Overhearing LLM Agents: A Survey, Taxonomy, and Roadmap
Abstract: Imagine AI assistants that enhance conversations without interrupting them: quietly providing relevant information during a medical consultation, seamlessly preparing materials as teachers discuss lesson plans, or unobtrusively scheduling meetings as colleagues debate calendars. While modern conversational LLM agents directly assist human users with tasks through a chat interface, we study this alternative paradigm for interacting with LLM agents, which we call "overhearing agents." Rather than demanding the user's attention, overhearing agents continuously monitor ambient activity and intervene only when they can provide contextual assistance. In this paper, we present the first analysis of overhearing LLM agents as a distinct paradigm in human-AI interaction and establish a taxonomy of overhearing agent interactions and tasks grounded in a survey of works on prior LLM-powered agents and exploratory HCI studies. Based on this taxonomy, we create a list of best practices for researchers and developers building overhearing agent systems. Finally, we outline the remaining research gaps and reveal opportunities for future research in the overhearing paradigm.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “Overhearing LLM Agents: A Survey, Taxonomy, and Roadmap”
1. What is this paper about?
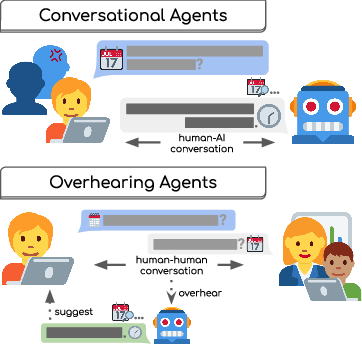
This paper is about a new kind of AI helper called an “overhearing agent.” Instead of acting like a chatbot you talk to directly, an overhearing agent quietly “listens” to what’s going on around you—like a class discussion, a meeting, or a family conversation—and helps in the background. It only steps in when it can offer something useful, like pulling up a diagram during a science lesson, suggesting a good meeting time, or showing a doctor relevant research while they talk to a patient.
2. What questions did the authors ask?
The authors wanted to understand and organize this new idea by asking:
- What makes overhearing agents different from regular chatbots?
- What kinds of situations and devices can they work with (like audio, text, video, phones, or smart glasses)?
- How should these agents decide when to help, what to do, and how to show their suggestions?
- What are the best design practices to make them helpful, safe, and respectful of privacy?
- What big research problems still need to be solved?
3. How did they study it? (Methods and approach)
The authors did a survey, which means they read many past studies and systems related to AI assistants, proactive tools, and human-computer interaction. From these examples, they built a taxonomy—a simple map of categories—to describe how overhearing agents work.
To make the technical terms clear:
- LLM: A powerful AI that understands and generates language (and sometimes audio or video).
- Agent: An AI system that can use tools (like searching the web or checking your calendar) to help with tasks.
- Overhearing: The agent isn’t talking with you; it’s observing your ongoing activity and helping quietly.
- Modality: The type of input it uses—audio (sound), text (writing), or video.
- Taxonomy: A set of categories that help organize ideas.
- Read-only vs. read-write: Whether the agent just looks up info (read-only) or also changes things (read-write), like adding a calendar event.
- Real-time vs. asynchronous: Whether help must happen right away (real-time) or can be delivered later (asynchronous).
4. What did they find, and why does it matter?
The paper organizes overhearing agents into clear dimensions. This helps designers and researchers build better systems and compare ideas consistently. Here are the main dimensions they propose:
- When the agent activates:
- Always active: Always listening to help quickly, but risk of too many suggestions and privacy concerns.
- User-initiated: You tap a button or start it when you want help.
- Post-hoc: You upload a recording later for analysis and summaries.
- Rule-based: It turns on in certain places or situations (like during scheduled meetings).
- What input it listens to:
- Audio (speech and sounds).
- Text (documents, chats, or code).
- Video (actions, environment, body language).
- How it reaches you (interfaces):
- Web/desktop apps and overlays.
- Wearables (smartwatches, earbuds, AR glasses).
- Smart home devices (like voice assistants).
- What kind of actions it takes (system design):
- State (read-only vs. read-write): Does it just fetch info or also change things?
- Timeliness (real-time vs. asynchronous): Does it help immediately or later?
- Interactivity (foreground vs. background): Does it show you suggestions, or quietly gather info to think better next time?
They also give best practices for design. In short: suggestions should be short and easy to check at a glance, simple to dismiss, reversible if they change something, editable if they create content, and managed in a queue so time-sensitive help comes first.
They highlight important privacy and safety steps too, like redacting personal details, encrypting data, offering on-device processing (so data doesn’t leave your device), and clear consent for recording—especially in group settings.
Finally, they list five big challenges that need more research:
- Knowing the right moment to help during a continuous conversation.
- Measuring how helpful the agent really is without distracting people.
- Handling real-time audio/video efficiently so it stays fast and affordable.
- Building developer tools that make audio/video and mobile support easy.
- Handling consent when multiple people are involved and not everyone wants to be recorded.
Why it matters: Today’s AI tools mostly act like chatbots that need your attention. Overhearing agents flip that idea—they help without interrupting, which could make AI feel more natural and useful in schools, workplaces, and homes.
5. What could this change in the future? (Implications and impact)
If built well, overhearing agents could:
- Support teachers by showing the right visuals at the right time.
- Make meetings smoother by preparing notes, action items, and schedules.
- Help doctors by surfacing relevant info during patient visits.
- Assist families with plans and reminders without anyone stopping to “ask the AI.”
But this only works if systems are respectful and safe—meaning strong privacy protections, clear consent, and controls that let people easily accept, edit, or undo suggestions. The paper gives researchers and builders a roadmap to make these agents practical, trustworthy, and truly helpful—so AI fits into our lives without getting in the way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues the paper leaves open for future research and development.
- Lack of standardized benchmarks: No publicly defined datasets or tasks for overhearing agents that include multimodal (audio/video/text) streams, speaker diarization, labeled intervention points, suggestion relevance, timeliness requirements, and multi-party consent annotations.
- Evaluation metrics remain undefined: No agreed-upon measures for utility vs interruption (e.g., precision/recall of helpful interventions, cognitive load, suggestion fatigue, latency, reversibility rate, trust calibration, acceptance/override rates).
- Absence of real-world deployment studies: No longitudinal, in-the-wild trials across varied domains (e.g., classrooms, clinics, workplaces, households) to quantify outcomes, user satisfaction, and behavioral impacts over time.
- Unexplored trade-offs between initiative modes and user burden: No empirical comparison of always-active, user-initiated, rule-based, and post-hoc modes on suggestion fatigue, missed opportunities, recall/precision, and perceived autonomy/control.
- