- The paper introduces a novel zero-shot method for visual document retrieval by generating detailed textual descriptions with vision-language models and embedding them with a text encoder.
- It achieves an nDCG@5 of 63.4% on the ViDoRe-v2 benchmark, outperforming state-of-the-art supervised multi-vector models.
- The approach supports multilingual and cross-domain retrieval with flexible offline processing to reduce online latency and computational costs.
SERVAL: Surprisingly Effective Zero-Shot Visual Document Retrieval Powered by Large Vision and LLMs
The paper "SERVAL: Surprisingly Effective Zero-Shot Visual Document Retrieval Powered by Large Vision and LLMs" addresses the challenge of Visual Document Retrieval (VDR) by introducing a zero-shot method that utilizes large Vision-LLMs (VLMs) to generate textual descriptions from document images, followed by embedding these descriptions using a text encoder. This method outperforms traditional approaches that rely on specialized bi-encoders trained specifically for this task.
Zero-Shot VDR Approach
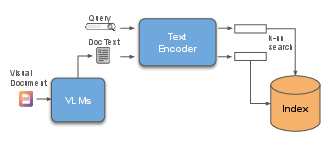
Figure 1: Zero-shot VDR using VLM-generated document descriptions and a pretrained text encoder.
The proposed approach employs a two-step process. First, a VLM generates detailed textual descriptions of document images. These descriptions capture both textual content and visual elements, effectively bridging the modality gap between text and images. Second, a pretrained text encoder embeds these descriptions, facilitating efficient retrieval by mapping queries and documents into a shared semantic space. This method obviates the need for expensive contrastive training on large-scale datasets, instead leveraging the intrinsic capabilities of modern VLMs to understand and describe visual content in natural language. The decoupled architecture allows for flexibility in combining the best available VLMs and text encoders, optimizing performance without task-specific training data.
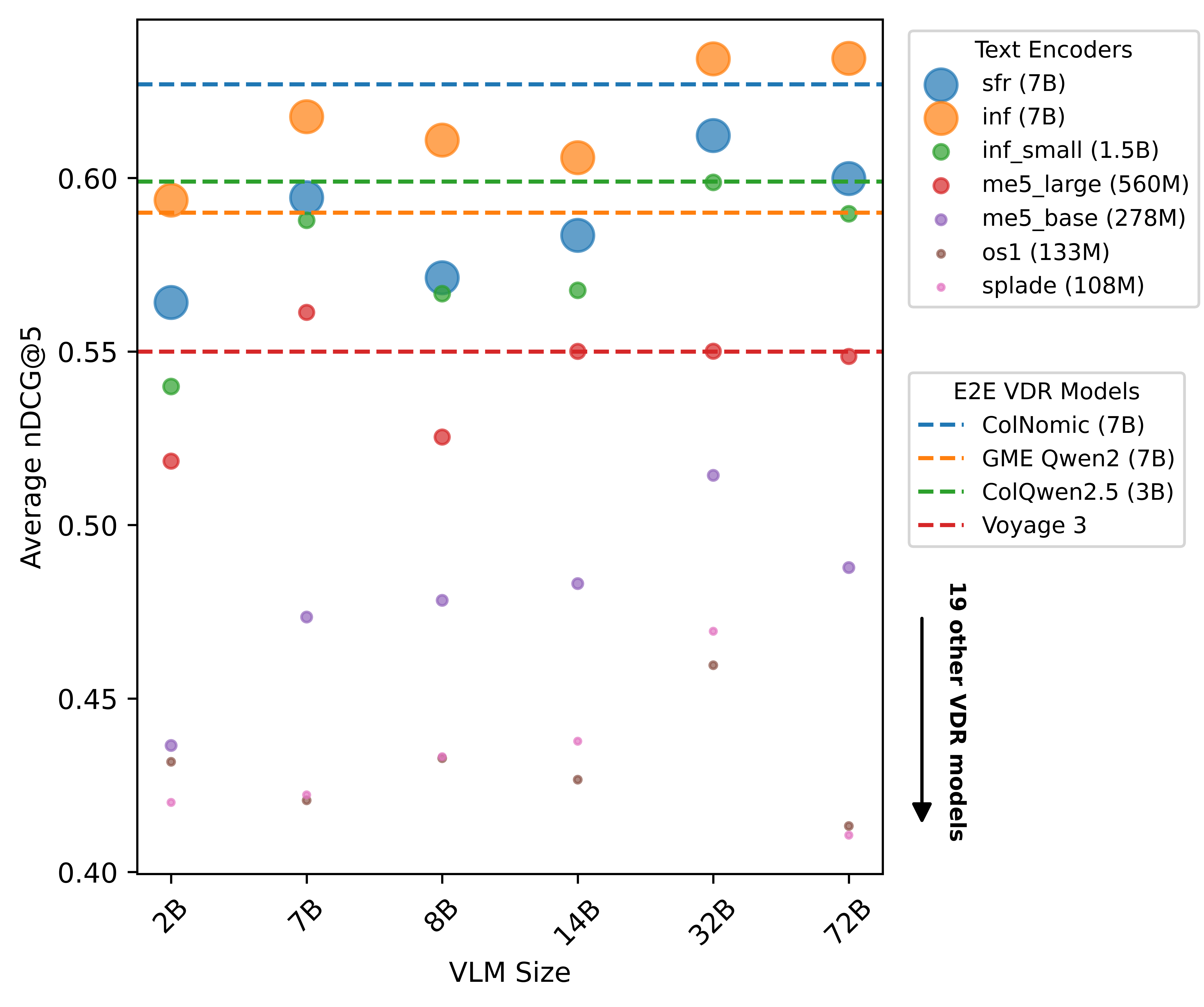
Figure 2: nDCG@5 for zero-shot Visual Document Retrieval using VLMs and text encoders of varying scales. Despite no task-specific training, our zero-shot method could compete with end-to-end models explicitly trained for VDR on large-scale text-(document) image datasets.
