). Unlike most drone controllers that only work well on one specific drone, RAPTOR is a single neural network that can fly many different drones—small or big, fast or slow—without extra training. It figures out each drone’s “personality” on the fly, much like how you can quickly adjust to driving a different car.
The big questions the researchers asked
The authors set out to answer simple but important questions:
- Can one small neural network control many different drones without retraining each time?
- How small and fast can that network be so it runs on tiny onboard computers?
- Can it “learn while flying” by using recent observations (a kind of short-term memory)?
- Will it work on drones it has never seen before, even ones that are quite different?
- How quickly can it adapt mid-flight—fast enough to keep the drone safe?
- Is there a trade-off between being very agile and being very adaptable?
How they did it (in plain language)
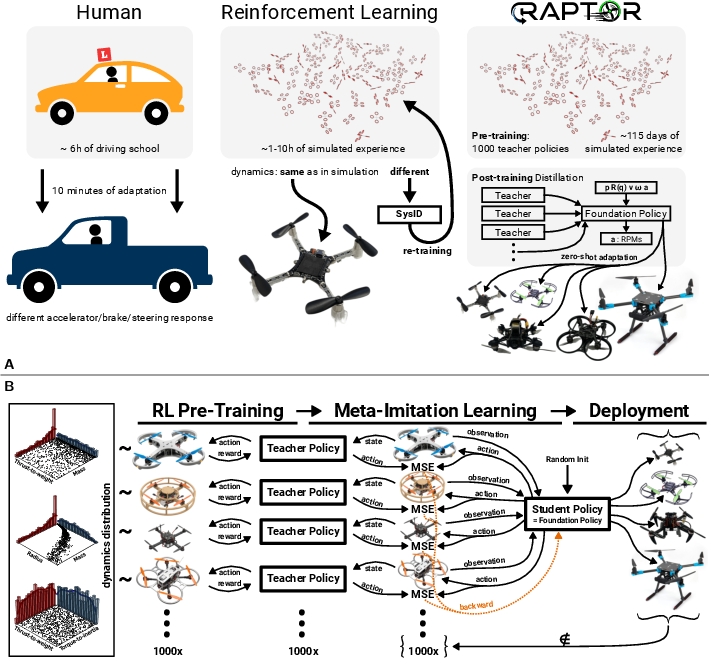
Think of training a great all-around driver by letting them watch 1,000 expert drivers, each expert in a different type of car.
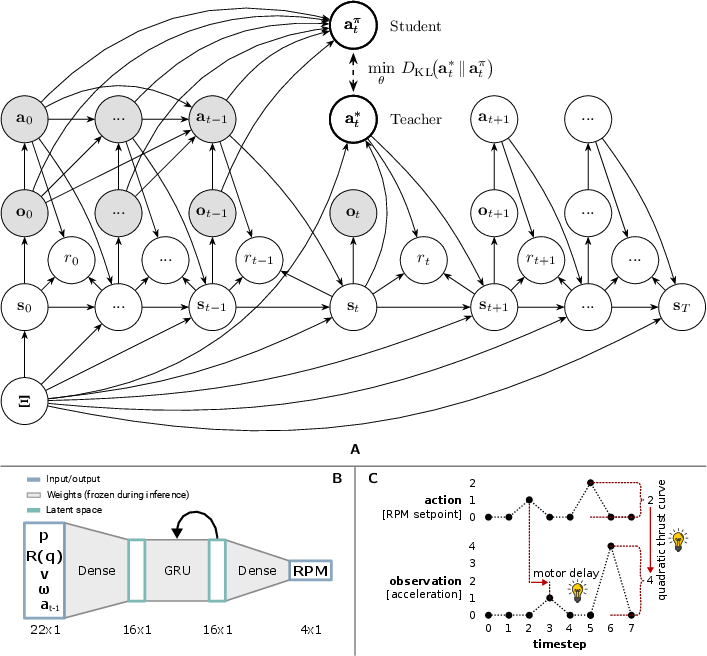
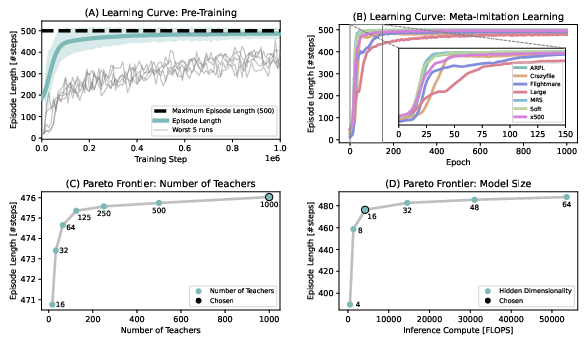
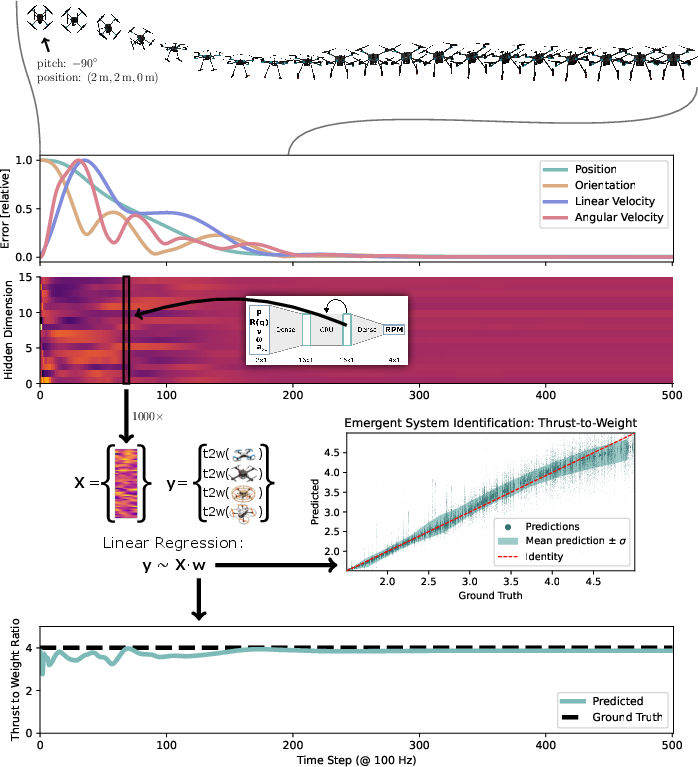
- Step 1: Build 1,000 “teachers.” The team created 1,000 simulated drones with different characteristics (weight, motor strength, delays, etc.). For each one, they trained a separate expert “teacher” controller using Reinforcement Learning (RL). Each teacher is perfect for its own drone.
