Self-Improving Embodied Foundation Models
Abstract: Foundation models trained on web-scale data have revolutionized robotics, but their application to low-level control remains largely limited to behavioral cloning. Drawing inspiration from the success of the reinforcement learning stage in fine-tuning LLMs, we propose a two-stage post-training approach for robotics. The first stage, Supervised Fine-Tuning (SFT), fine-tunes pretrained foundation models using both: a) behavioral cloning, and b) steps-to-go prediction objectives. In the second stage, Self-Improvement, steps-to-go prediction enables the extraction of a well-shaped reward function and a robust success detector, enabling a fleet of robots to autonomously practice downstream tasks with minimal human supervision. Through extensive experiments on real-world and simulated robot embodiments, our novel post-training recipe unveils significant results on Embodied Foundation Models. First, we demonstrate that the combination of SFT and Self-Improvement is significantly more sample-efficient than scaling imitation data collection for supervised learning, and that it leads to policies with significantly higher success rates. Further ablations highlight that the combination of web-scale pretraining and Self-Improvement is the key to this sample-efficiency. Next, we demonstrate that our proposed combination uniquely unlocks a capability that current methods cannot achieve: autonomously practicing and acquiring novel skills that generalize far beyond the behaviors observed in the imitation learning datasets used during training. These findings highlight the transformative potential of combining pretrained foundation models with online Self-Improvement to enable autonomous skill acquisition in robotics. Our project website can be found at https://self-improving-efms.github.io .





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to get better at tasks on their own, using ideas that have recently worked well for LLMs (like the ones behind chatbots). The authors show a two-step training recipe that first teaches a robot to imitate human examples and to estimate how many steps remain until it finishes a task, and then lets the robot practice by itself using those estimates as a kind of “built-in” reward. This makes robots learn faster, require less human supervision, and even pick up new skills they weren’t directly shown.
Key Objectives
Here are the main questions the paper tries to answer:
- Can robots improve beyond simple imitation if we add a second training stage where they practice and learn from their own experience?
- Is this two-stage approach more efficient than just collecting a lot more human demonstrations?
- Is it reliable enough to use on real robots, not just in simulation?
- How much does starting from a powerful, pretrained “foundation model” help?
- Can robots learn new kinds of behaviors they weren’t taught in the original dataset?
How They Did It
Think of this like training for a sport:
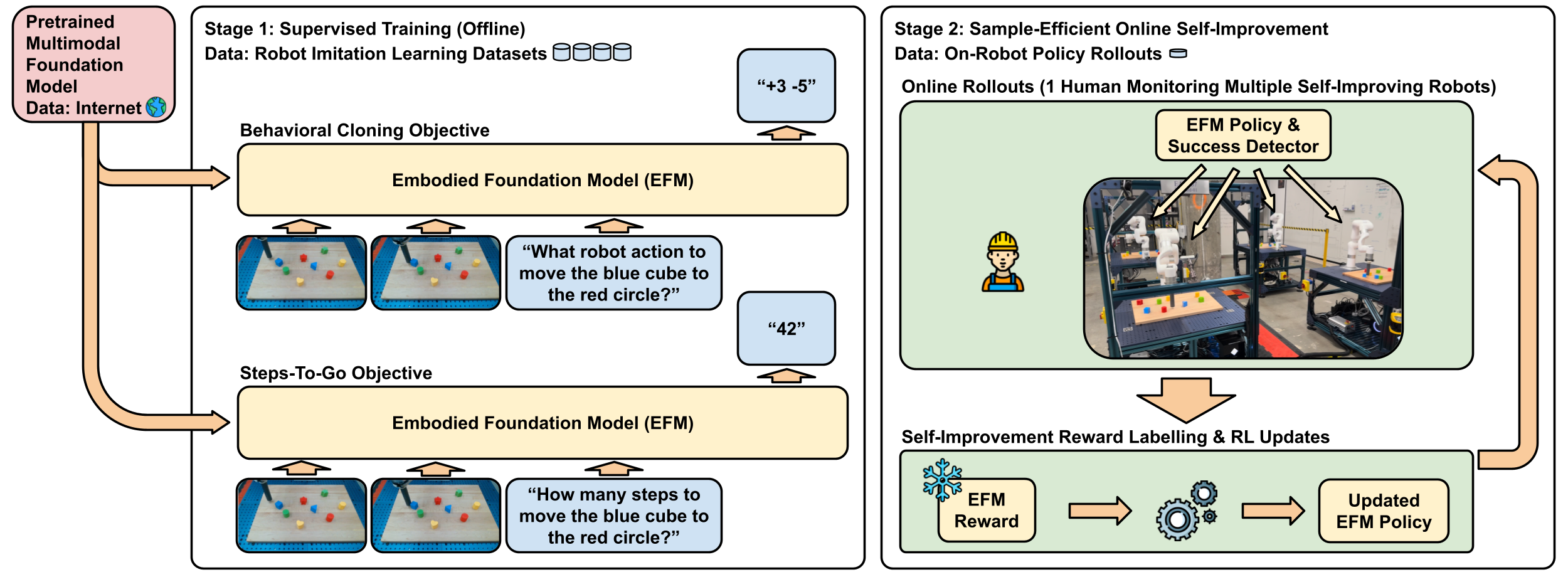
- Stage 1: Supervised Fine-Tuning (SFT)
- What it is: The robot watches human examples and learns to copy them (this is called “behavioral cloning”). At the same time, it learns to predict “steps-to-go,” which means estimating how many actions remain before the task is done.
