- The paper introduces StereoCarla, a diverse synthetic stereo dataset that enhances cross-domain generalization for depth estimation models.
- It employs multiple baselines, varied camera angles, and realistic weather conditions to simulate complex autonomous driving scenarios.
- Experiments show that models trained on StereoCarla outperform those from existing datasets across several benchmarks.
StereoCarla: A High-Fidelity Synthetic Dataset for Generalizable Stereo Matching
Motivation and Context
Stereo matching is a critical component for depth perception in autonomous driving and robotics, enabling dense disparity estimation from rectified stereo image pairs. While deep learning-based stereo algorithms have achieved strong performance on established benchmarks, their generalization to unseen domains remains limited, primarily due to the constrained diversity of existing datasets. Most public datasets either focus on narrow scenarios (e.g., urban driving with fixed camera setups) or lack real-world complexity and variability in environmental conditions, camera baselines, and viewpoints. This restricts the robustness and adaptability of stereo models in practical deployment.
Dataset Design and Characteristics
StereoCarla is introduced to address these limitations by leveraging the CARLA simulator to generate a synthetic stereo dataset with extensive diversity and realism. The dataset is characterized by:
- Multiple Baselines: Data is collected with baseline distances of 10, 54, 100, 200, and 300 cm, covering a broader range than prior datasets and supporting generalization across hardware configurations.
- Camera Viewpoint Diversity: Images are captured at four horizontal viewing angles (0°, 5°, 15°, 30° roll) and from elevated viewpoints (10 m above ground, with horizontal and 30° downward pitch), simulating real-world camera pose variations.
- High Resolution: Each stereo pair is provided at 1600×900 pixels, with dense ground-truth disparity maps.
- Environmental Variability: Scenes are rendered under diverse weather conditions (clear, cloudy, foggy, humid, night, storm, sunset), introducing realistic challenges for stereo matching.
- Scene Diversity: Data is collected across multiple CARLA towns, with varied road geometries, traffic agents, and environmental textures.


















Figure 1: Left-eye image from the StereoCarla dataset, illustrating high-fidelity scene rendering and camera viewpoint diversity.
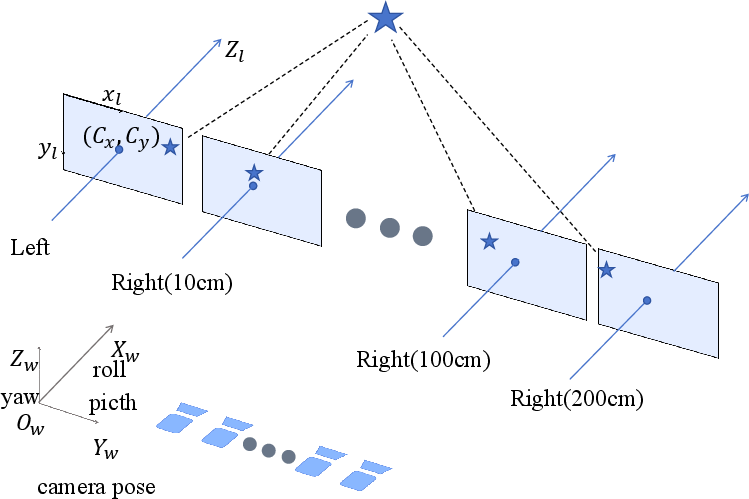
Figure 2: Camera settings for data generation, showing the range of baselines and viewpoint configurations used in StereoCarla.
Experimental Protocol and Evaluation
Experiments are conducted using the NMRF-Stereo model with a SwinTransformer backbone, trained via the OpenStereo framework. Both single-dataset and multi-dataset training regimes are evaluated. The following metrics are used:
- In-domain: End-Point Error (EPE) for disparity, Absolute Relative Error (Abs Rel), and threshold accuracy (δ<1.25) for depth.
- Cross-domain: D1-all (KITTI), Bad 2.0 (Middlebury), Bad 1.0 (ETH3D), measuring the percentage of pixels with disparity errors exceeding specified thresholds.