- Step 2: Teach one “student” to imitate them all. They then trained a single “student” neural network to imitate the right teacher at the right time. But here’s the trick: the student is a recurrent neural network (RNN), which means it has a short-term memory. By watching how the drone responds to its own control signals over a short time window, the student figures out which kind of drone it’s flying and adapts—without being told the drone’s specs.
- Step 3: Make it tiny and fast. The final model is extremely small—just 2,084 parameters—and can run in real time on small microcontrollers inside the drone. No big computer needed.
Key ideas explained simply:
- Reinforcement Learning (RL): Learning by trial and error to get better rewards (like staying stable, tracking a path).
- Distillation/Imitation: The student watches many experts and learns to act like the right one.
- Recurrent network (RNN): A controller with memory, so it can learn from recent history.
- In-context learning: Figuring things out from the recent sequence of inputs and outputs—like noticing “when I increase throttle, this drone accelerates slowly, so it’s heavy.”
- Zero-shot adaptation: Working on a new drone immediately, with no extra training.
What they found and why it matters
What they tested:
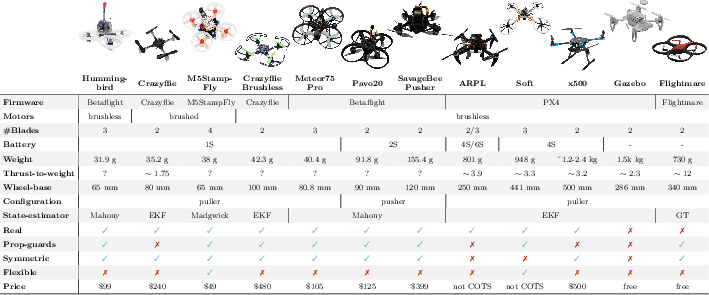
- 10 real drones plus 2 simulators, ranging from 32 grams to 2.4 kilograms.
- Different motors (brushed/brushless), propellers (2-, 3-, and 4-blade), frames (stiff and flexible), and flight controllers (PX4, Betaflight, Crazyflie, M5StampFly).
- Indoors and outdoors, in wind, with disturbances (like poking the drone mid-flight), and even with mismatched propellers.
Main results:
- One tiny network controlled all these drones without any extra tuning.
- It adapted in milliseconds by “watching” how the drone responded—no explicit knowledge of the drone’s physical parameters needed.