- Analogy: It’s like a player watching videos of a coach and also learning to guess how many moves are left until scoring.
- Stage 2: Self-Improvement
- What it is: The robot uses its own “steps-to-go” predictions to measure progress while practicing. If the number of steps-to-go gets smaller after it takes an action, that’s a positive sign (a “reward”). If it gets bigger, that’s a negative sign.
- Success detector: The robot considers a task “done” when the predicted steps-to-go is very close to zero. This lets it end practice runs at the right time without needing a human to say “you did it.”
- Reinforcement learning (RL): The robot then improves its policy using a simple RL method, guided by these self-created rewards. A single human can oversee several robots at once, stepping in only to reset things when necessary.
Why this works:
- The “steps-to-go” acts like a built-in GPS for tasks: every action that reduces the remaining “distance” is rewarded. This makes the training naturally well-shaped and stable, without requiring complex hand-crafted reward functions.
Main Findings and Why They Matter
The paper reports results on two robot setups (LanguageTable and Aloha), both in simulation and the real world:
- Big performance gains with little extra practice:
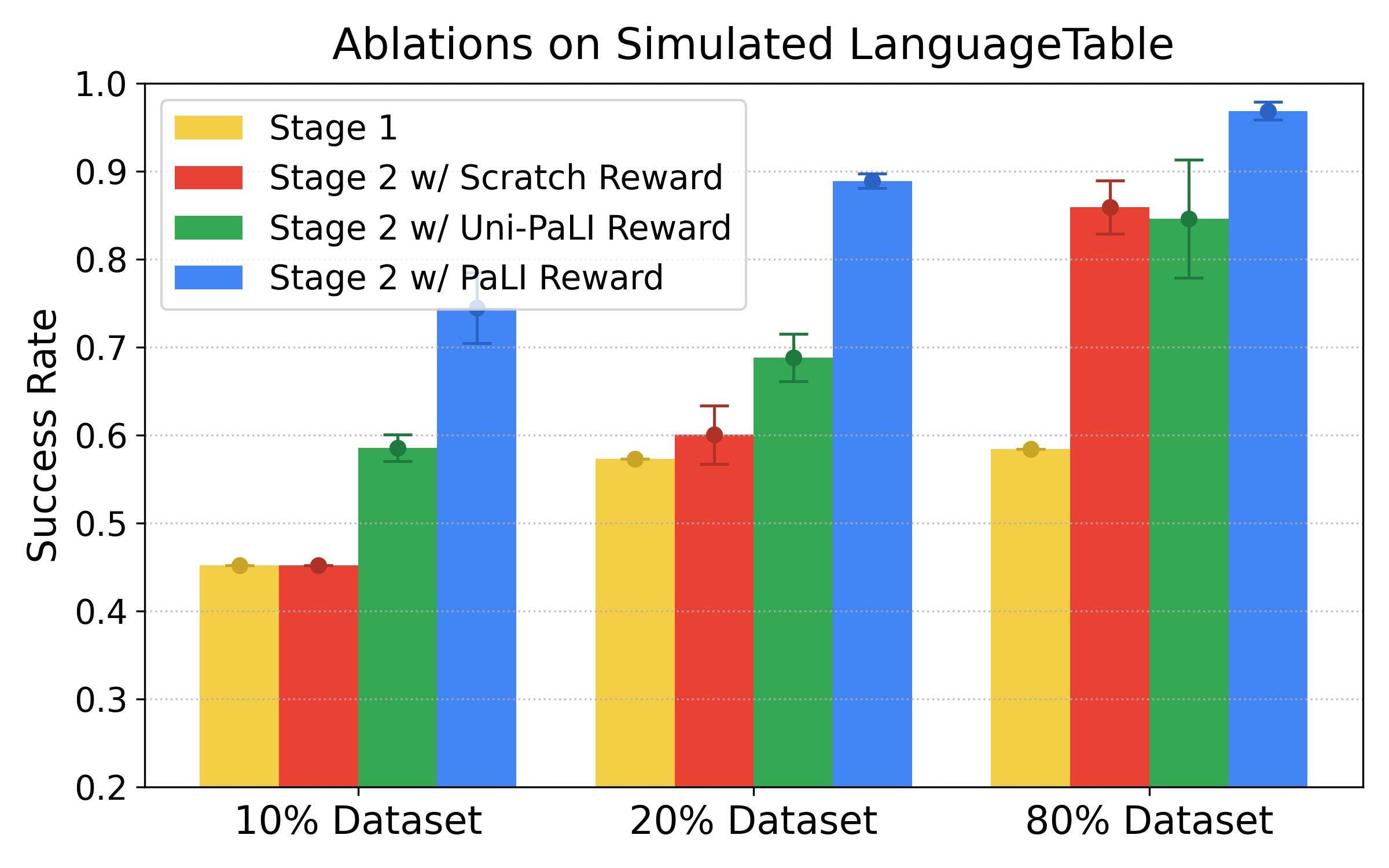
- In LanguageTable, adding about 1–3% more episodes through Self-Improvement boosted success rates dramatically (for example, from around 45–63% up to about 75–88%).
- These gains beat what you get from collecting many more human demos. In one case, adding 10% self-practice beat adding 8× more imitation data.
- Works in the real world:
- On real LanguageTable robots, Self-Improvement raised success to roughly 87–88% with only around 3% extra practice episodes.
