- The paper shows that advanced LLM-based rerankers can significantly reduce reliance on machine translation in cross-lingual retrieval pipelines.
- It compares dense bi-encoders with BM25 and finds that dense models excel in high-resource languages while MT remains beneficial for low-resource pairs.
- The study reveals that both pairwise and listwise reranking approaches face a performance ceiling, highlighting the need for further model scaling and hybrid strategies.
Introduction
This paper systematically investigates the performance of LLMs as rerankers in cross-lingual information retrieval (CLIR) pipelines. The research distinguishes itself by evaluating both passage-level and document-level retrieval across typologically diverse language pairs—including low-resource African languages—while explicitly disentangling the effects of machine translation (MT) in the retrieval and reranking pipeline. Contrary to most prior studies, which heavily depend on early-stage machine translation, this work develops experimental designs to elucidate whether recent state-of-the-art multilingual bi-encoders and listwise or pairwise LLM-based rerankers can obviate the need for MT, and under which conditions translation still provides an empirical benefit.
The study addresses four primary research questions:
- Comparative effectiveness of dense multilingual bi-encoders and sparse BM25 in initial cross-lingual retrieval.
- Interactions between first-stage retrievers and LLM rerankers, including their performance in high- vs. low-resource settings.
- Comparative performance of pairwise versus listwise reranking approaches in CLIR settings.
- Effect of document length on reranking efficacy.
The methodology leverages two benchmarks: CLEF 2003 (European high-resource languages) and CIRAL (African low-resource languages), spanning nine CLEF language pairs and four CIRAL pairs, with a broad set of open-source and proprietary LLM rerankers.
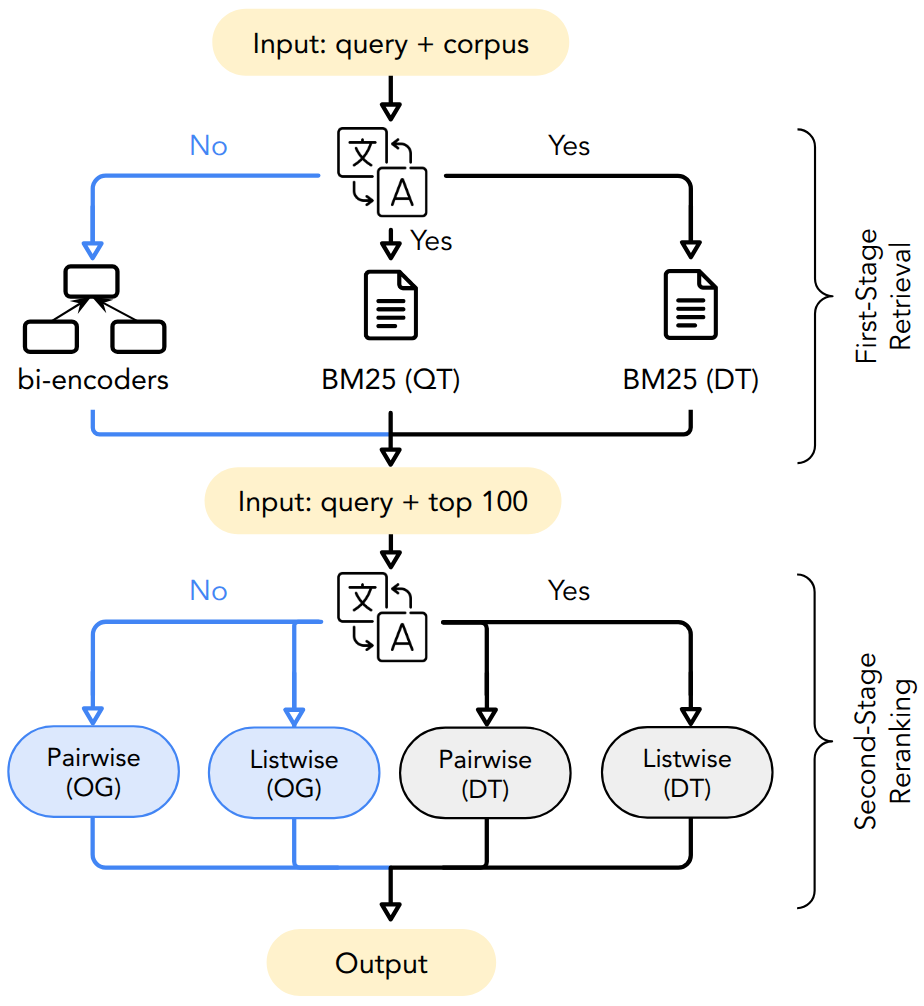
Figure 1: Overview of the CLIR pipeline with configurations for monolingual (query/document translation, QT/DT) and cross-lingual (original documents, OG) setups and the paths evaluated in this study.