Main Results
Cross-Domain Generalization
Models trained on StereoCarla consistently outperform those trained on 11 existing stereo datasets across four standard benchmarks (KITTI2012, KITTI2015, Middlebury, ETH3D). Notably, StereoCarla-trained models achieve the lowest mean disparity errors and superior zero-shot generalization, even on datasets with different scene types and sensor modalities.
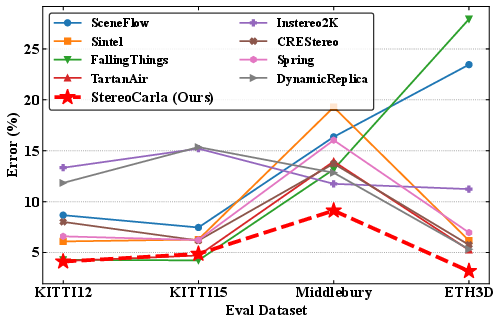
Figure 3: Zero-shot performance of stereo models trained on different datasets. Models trained on StereoCarla consistently achieve superior generalization, outperforming those trained on other existing stereo datasets.
Qualitative results show sharper object boundaries and more accurate disparity maps for StereoCarla-trained models compared to those trained on other datasets.
Multi-Dataset Training
When integrated into multi-dataset training, StereoCarla acts as a backbone, further improving generalization accuracy. Incrementally adding complementary datasets to StereoCarla leads to monotonic performance gains, with the most comprehensive setup (all datasets combined) yielding the lowest mean error. Ablation studies confirm that omitting StereoCarla from the mix results in substantial performance degradation, especially in complex domains.