- One person could manage several robots at once because the robots knew when to stop and how to score their own progress.
- Helps with harder tasks (Aloha two-arm insertion):
- With 5,000 imitation episodes plus 2,500 self-practice episodes, performance surpassed models trained with 10,000 imitation episodes and approached those trained with 15,000—showing strong sample efficiency.
- Pretraining is crucial:
- Starting from a powerful multimodal foundation model (one trained on huge web-scale image+text data) was key. Versions without proper multimodal pretraining were slower and less effective.
- The pretrained model made better rewards and success predictions, which sped up learning.
- Generalization to new domains and new skills:
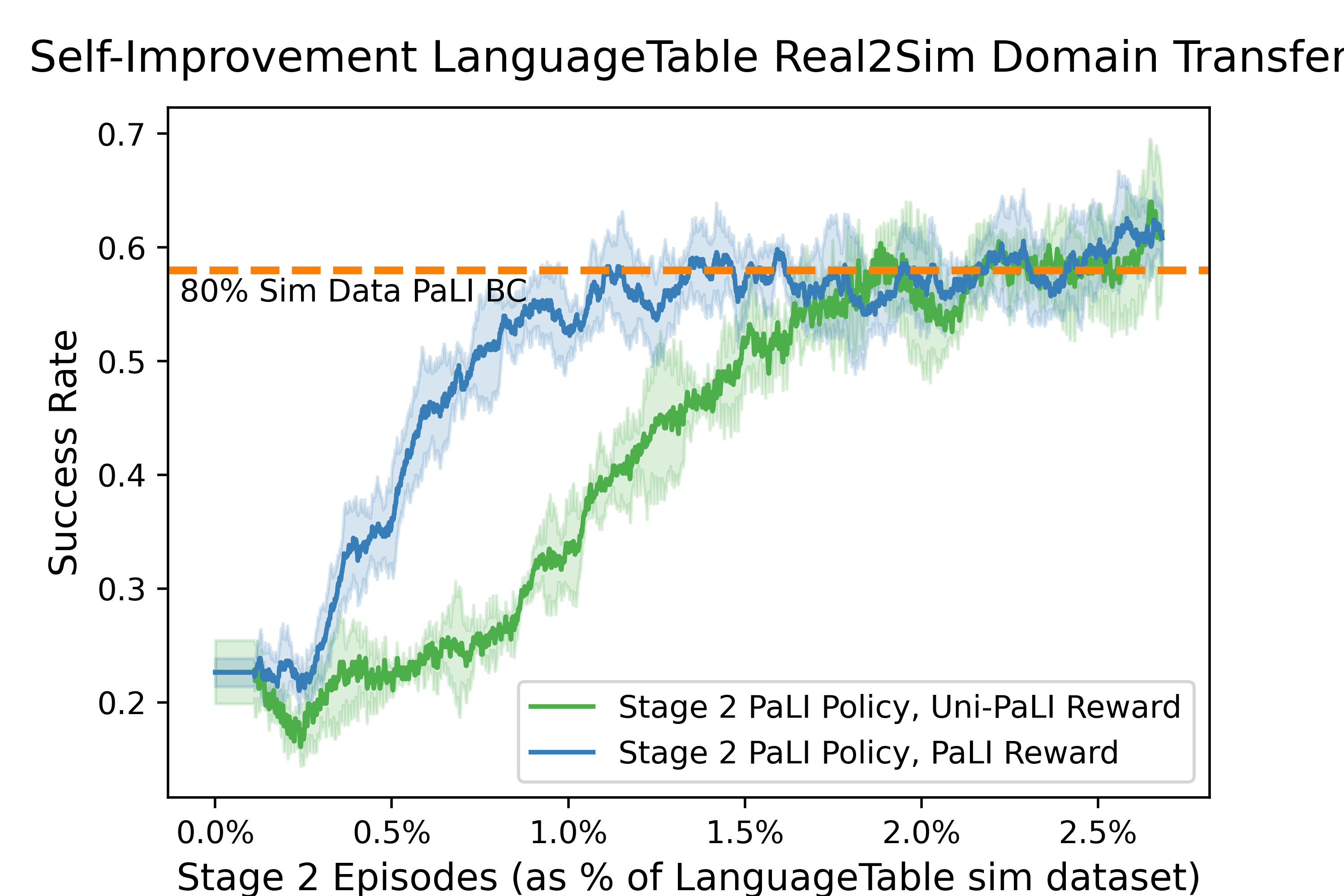
- Real-to-sim transfer: A model trained on real robot data improved quickly when practicing in simulation, reaching performance similar to training on most of the simulation dataset—using only a small amount of new practice.
- Learning a genuinely new behavior (BananaTable): Without any banana examples in the original dataset, robots learned how to push a banana effectively (it tends to spin if you push it wrong). After around 8 hours of self-practice, success rose from about 63% to about 85%, and the robot discovered smart pushing strategies on its own.
Why this is important:
- It shows robots can improve themselves efficiently, with minimal human effort.
- It reduces the need for hand-crafted rewards and lots of new labeled data.
- It unlocks learning of new behaviors beyond what was in the training set.
Implications and Impact
- Scalable robot learning: A single operator can oversee a fleet of robots practicing and improving on their own, saving huge amounts of time and effort.
