- The paper introduces IMPQ, a framework that leverages Shapley-based Progressive Quantization Estimation to capture inter-layer interactions in LLMs.
- It formulates mixed precision quantization as a binary quadratic optimization, assigning optimal 2-bit and 4-bit precisions under memory constraints.
- Evaluation on models like Llama and Qwen shows a 20–80% perplexity reduction over baselines, demonstrating improved scalability and stability.
IMPQ: Interaction-Aware Layerwise Mixed Precision Quantization for LLMs
Introduction
LLMs present immense capabilities across NLP tasks, yet their scale imposes prohibitive memory and computational requirements, impeding deployment on resource-constrained environments. Existing mixed-precision quantization strategies falter at lower bit precisions due to reliance on isolated metrics that overlook inter-layer interactions. This paper introduces Interaction-aware Mixed-Precision Quantization (IMPQ), a framework that innovatively integrates Shapley-based Progressive Quantization Estimation (SPQE) to accurately estimate layer sensitivities and interactions, translating these insights into globally optimal precision assignments using a quadratic optimization approach.
Method
The research proposes a reimagining of mixed-precision quantization as a cooperative game among layers, utilizing Shapley value analysis to model layer interactions. SPQE offers a novel method to accurately quantify contributions through progressive quantization, maintaining model stability and low variance in Shapley estimates. Built on these estimates, IMPQ formulates precision assignment as a binary quadratic optimization problem, assigning 2 or 4-bit precision under stringent memory constraints. This approach ensures optimal resource allocation, significantly enhancing performance over traditional layer-isolated metrics.