Ablation Studies
- Baseline Diversity: Training on all baselines yields the best in-domain and cross-domain performance, highlighting the necessity of geometric diversity.
- Camera Angles: Models trained on all camera angles generalize better than those trained on single-angle data, confirming the importance of viewpoint diversity.
- Weather Conditions: Inclusion of varied weather scenarios leads to consistent improvements in generalization, demonstrating the value of semantic diversity.















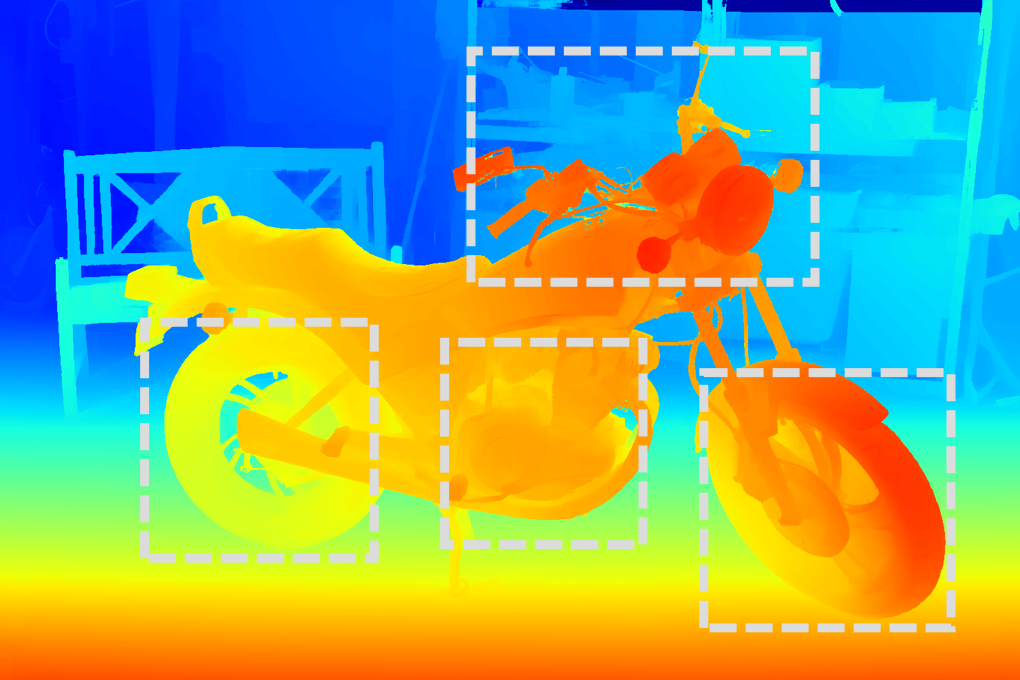

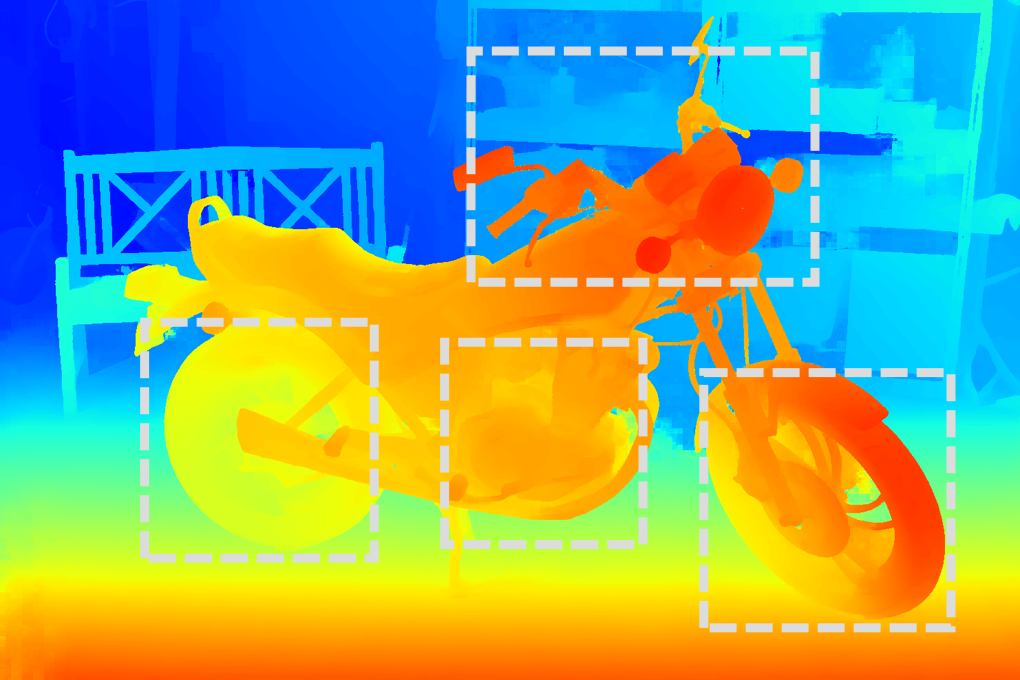
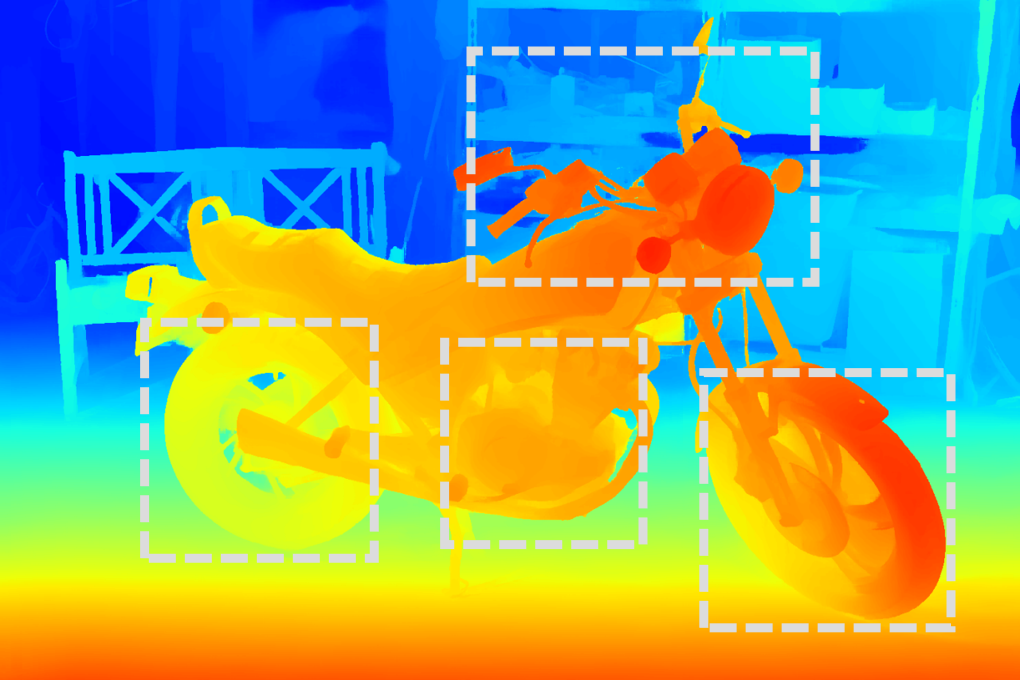
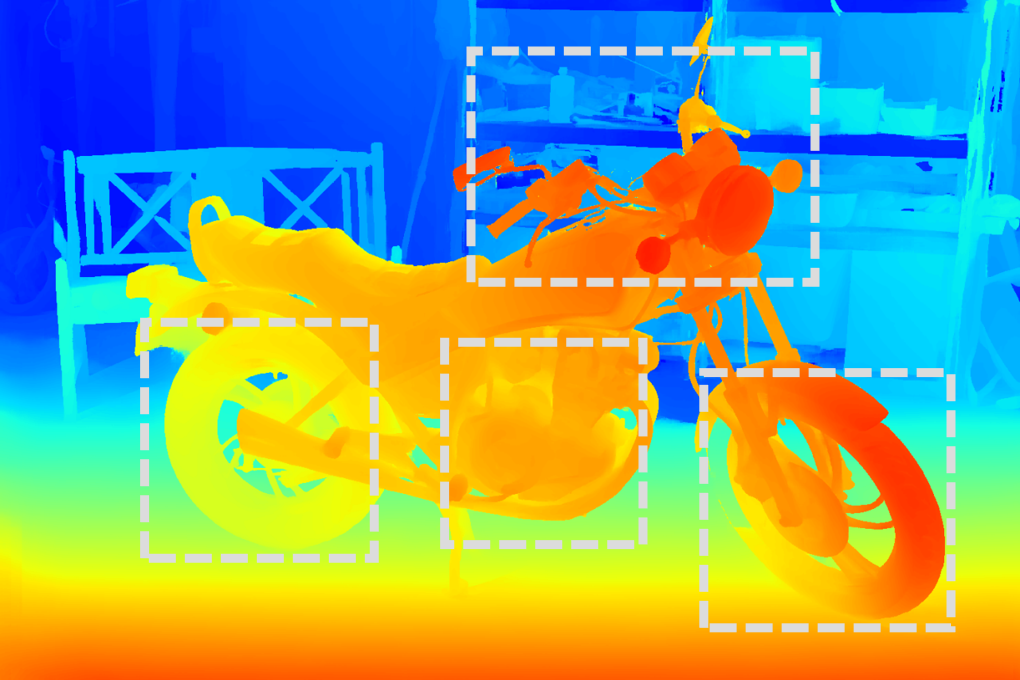








Figure 4: RGB image sample from StereoCarla, illustrating scene realism and environmental variability.
Implementation Considerations
StereoCarla is designed for scalable training and evaluation of stereo algorithms. The dataset is compatible with standard deep stereo architectures and supports extensive data augmentation. The high resolution and diversity require substantial computational resources for training, but the improved generalization justifies the cost for applications demanding robustness (e.g., autonomous driving, robotics).
- Resource Requirements: Training on StereoCarla with transformer-based backbones (e.g., SwinTransformer) typically requires multi-GPU setups and large memory footprints.
- Deployment: Models trained on StereoCarla can be deployed in real-world systems with varied camera configurations and environmental conditions, reducing the need for domain-specific fine-tuning.
Implications and Future Directions
StereoCarla sets a new standard for synthetic stereo datasets by systematically addressing the limitations of prior benchmarks. Its diversity in geometry, viewpoint, and semantics enables the development of stereo matching algorithms with strong cross-domain generalization. The dataset's extensibility and compatibility with multi-source training suggest its utility as a foundation for future research in robust depth perception.
Potential future directions include:
Conclusion
StereoCarla provides a high-fidelity, diverse, and scalable synthetic dataset for stereo matching, enabling superior generalization across domains. Comprehensive experiments demonstrate its effectiveness as both a standalone and backbone dataset for multi-source training. The work underscores the critical role of dataset diversity—geometric, viewpoint, and semantic—in advancing robust stereo vision for autonomous systems.