- Fewer custom reward hacks: The “steps-to-go” trick gives robots a reliable, general way to measure progress without dense instrumentation or complex code.
- Faster adaptation to new tasks: Because the reward and success signals are learned from a pretrained foundation model, robots can practice and acquire skills for tasks they haven’t seen before.
- Closer to the LLM playbook: Just like chatbots became better after a reinforcement learning fine-tuning stage, robots benefit from a similar post-training step.
In short, this paper presents a practical, powerful recipe for robot learning: start with a strong foundation model, teach it to imitate and estimate steps-to-go, then let it practice using its own progress signals. This makes robots more capable, more independent, and ready to learn new skills in the real world.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper. These items are intended to guide future research and are grouped only as a single list for clarity.
- Calibration of steps-to-go predictions: The paper relies on the expected value of the steps-to-go distribution as a reward signal but does not assess calibration, sharpness, or bias of that distribution. How well-calibrated are predictions across tasks, embodiments, and viewpoints?
- Distributional vs. expected rewards: Only the expected steps-to-go is used. The impact of using full distributional signals (e.g., quantiles, CVaR, or risk-sensitive objectives) on learning speed, stability, and safety remains unexplored.
- Dependence on demonstration speed: Steps-to-go labels implicitly encode the teleoperator’s speed and control frequency. How to normalize for operator timing, latency, or control-rate changes so that “distance” reflects task difficulty rather than human speed?