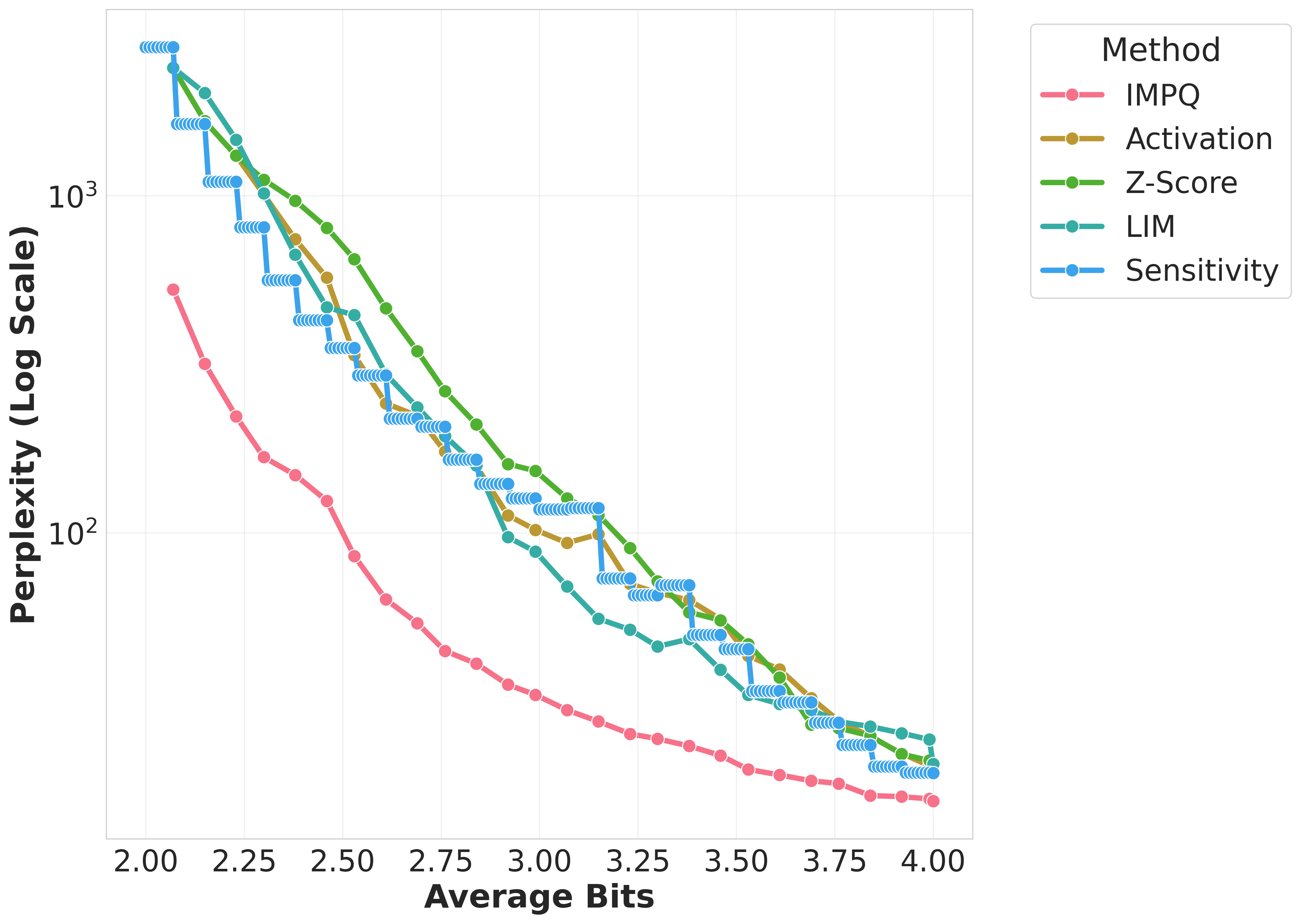
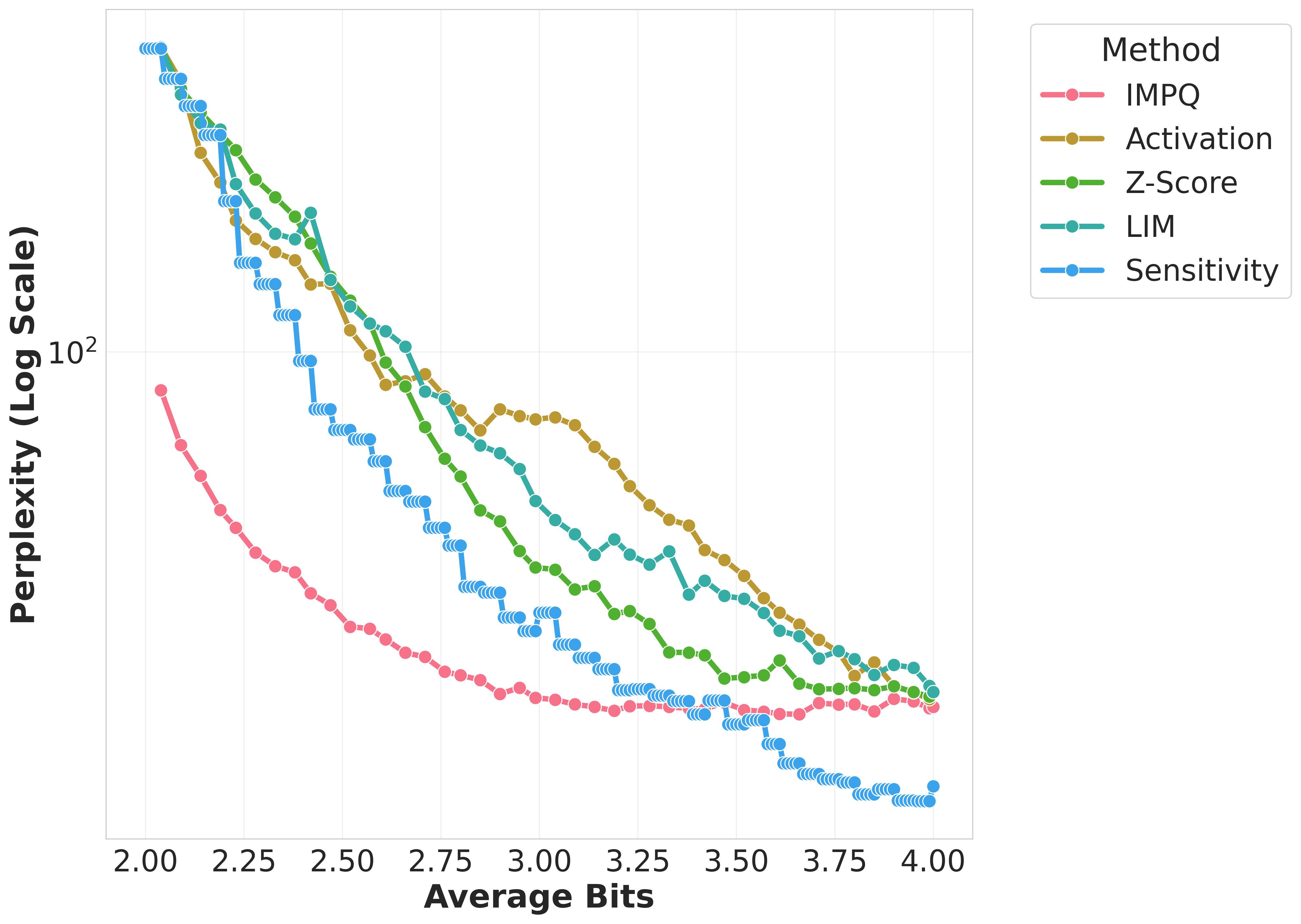
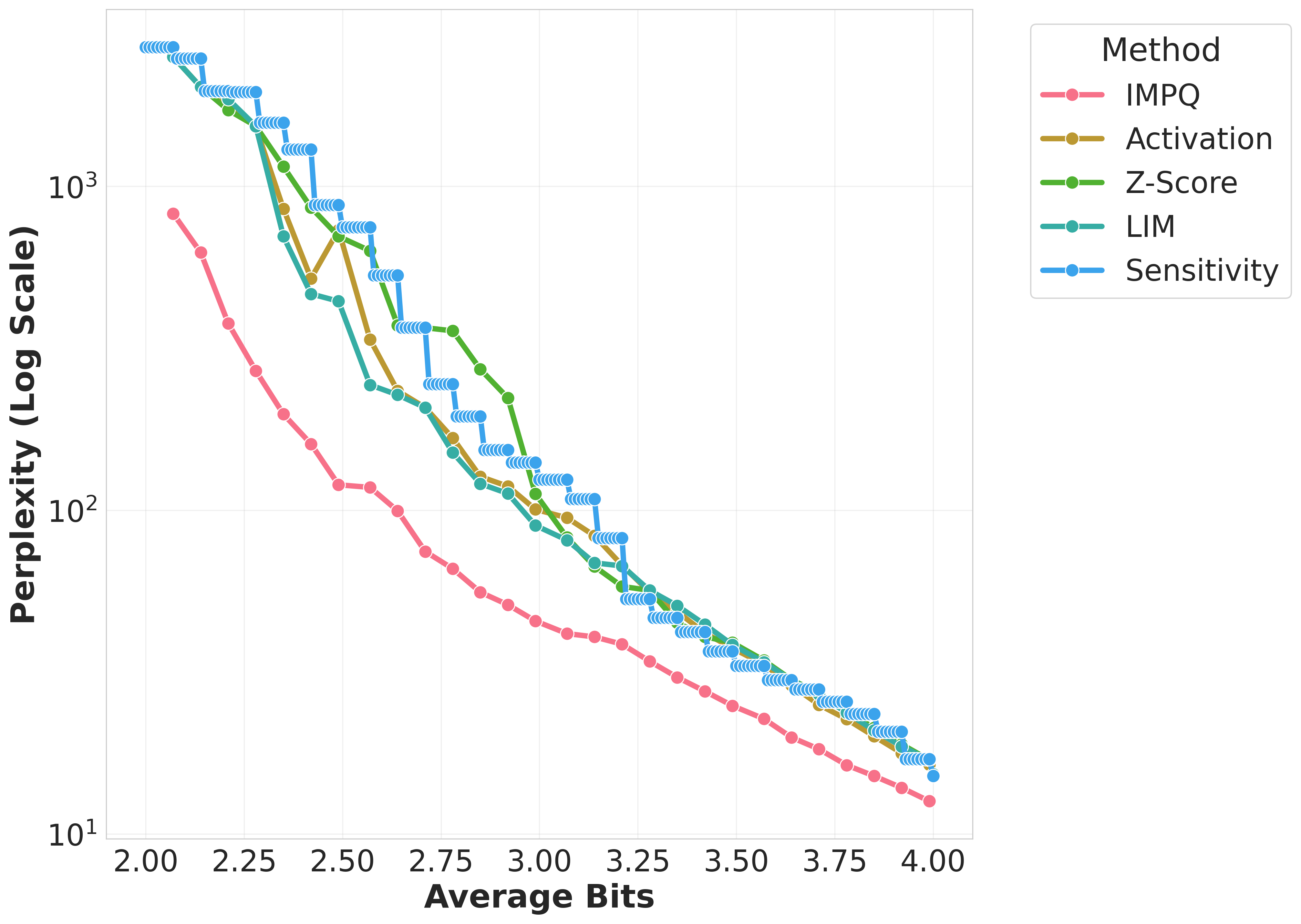
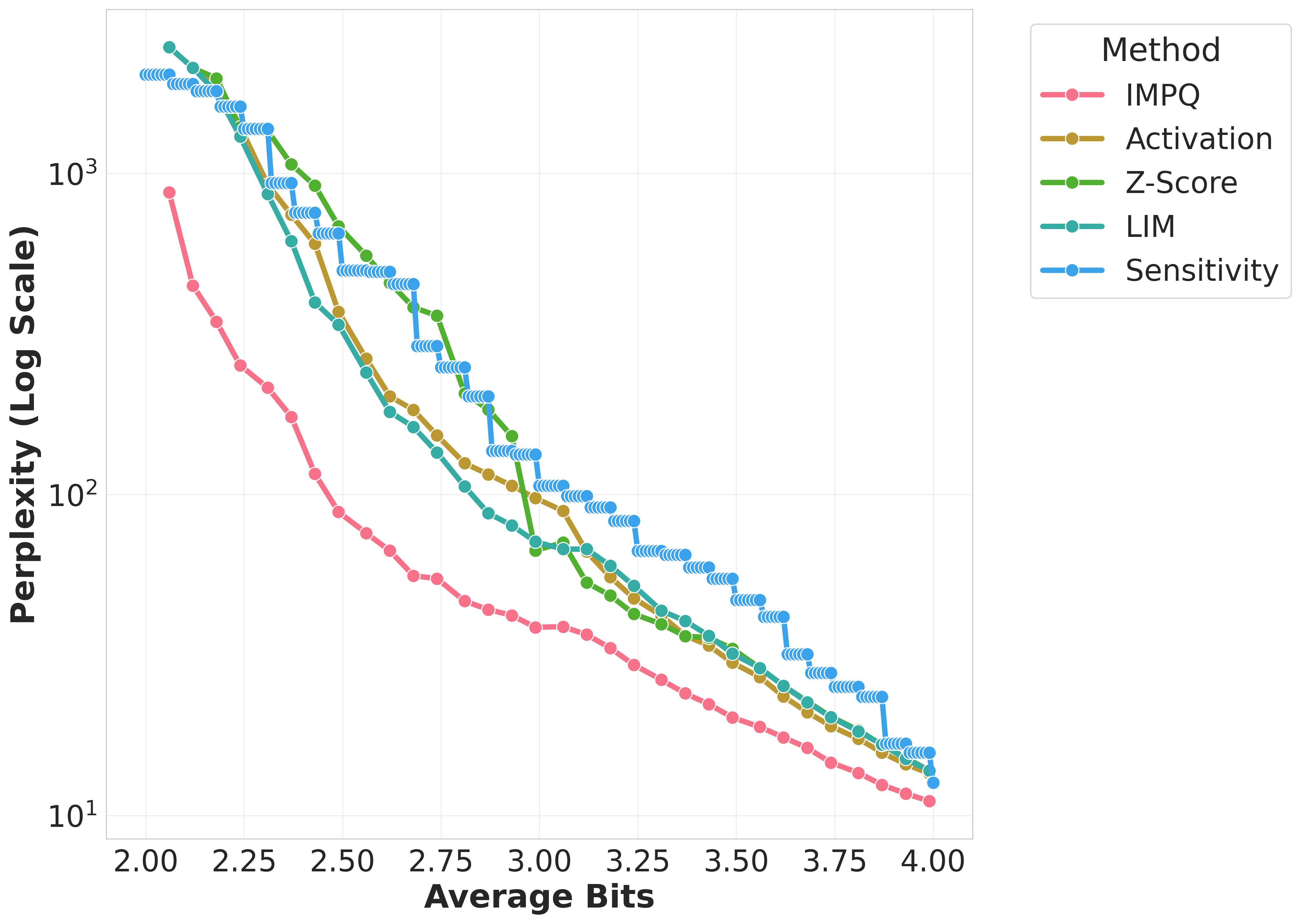
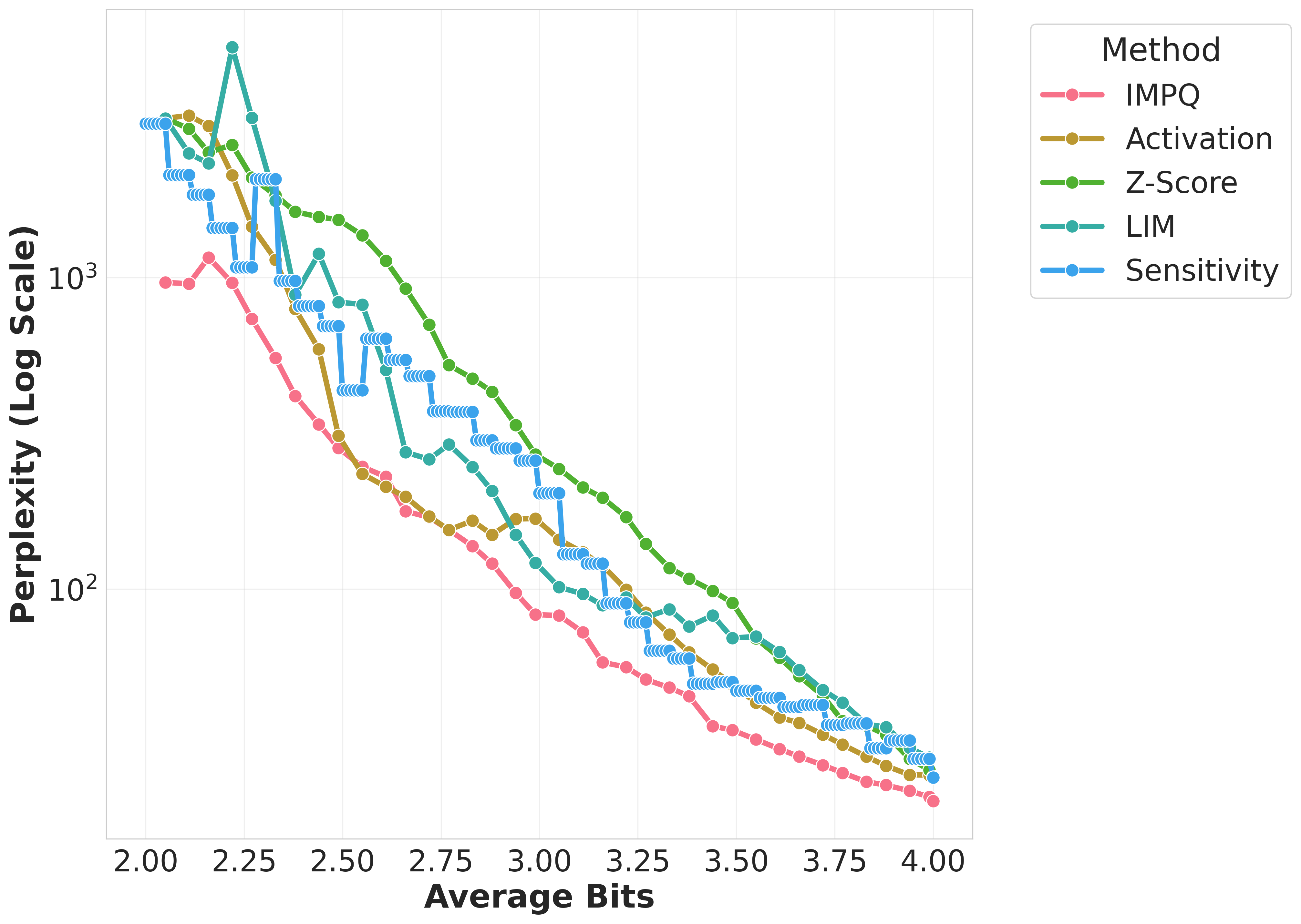
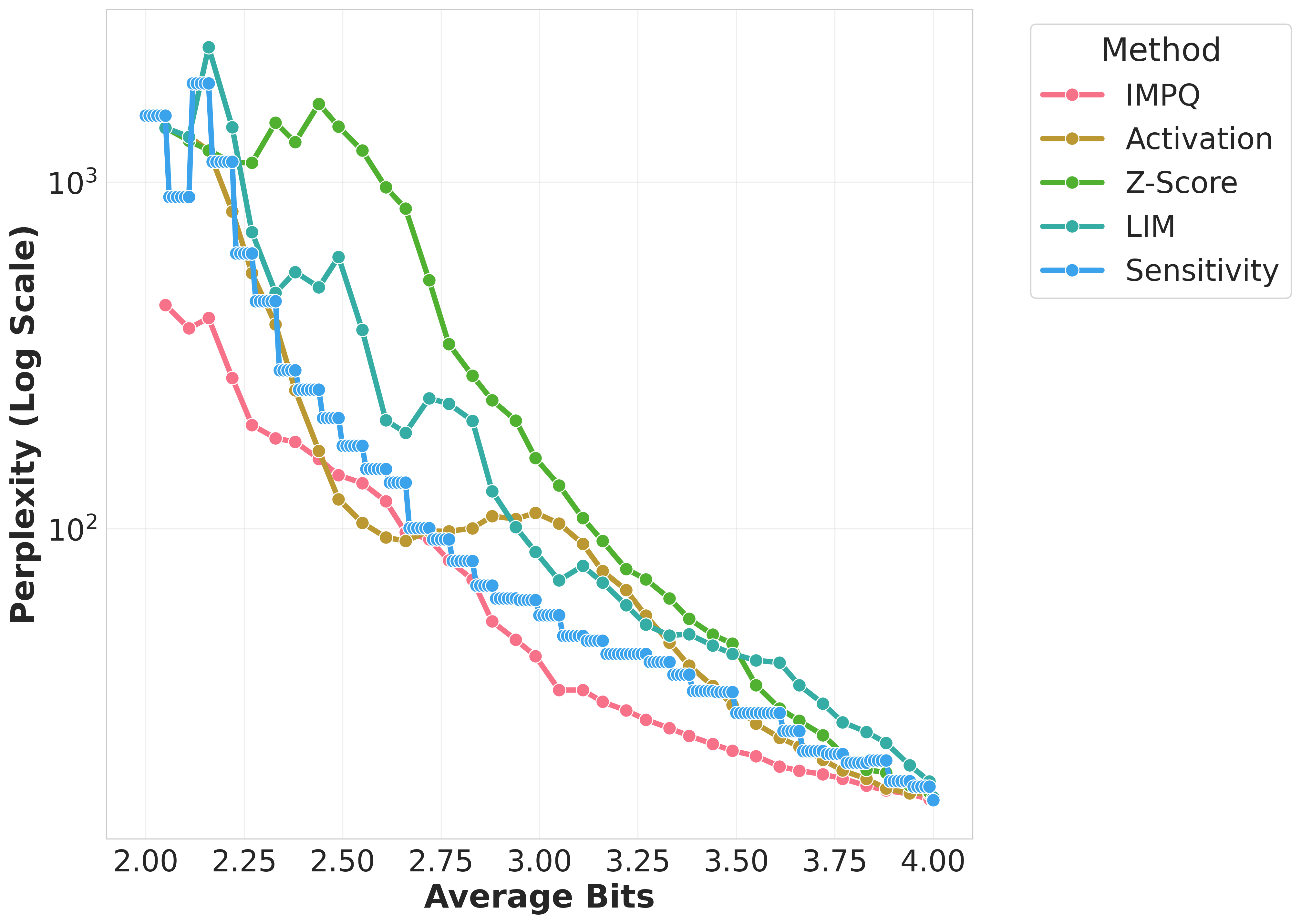
Figure 1: Wikitext-2 Perplexity comparison of quantization methods across Gemma, Llama, Qwen models on GPTQ.
Results
The evaluation across models such as Llama-3, Gemma-2, and Qwen-3 demonstrated IMPQ's consistent superiority. It achieves remarkable reductions in Perplexity by 20-80% relative to the best baselines within constrained bit-widths, illustrating the critical role of interaction-aware strategies in mixed-precision quantization. IMPQ not only outperforms isolated metric approaches but also showcases enhanced scalability and robustness under tighter precision constraints.