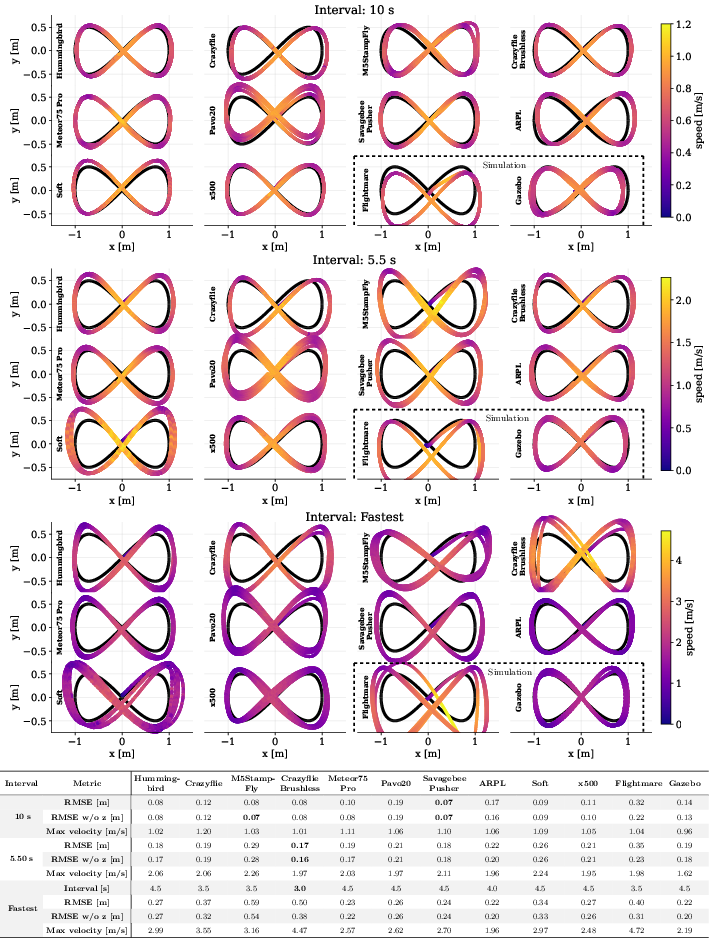
- It tracked paths (like figure-eights) almost as well as specialized, single-drone controllers. On a popular small drone (Crazyflie), its tracking error was about 0.19 m—very close to a controller trained only for that drone.
- It handled strong wind, sudden hits, added payloads, and even mixed propeller types.
- It kept working beyond its training “memory length,” flying safely for minutes even though it was trained on only a few seconds of data at a time.
- It ran on tiny onboard computers, using less than 10% of their computing power.
Why this is important:
- Today, many drone controllers are “picky” and break when small things change. RAPTOR shows a path to universal, robust controllers that just work—even on new hardware—saving lots of time and effort.
- It suggests that “foundation models” (like big models in language and vision) can exist for robotics too: train on a wide variety, and then adapt on the fly from context.
What this could mean for the future
- Easier deployment: One controller for many drones reduces tuning, testing, and re-training costs.
- More reliable robots: Better handling of real-world surprises—wind, wear and tear, sensor delays—without crashing.
- Faster innovation: Researchers and companies can use RAPTOR as a strong baseline, speeding up development for delivery, inspection, and search-and-rescue.
- Beyond drones: The same idea—learn from many experts, then adapt in context—could help other robots (like arms, cars, or legged robots) adjust to new tools and terrains quickly.
In short, RAPTOR is a step toward “plug-and-fly” robotics: one small, smart controller that learns what it needs to, right when it needs to, so it can safely and skillfully fly almost any quadrotor.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of specific gaps and unresolved questions that future work could address to strengthen and extend the RAPTOR foundation policy.
- Formal guarantees are absent: no Lyapunov/stability proofs, robustness margins, or reachability/safety certification for the closed-loop RNN controller under model uncertainty and disturbances.
- Robustness to estimator imperfections is only anecdotal: z-axis oscillations under Mahony/Madgwick filters are hypothesized to stem from velocity delays, but there is no systematic sensitivity analysis across delay/noise/latency spectra, estimator architectures, sampling rates, or timestamping jitter.
- Covariate shift in imitation is unaddressed: the student is trained on teacher-generated trajectories; there is no analysis or mitigation (e.g., DAgger-style data aggregation) for distribution drift when the student deviates from teacher behavior at inference.
- Out-of-distribution generalization boundaries are not quantified: while the policy handles thrust-to-weight ≈12 (training ≤5), flexible frames, and mixed propellers, there is no characterization of failure modes or explicit OOD envelopes (e.g., max parameter deviations the policy can tolerate).