Multi-Stage CLIR Pipeline and Experimental Setup
The experimental pipeline implements a canonical multi-stage retrieval design: an initial fast retriever is followed by a more computationally intensive reranker. The first-stage retrieval employs a mix of lexical BM25 (sparse) and dense transformer-based bi-encoders (mGTE, M3, E5, RepLLaMA, NV-Embed-v2). For BM25, retrieval is performed both with translated queries (QT) and with translated documents (DT) to analyze the cost/benefit of MT at this stage.
Second-stage reranking investigates LLMs in both listwise (RankZephyr, RankGPT3.5, RankGPT4.1) and pairwise (Llama-3.1-8B-Instruct, Aya-101) settings, utilizing recent instruction-tuned open and closed-source models. Document translation is also tested at this stage to expose whether language matching between queries and candidate documents substantially aids LLMs.
Datasets vary in passage/document granularity and linguistic diversity (CLEF: German, Finnish, Italian, Russian, English; CIRAL: Hausa, Somali, Swahili, Yoruba). Translation quality and document size are controlled to isolate their impact on downstream rankings.
Empirical Results
First-Stage Retrieval: Dense vs. Sparse Models
Evaluation demonstrates that on CLEF, the dense bi-encoder NV-Embed-v2 yields the highest mean average precision (MAP), slightly outperforming BM25-DT, while on CIRAL, the M3 model is the strongest, particularly in low-resource language pairs where lexical translation methods underperform. Critically, the optimal first-stage model is dataset-dependent: architecture, multilanguage support, and the quality/diversity of training data exert significant effects. Dense retrievers trained on rich, diverse data distributions substantially outstrip pure lexical approaches in most modern settings, but translation remains competitive where dense retrieval lacks coverage.
Impact of Second-Stage LLM Reranking
On both CLEF and CIRAL, all LLM rerankers effect consistent—but not uniform—improvements over first-stage results. The magnitude of gain is correlated with first-stage retriever quality; improvements are greater when the initial retrieved pool is of higher fidelity. Notably, RankGPT4.1 in listwise settings dominates, achieving improvements over all language pairs and surpassing the gains from weaker first-stage or translation-based candidates.
A critical observation is the diminishing returns of document translation as reranking models improve: When high-quality bi-encoders and robust LLM rerankers are deployed, the improvement provided by translating candidate documents often shrinks to statistical insignificance. This effect is especially pronounced with RankGPT4.1, for which OG and DT settings converge in performance—a strong empirical refutation of the necessity of MTrouted document pipelines under state-of-the-art listwise reranking.
Pairwise vs. Listwise Reranking: Competitiveness and Robustness
Pairwise reranking using instruction-tuned open models such as Aya-101 achieves competitive performance relative to listwise closed-source rerankers, particularly on original language candidate sets or in language pairs underrepresented during pretraining of the listwise rerankers. This underscores the robustness and viability of pairwise approaches, especially when domain- or language-specific instruction tuning is feasible.
Reranking Upper Bound and the Ceiling Effect
By constructing oracular rankings (placing all known relevant items at the top of the candidate set), the paper quantifies realized versus potential improvement. Even with the strongest rerankers, the maximum proportion of the available gains (against the oracle) that can be realized hovers between 32% and 46%. This identifies a substantial and persistent glass ceiling for current LLM rerankers in CLIR, particularly when both query and candidate documents remain untranslated. Introduction of translation narrows, but does not eliminate, the gap, hinting at latent limitations in the cross-lingual alignment and contextualization of current LLMs.