- Reward model drift and co-adaptation: Stage 2 uses a frozen Stage 1 checkpoint to compute rewards and success, but both originate from the same pretraining/fine-tuning pipeline. How robust is this to mis-specification and feedback loops? Would joint or alternating training of policy and reward model improve or destabilize learning?
- Reward hacking and perceptual shortcuts: There is no analysis of whether the policy can learn to manipulate camera viewpoints, gripper poses, or scene configurations to reduce predicted steps-to-go without achieving true task success. How susceptible is the method to such exploitability?
- Success detection robustness and sensitivity: Success is defined via a threshold on d(o, g). Sensitivity to the threshold s, false positives/negatives across tasks, and calibration across embodiments/domains are not evaluated. Can adaptive or learned thresholds reduce failure modes?
- Partial observability and unobservable success: In Aloha, success is not fully visible and a constant reward bonus is added when success occurs. How to systematically handle partial observability or unobservable outcomes (e.g., via additional sensors, self-supervised success classifiers, cross-view fusion)?
- Exploration-exploitation trade-offs: The shaped reward implicitly regularizes behavior toward states where μ (dataset policy) performs well, potentially limiting exploration. What mechanisms (e.g., entropy bonuses, optimistic objectives, intrinsic motivation) best mitigate conservative behaviors while retaining stability?
- Algorithmic scope: Only on-policy REINFORCE is evaluated. The relative benefits/risks of off-policy algorithms, actor-critic methods, value estimation, trust-region methods, and advantage baselines (beyond the implicit baseline in the shaping) are not examined.
- Hyperparameter sensitivity: No systematic study of γ, scaling constant c, success threshold s, episode length, or replay size. How sensitive are outcomes to these choices, and what are robust defaults?
- Action tokenization limits: Policies inherit RT-2 tokenized actions. The impact of action discretization versus continuous controls (e.g., diffusion/flow-based action heads) on precision, stability, and sample-efficiency is not studied.
- Long-horizon credit assignment: The approach is evaluated on moderate horizons. How well does the method scale to very long-horizon, multi-stage tasks where steps-to-go estimation and shaped rewards may become less informative?
- Continual learning and catastrophic forgetting: After Self-Improvement (e.g., BananaTable), does performance on earlier tasks regress? How to maintain or improve prior skills while acquiring new ones (e.g., via regularization, rehearsal, or modular heads)?
- Curriculum design and instruction sampling: Stage 2 instruction sampling is not analyzed. Can curricula, adaptive task sampling, or active goal selection accelerate learning and reduce failure plateaus?
- Sim2Real vs. Real2Sim: Only Real2Sim is studied. How well does the method support true Sim2Real transfer, and what domain randomization, adaptation, or reward-model techniques are needed for reliable transfer?
- Embodiment diversity and scaling: Results are shown on LanguageTable and Aloha. How does the framework generalize to other robots, higher-DoF systems, mobile manipulation, tactile sensing, multi-camera rigs, or variable control rates?
- Complex object interaction and deformables: Beyond BananaTable, generalization to multi-object coordination, deformable manipulation, contact-rich assembly, and underactuated tasks remains to be demonstrated.
- Safety and constraint handling: There is minimal discussion of physical safety, collision avoidance, force/torque limits, or constraint satisfaction. How to integrate safe RL, shielded policies, or model-predictive constraints into Self-Improvement?
- Autonomous resets and supervision minimization: A human is needed for resets and rare interventions. Can the system learn robust reset policies, detect unsafe states earlier, or schedule practice to reduce human overhead further?
- Uncertainty-aware control: Although the model outputs a distribution over steps-to-go, the policy optimization ignores uncertainty. How can uncertainty drive risk-aware control, exploration, and termination decisions?
- Reward invariance to environment changes: Steps-to-go is tied to time/steps. Variations in control frequency, latency, or robot speed can shift the “distance” metric. How to make the reward invariant (e.g., normalize by expected dynamics, learned time warping)?
- Pretraining scope and scaling laws: Only PaLI 3B is used. How do different VLM families, parameter scales, multimodal pretraining recipes, and alignment strategies affect Self-Improvement quality and sample-efficiency?
- Failure-mode analysis: The paper reports aggregate success rates but lacks detailed diagnostics (per-instruction breakdowns, lighting/occlusion robustness, camera failures, gripper wear, or network dropouts). What are the dominant failure modes of reward and success detection?
