- The paper introduces SHaRe-RL, a human-in-the-loop reinforcement learning framework that significantly improves learning efficiency in industrial assembly tasks.
- It employs task-frame formalism and adaptive manipulation primitives to dynamically adjust control settings, ensuring safe exploration in contact-rich environments.
- Experimental results show a 95% success rate, outperforming skilled human operators and reducing the need for continuous human intervention.
This paper proposes SHaRe-RL, an innovative reinforcement learning framework tailored for high-mix low-volume (HMLV) industrial assembly applications. By embedding structured, interactive reinforcement learning techniques, SHaRe-RL aims to bridge the gap between the stringent requirements of HMLV tasks and the flexibility offered by RL solutions in robotic applications.
Introduction and Motivation
High-mix low-volume manufacturing environments require systems that can perform with precision and reliability while adapting to a diverse range of products and unpredictable conditions. Current robotic solutions often fall short, being either too brittle or prone to inefficiencies in sample requirements, especially in contact-heavy scenarios. SHaRe-RL innovatively merges structured skill sets, human demonstrations, and real-time operator adjustments to enhance learning efficiency and safety in industrial tasks.
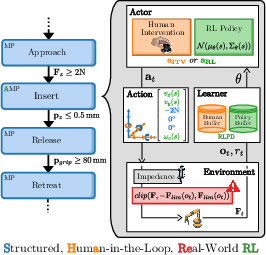
Figure 1: System overview of SHaRe-RL. Structure (blue), interaction (yellow), and safety (red) combine to make industrial RL both practical and reliable.
Methodology
Human-in-the-Loop RL
A human-in-the-loop approach is central to SHaRe-RL, incorporating operator expertise directly into the learning process. Skilled operators provide critical demonstrations and can intervene during training to correct robot actions, accelerating convergence and preventing unsafe states. This integration creates a synergistic loop between human knowledge and machine learning capabilities, enabling the training to be both rapid and adaptable without compromising safety.
Task-Level Priors: TFF and MP-Nets
SHaRe-RL uses task frame formalism (TFF) and manipulation primitives (MPs) to guide exploration and learning. MPs, which represent fundamental manipulation skills, are composed into MP-Nets that outline state transitions based on specific stop conditions. By introducing adaptive MPs, the framework adapts control variables dynamically in response to task requirements, focusing learning efforts on the most relevant phases of the task.
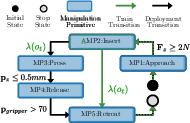
Figure 3: MP-Net for the HanDD connector insertion. The controller setpoints for each direction of the MPs are shown in the table below the diagram. Adaptive MPs, learned stop conditions, and variable setpoints are colored green.
Adaptive Safety Limits
Safety in contact-rich environments is achieved through adaptive force limits that govern interaction during exploration. These limits are dynamically adjusted based on the measured forces in real-time, striking a balance between allowing flexibility in free space and ensuring safety during contact. This approach prevents hardware damage and enhances sample efficiency by minimizing the impact of large, uncontrolled force applications.
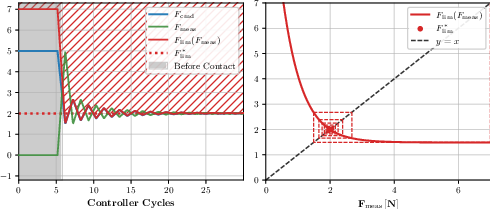
Figure 4: Adaptive force limits under ideal conditions. Left: Time response of a stable adaptive limit. Right: Phase-plane cobweb plot illustrating the recurrence.
Experimental Setup and Results
The evaluation was conducted using Harting Han-Modular connectors with stringent tolerance requirements. The experimental setup included a UR3e robot equipped with sensors and a force control spine optimized for SHaRe-RL tasks.

Figure 2: Experimental setup and task. Top: UR3e robot and Harting HanDD industrial connector used for evaluation. Bottom: External view and corresponding policy input over time.
The results showcased SHaRe-RL's enhanced learning capabilities, with a significant success rate of 95% on challenging tasks, eventually surpassing even skilled human operators' efficiency. The methodology effectively reduced the necessary human guidance over time, demonstrating a steady shift towards increased autonomy.
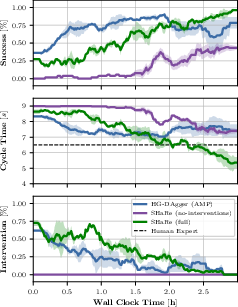
Figure 5: Main comparison of learning approaches. Success rate, cycle time, and intervention rate vs. wall-clock time.
Conclusion
SHaRe-RL represents a significant advancement in structured reinforcement learning, combining human expertise with automated learning to enhance the adaptability and safety of robotic systems in industrial settings. The framework's ability to integrate various sources of prior knowledge optimizes its learning trajectory, paving the way for more flexible and robust robotic solutions suitable for SMEs without extensive robotics expertise.
The future trajectory of SHaRe-RL includes extending scalability across longer and more complex assembly processes, improving generalization to various tasks, and reducing engineering overhead through integration with planning tools. These advancements will further the adoption of RL in industrial applications, contributing to increased operational efficiencies and reduced dependency on highly specialized human intervention.