Document Length Effects
Document chunk length has a marked impact on reranking. Listwise rerankers such as RankZephyr peak at mid-sized chunks (128 tokens), with longer contexts degrading performance due to the dilution of relevant signal. In contrast, pairwise rerankers, especially those leveraging high-quality dense retrievers, show resilience or even improvement with longer contexts, suggesting greater robustness to verbosity or contextual noise.
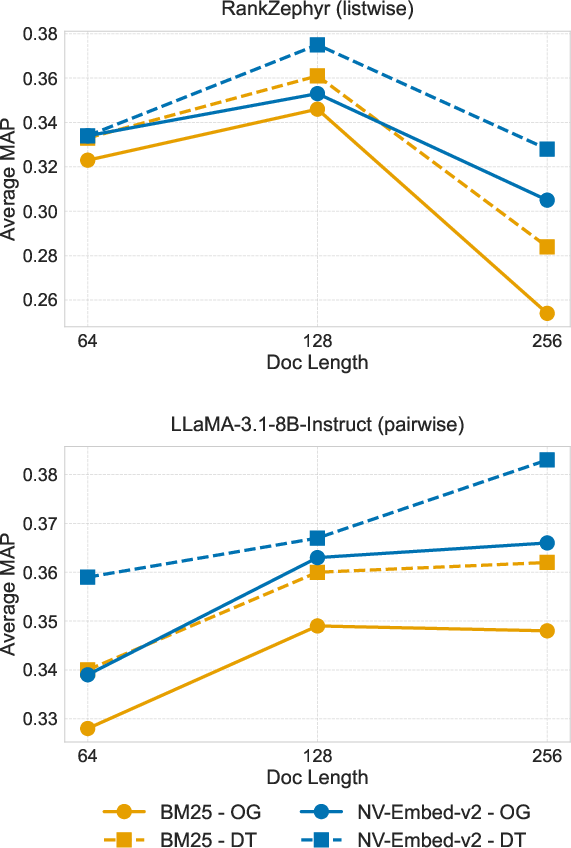
Figure 2: Reranking performance variation as a function of document length, averaged across CLEF language pairs and stratified by reranker and retriever types.
Practical and Theoretical Implications
The evidence demonstrates that state-of-the-art dense multilingual bi-encoders, in conjunction with instruction-tuned LLM reranking (especially listwise configurations), can substantially mitigate the dependence on machine translation in CLIR. However, for genuinely low-resource language pairs or in domains with scant high-quality multilingual pretraining data, the benefit of MT persists.
The persistent ceiling effect in reranking performance reveals a fundamental limitation in both listwise and pairwise LLM architectures for CLIR, even as pretraining scales and reranking strategies diversify. This implies that further model scaling, more sophisticated task-specific instruction tuning, or novel hybrid representation architectures (e.g., integrating cross-lingual alignment signals at pretraining) will be necessary to close the gap between empirical and theoretical maxima.
The interaction of document length with model and retriever characteristics underscores the need for input-length sensitivity analysis in all deployment pipelines—static context windows imposed by LLM inference APIs may antagonize reranking quality if not carefully optimized.
Hybrid retrieval strategies (ensemble fusion of lexical and dense rerankers) further improve candidate pools, but the upper-bound analysis demonstrates that such approaches remain bottlenecked by retrieval-stage recall: relevant items missed by first-stage retrieval are irrecoverable, regardless of reranker strength.
Conclusion
This paper provides a rigorous and holistic evaluation of LLM-based reranking for cross-lingual retrieval, establishing several key findings:
- High-quality dense bi-encoders often outperform machine translation-facilitated lexical retrieval as first-stage retrievers.
- Advanced instruction-tuned LLM rerankers can render document translation in reranking superfluous in many cross-lingual settings, barring extreme resource constraints or pretraining mismatches.
- Pairwise reranking proves robust, especially with open-source instruction-tuned models, and achieves parity with listwise approaches in many settings.
- Substantial headroom persists between achievable and theoretical reranking performance, particularly in true cross-lingual scenarios.
- Optimal document chunk sizes are a function of reranker and retriever configuration and must be tuned for deployment.
Future research in AI for CLIR will necessarily revolve around deeper pretraining across long-tail languages and domains, hybrid and adaptive multi-stage retrieval architectures, and instruction/data curation strategies that enhance cross-lingual contextualization and alignment.