- Theoretical guarantees under reward error: The shaping intuition uses Vμ, but actual rewards use an approximate d(o, g). What policy-improvement guarantees hold under bounded reward estimation error and partial observability?
- Human-time and compute accounting: Sample-efficiency is reported in episodes, but detailed accounting of robot-hours, human-hours, and compute for Stage 1/2 (and their trade-offs) is missing. What is the true cost curve versus purely supervised scaling?
- Language robustness and compositionality: Robustness to ambiguous, compositional, or multi-lingual instructions in Stage 2 is not evaluated. How does Self-Improvement perform with noisy, underspecified, or adversarial language?
- Multi-robot learning dynamics: Multiple robots are used in parallel but without analysis of data de-correlation, shared replay, asynchronous updates, or fleet-level scheduling. How to optimally coordinate fleets for faster and safer learning?
- Success metrics beyond success rate: Efficiency, path optimality, force profiles, energy usage, cycle time, and hardware wear are not reported. How does Self-Improvement affect these operational metrics?
- Generality of success detection choice: The paper prefers thresholding d(o, g) over an explicit success classifier but does not systematically compare them. When is explicit success classification superior, and can hybrid methods help?
- Robustness to adversarial or OOD visual inputs: No tests against occlusions, adversarial patterns, or drastic viewpoint shifts that could mislead the reward model. How to harden the reward and success detectors against OOD conditions?
- Integration with hindsight relabeling and offline RL: The method is orthogonal to hindsight relabeling or offline RL pipelines. Can combining them further improve stability and data efficiency, or introduce bias?
- Generalization measurement breadth: Only a few generalization axes are tested (Real2Sim, BananaTable). A broader suite (task compositionality, object categories, textures, lighting, dynamics) would better characterize limits.
- Ethical, legal, and data provenance considerations: Web-scale pretraining may include robot-related data; potential contamination effects, licensing constraints, and privacy issues are not discussed. How do these factors impact deployment?
Glossary
- Ablation: Systematic removal or alteration of components or conditions to study their effect on performance. Example: "Further ablations highlight that the combination of web-scale pretraining and Self-Improvement is the key to this sample-efficiency."
- Baseline (in policy gradients): A reference value subtracted from returns to reduce variance in gradient estimates. Example: "The baseline V\mu(o_{t}, g) leads to lower variance estimates that are particularly useful in our case of using the REINFORCE estimator."
- Behavioral cloning: Supervised learning approach that mimics expert actions from demonstrations. Example: "has been limited to behavioral cloning (i.e. supervised learning)"
- Bimanual: Involving two manipulators/arms working together. Example: "the bimanual Aloha manipulation platform"
- Bootstrapping: Using estimates of future returns to update current value targets, which can cause instability combined with off-policy learning and function approximation. Example: "Off-Policy Learning and Bootstrapping."
- Code-As-Rewards: Using LLMs to write reward functions (code) for RL tasks. Example: "that we dub ``Code-As-Rewards""
- Contrastive learning: Learning representations by bringing related pairs closer and pushing unrelated pairs apart. Example: "design a contrastive learning objective"
- CVaR: Conditional Value at Risk; a risk-sensitive objective focusing on tail outcomes. Example: "CVaR~\citep{alexander2004comparison} for risk-aware policies"
- Deadly triad: The combination of function approximation, bootstrapping, and off-policy learning that can cause divergence in RL. Example: "the deadly triad~\citep{van2018deep}"
- Diffusion models: Generative models that learn to reverse a noise-adding process, used here as action heads. Example: "diffusion models~\citep{octo_2023,wen2024tinyvla}"
- Discount factor: Parameter that down-weights future rewards in RL returns. Example: "where is the discount factor used in the Stage 2 RL updates."
- Distributional RL: RL that models the full distribution of returns instead of just their expectation. Example: "distributional RL~\citep{bdr2023}"
- Embodied Foundation Models: Foundation models adapted to control physical agents (robots) via perception-action interfaces. Example: "significant results on Embodied Foundation Models."