- Agility bottleneck from missing trajectory lookahead is hypothesized but not validated: no ablation comparing lookahead-free vs. lookahead-enabled policies, nor quantification of gains, compute trade-offs, or latency constraints when adding future reference information.
- Adaptation time is not rigorously measured: “milliseconds” is claimed, but there is no systematic measurement of time-to-stable and time-to-target under diverse initial conditions and platforms, nor analysis of how estimator latency and action saturation affect identification speed.
- Long-horizon memory and drift are unquantified: despite anecdotal “minutes-long” flights, there is no evaluation of hidden-state stability, susceptibility to catastrophic forgetting, or accumulation of bias over extended missions, temperature changes, or battery depletion.
- Teacher policy dependence is underexplored: the effect of teacher quality, diversity, and reward shaping on student performance and generalization is not analyzed; the sensitivity to mis-specified teachers or low-performing teachers remains unknown.
- Design of the training distribution lacks coverage metrics: no principled method is provided to measure how well the sampled parameter priors cover the true fleet distribution; no adaptive sampling or active coverage strategies are explored.
- Limited observation realism during training: training uses ground-truth observations (sim) while deployment relies on various state estimators; there is no systematic gap-bridging via observation-domain randomization (e.g., noise, bias, delay, dropout) and no evaluation with purely onboard sensing (VIO, optical flow, GPS-only).
- Flexible-frame and propeller heterogeneity are not modeled in training: although OOD success is shown, there is no investigation into training with explicit flexible-body dynamics or heterogeneous thrust curves (per-motor variability) to improve reliability under these conditions.
- Motor/ESC protocol and timing variability are not systematically studied: differences in ESC update rates, PWM/RPM command paths, and firmware-specific scheduling/latency are implicated but not profiled; guidelines for timing alignment and mitigation are missing.
- Failure resilience is not evaluated: there are no tests for partial actuator loss (e.g., one motor failure), severe sensor dropouts, magnetometer anomalies, GPS loss, or emergency behaviors; safety wrappers/fallbacks to classical controllers are not discussed.
- Task coverage is narrow: the policy focuses on position/trajectory tracking; there is no evaluation for takeoff/landing, aggressive acrobatics, perching/contact-rich maneuvers, or perception-integrated tasks (e.g., gate racing with onboard vision).
- Generalization beyond quadrotors is unknown: extensions to other multirotor configurations (hexacopters, coaxial setups), nonstandard geometries, or variable rotor count are not explored.
- RNN architecture choices are not ablated: the recurrence type, gating (e.g., GRU/LSTM vs. simple RNN), hidden size beyond scalar scaling, and training sequence length effects are not studied; no analysis of memory capacity vs. identification accuracy.
- Uncertainty estimation is missing: the policy provides no confidence or calibration signals regarding its inferred dynamics; there is no exploration of probabilistic latent dynamics (e.g., Bayesian RNNs) or uncertainty-aware action selection.
- Metrics are limited: trajectory RMSE dominates evaluation; energy efficiency, control effort, motor saturation, thermal/load management, and recovery quality (overshoot, settling time) are not systematically reported.
- Head-to-head baselines are lacking: no controlled comparisons against adaptive classical controllers (e.g., gain-scheduled PID/MPC), domain-randomized Markovian policies, or prior adaptive NN controllers on identical hardware and trajectories.
- Reward shaping sensitivity is untested: the impact of the specific reward terms (e.g., orientation penalty via qz, action change penalty) on learned adaptation and steady-state accuracy is not ablated or justified.
- Scaling laws are partial: model-size and teacher-count Pareto frontiers are shown, but there is no analysis of compute/latency limits across microcontrollers, memory footprint under different precisions (e.g., int8), or scheduling with real-time estimator loops.
- Theoretical framing is incomplete: the variational inference/KL objective is introduced but not fully derived or empirically validated (e.g., measuring KL to teacher action distributions, convergence properties, or sample complexity).
- Outdoor sensing details are unclear: wind tests on x500 lack explicit estimator configurations (GPS/VIO), observation delays/noise characteristics, and the role of gust-induced estimation errors on adaptation robustness.
- Policy deployment interfaces lack safety guidance: while integration across PX4/Betaflight/Crazyflie/M5StampFly is provided, there are no recommended safety monitors (e.g., envelope guards, action-rate limiters), nor standardized procedures for activation/deactivation and mode switching.
- Data for real-world reproducibility is limited: teacher datasets are released, but multi-platform flight logs with estimator signals, delays, and timing traces are not provided to enable independent timing/robustness analyses.
Collections
Sign up for free to add this paper to one or more collections.