- The paper reveals that LMMs struggle with inductive physical reasoning, particularly in collision scenarios deviating from known physical laws.
- It introduces the InPhyRe benchmark, using synthetic video scenarios to test model performance under both regular and irregular physical conditions.
- Experimental insights show LMMs rely heavily on parametric knowledge and language cues, highlighting the need for improved multimodal integration.
Inductive Physical Reasoning in Large Multimodal Models
The paper "InPhyRe Discovers: Large Multimodal Models Struggle in Inductive Physical Reasoning" addresses the gap in current benchmarks by introducing InPhyRe, a visual question answering benchmark designed to assess inductive physical reasoning in Large Multimodal Models (LMMs). The emphasis of this study is on how LMMs handle collision events that deviate from universal physical laws such as momentum conservation. The findings indicate significant challenges in LMMs' reasoning capabilities, especially when faced with unseen physical laws.
Background and Motivation
LMMs encode parametric knowledge of universal physical laws observed during training. However, their parametric knowledge is limited to scenarios encountered during training and is insufficient in situations that violate the laws encoded in their parameters. Humans, in contrast, can swiftly adapt their reasoning to novel physical environments through inductive reasoning. This paper posits that for LMMs to replace human agents in critical application domains like autonomous driving, they need robust inductive physical reasoning capabilities.
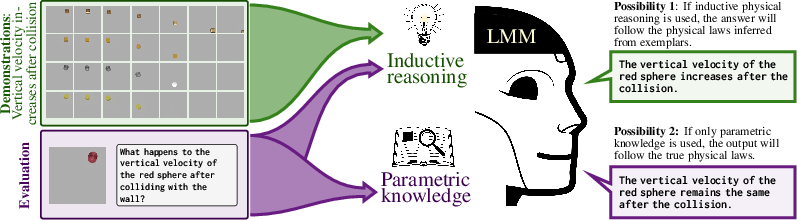
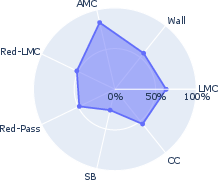
Figure 1: LMM is asked to predict the change in vertical velocity of an object colliding with a vertical wall, illustrating difficulties in inductive physical reasoning.
InPhyRe Benchmark Design
InPhyRe is the inaugural benchmark explicitly developed for evaluating inductive physical reasoning in LMMs. It includes synthetic video scenarios where LMMs predict outcomes of collision events either adhering to or deviating from known physical laws.
Scenarios and Categories
The benchmark is structured around scenarios, categorized by the physical laws they violate or adhere to:
- Momentum Conservation Violation: Scenarios where linear or angular momentum principles are violated (Figure 2).
- Inconsistent Physics: Scenarios where some object properties violate typical physical laws (e.g., specific colored objects behaving differently).
- Miscellaneous: Scenarios assessing concepts like visual bias in physical reasoning.
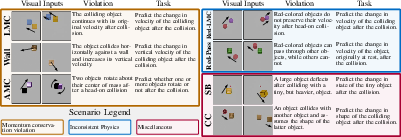
Figure 2: Structure of the InPhyRe benchmark featuring scenarios that violate universal physical laws.
Evaluation Methodology
LMMs are assessed under zero-shot and few-shot settings, distinguished by whether exemplars that follow (regular) or violate (irregular) universal laws are used. The performance gap between these settings is used to measure inductive physical reasoning strength.
Open Challenges
The study identified several challenges:
- Limited Parametric Knowledge: LMMs often fail basic reasoning tasks, even in regular scenarios.
- Weak Inductive Reasoning: Performance significantly deteriorates in irregular scenarios where inductive reasoning is vital.
- Language Bias: LMMs predominantly rely on language cues rather than visual inputs, highlighting trust issues when visual congruity with textual information is absent.
Experimental Insights
The experiments involved a diverse set of LMMs with differing architectures and parameter counts. The models displayed variable performance based on their architectural nuances.
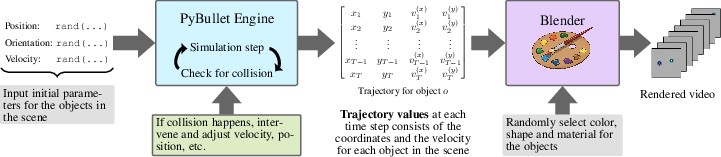
Figure 3: Visual pipeline for generating synthetic videos used in the benchmark.
Implications and Future Directions
The findings underscore critical gaps in LMMs' reasoning capabilities—specifically, the need for models to balance their parametric knowledge with flexible, inductive reasoning capabilities. Future research could explore incorporating feedback mechanisms in training protocols to enhance inductive reasoning in LMMs. Moreover, addressing language bias by integrating more robust visual processing capabilities is another prospective pathway.
Conclusion
"InPhyRe" presents substantial insights into the limitations of current LMMs regarding inductive physical reasoning. The benchmark's value lies in its potential to guide the development of more versatile AI systems capable of understanding and reasoning about complex real-world scenarios beyond their training experiences. Future work should prioritize methods to alleviate these identified deficiencies, potentially involving adaptive learning strategies and enhanced multi-modal integrations to replicate the nuanced understanding inherent in human reasoning.