- Flow matching: A generative modeling technique for mapping simple to complex distributions, used for action heads. Example: "flow matching~\citep{black2024pi_0,intelligence2025pi_}"
- Goal-conditioned: Policies or objectives conditioned on a specified target goal. Example: "goal conditioned behavioral cloning loss"
- Hindsight relabeling: Relabeling trajectories with goals achieved later in the trajectory to augment goal-conditioned learning. Example: "including hindsight-relabelled as well as single-task datasets"
- LLMs: Very large neural LLMs pretrained on web-scale text. Example: "LLMs"
- Monte Carlo returns: Empirical returns computed by summing discounted rewards along trajectories. Example: "Compute Monte Carlo returns using Equation \ref{eq:reward}"
- Multimodal: Involving multiple data modalities (e.g., vision and language) in a single model. Example: "pretrained multimodal foundation model"
- Off-policy learning: Learning about one policy while following another, often via replay; a vertex of the deadly triad. Example: "Off-Policy Learning and Bootstrapping."
- Offline RL: Learning policies from a fixed dataset without further environment interaction. Example: "offline and online RL"
- On-policy RL: Learning using data collected by the current policy. Example: "we chose to perform on-policy RL without data reuse."
- Online RL: Reinforcement learning with continual interaction and data collection during training. Example: "using online RL in order to rapidly improve policy performance"
- PaLI: A vision-language foundation model used as the base for policies. Example: "PaLI 3 billion parameter vision-LLM"
- PD-controller: Proportional-Derivative controller used for simple feedback control. Example: "using a PD-controller we navigate to 5 waypoints"
- Policy parameterization: The specific way actions are represented and generated by the policy model. Example: "we follow the RT-2 policy parameterization and predict tokenized actions."
- Q-Learning: Value-based RL algorithm estimating action-value functions; here in a goal-conditioned form. Example: "goal-conditioned Q-Learning"
- Real2Sim: Transferring from real-world-trained models to simulation domains. Example: "we investigate the inverse problem, Real2Sim transfer, on the LanguageTable domain."
- REINFORCE: A Monte Carlo policy gradient algorithm using sampled returns. Example: "Perform policy updates using REINFORCE loss"
- Replay buffer: A memory storing collected transitions for later training updates. Example: "Initialize empty replay buffer"
- Reward engineering: Manually designing reward functions for RL tasks. Example: "a critical challenge of reinforcement learning for robotics ... is the problem of reward engineering."
- Reward instrumentation: Building systems to measure reward signals in the real world. Example: "difficulty in measuring them in the real world (reward instrumentation)."
- Reward shaping: Modifying rewards by adding potential-based terms to guide learning without changing optimal policies. Example: "is implicitly a shaped reward function"
- RT-2: Method that maps discretized actions into token spaces of VLMs to create robot policies. Example: "equivalent to RT-2"
- Sample-efficiency: Achieving high performance with relatively few data samples. Example: "significantly more sample-efficient than supervised learning alone."
- Semantic generalization: Transferring knowledge of task semantics to new contexts without new behavior learning. Example: "semantic generalization -- such as executing the same pick-and-place motions in new contexts"
- Sim2Real: Transferring policies trained in simulation to real-world deployment. Example: "Sim2Real is an important class of approaches"
- Steps-to-go prediction: Predicting the remaining number of steps to achieve a goal from current observations. Example: "steps-to-go prediction enables the extraction of a well-shaped reward function"
- Success detector: A mechanism for determining when a task goal has been achieved. Example: "a robust success detector"
- Supervised Fine-Tuning (SFT: Supervised post-training phase that adapts a pretrained model to target tasks. Example: "Supervised Fine-Tuning (SFT)"
- Tele-operation: Human-controlled robot operation used to collect demonstration data. Example: "if the dataset was collected via tele-operation"
- Tokenized actions: Discretized action representations emitted as sequences of tokens by language-model-style policies. Example: "predict tokenized actions"
- Uni-PaLI: A PaLI variant with unimodal (separate) vision and language pretraining without joint multimodal fine-tuning. Example: "Uni-PaLI: where the PaLI parameters are initialized from a vision model and LLM, each pretrained separately, unimodally, without any joint multimodal vision-language fine-tuning."
- Value function: Expected cumulative reward from a state (and goal), under a policy. Example: "the undiscounted value function of policy "
- Vision-LLM (VLM): Models jointly processing vision and language for multimodal tasks. Example: "vision-language foundation models (VLMs)"
- Web-scale pretraining: Pretraining on extremely large internet-scale datasets to endow broad capabilities. Example: "due to the web-scale pretraining of the foundation models"
Collections
Sign up for free to add this paper to one or more collections.