The zero-shot method exhibits competitive performance, achieving an nDCG@5 of 63.4% on the ViDoRe-v2 benchmark, which surpasses the best supervised multi-vector models. This demonstrates that high-quality VLM-generated descriptions are sufficient for effective VDR. The findings also show that scaling the text encoder yields better improvements than scaling the VLM, with large VLMs benefiting most from strong text encoder integrations.
Implementation and Computational Consideration
The zero-shot generate-and-encode process is conducted offline, hence it does not impact online retrieval latency. This allows preprocessing to be conducted without time constraints, accommodating even high computational loads due to large VLMs. During deployment, pruning and quantization techniques can be employed to accelerate inference, which is crucial for reducing computational costs in large-scale applications. Smaller VLMs, such as the InternVL3-2B model, offer an attractive trade-off between speed and accuracy, achieving competitive results with reduced processing demands.
Multilingual and Cross-Domain Capabilities
The method's robust performance extends across multiple languages and domains, outperforming traditional VDR models especially in multilingual and cross-lingual retrieval tasks. This suggests a significant advantage in applications requiring wide coverage across diverse document types and languages, highlighting the potential for scaling to extensive collections like those encountered in enterprise and global information systems.
Conclusion
The research highlights the efficacy of leveraging modern VLMs for zero-shot visual document retrieval. By decoupling description generation and encoding, the method capitalizes on advancements in vision-language integration, bypassing the need for specific training datasets and thereby lowering entry barriers for widespread adoption. This work sets a new baseline, encouraging further exploration into zero-shot solutions for multimodal information retrieval across varied linguistic and domain-specific contexts. Future work is suggested to focus on bridging any residual gaps in performance between supervised and zero-shot systems, particularly for non-English and low-resource languages where enhancements remain promising.