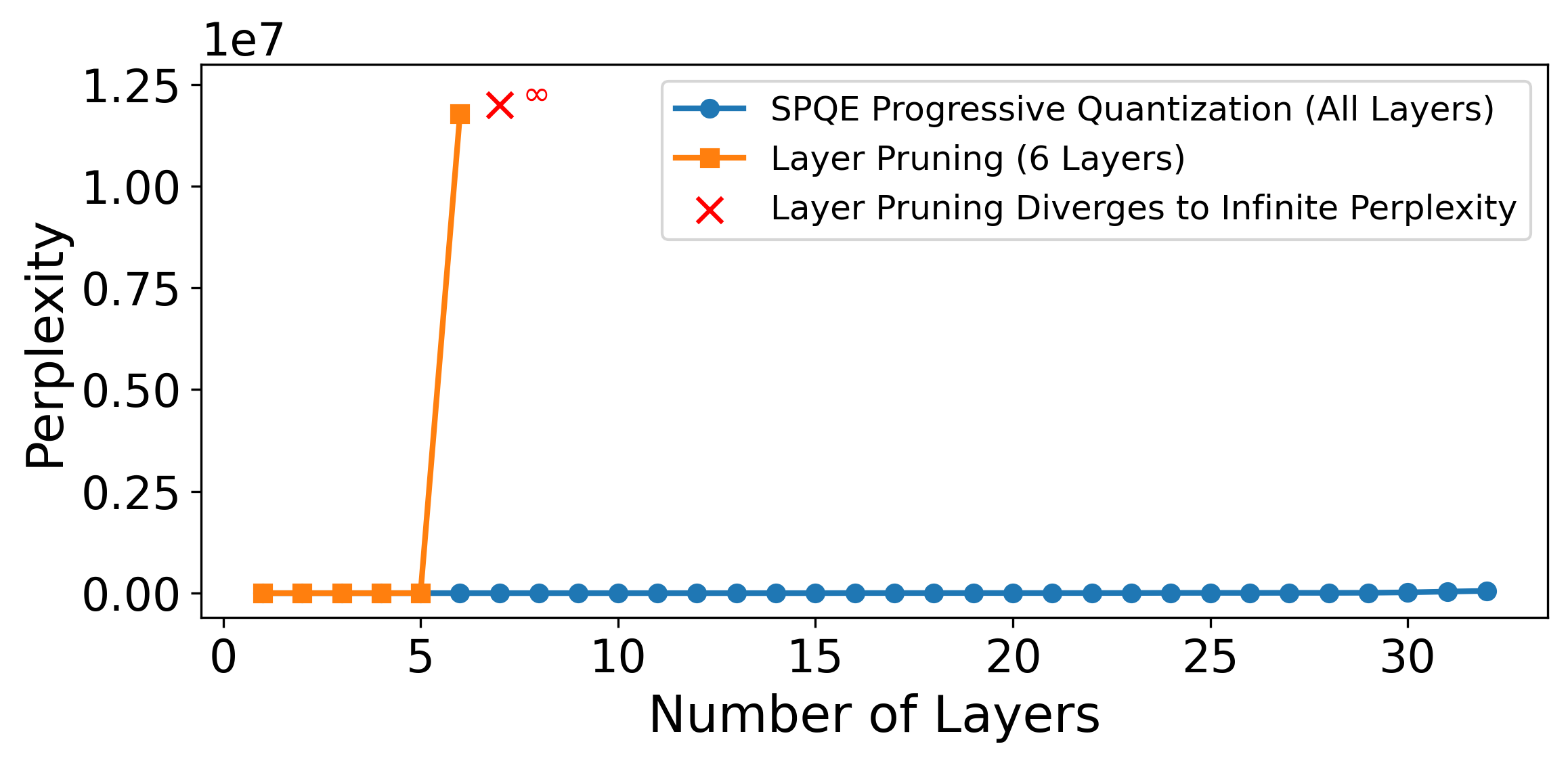
Figure 2: Comparison of perplexity for SPQE and layer pruning-based Shapley estimation on Llama 3.1-8B using Quanto. Layer pruning causes perplexity to diverge after 5 layers, while progressive quantization remains stable.
Discussion
IMPQ marks a pivotal shift from isolated layer assessment to viewing the quantization problem as sustaining inter-layer cooperation through Shapley values. This acknowledges and leverages the propagated errors across layers, optimizing precision assignment far beyond existing heuristics. Despite the computational costs associated with SPQE, these are mitigated by its one-time application that fundamentally enhances subsequent deployments.
Conclusion
IMPQ, through its novel Shapley-based quantization strategy, significantly advances low-bit quantization efficacy by accommodating inter-layer interactions. It sets a new benchmark for deploying LLMs on limited-resource platforms while paving the way for extending cooperative game-theoretic methods to other model compression techniques, ensuring comprehensive evaluation and minimizing losses through informed precision assignments.
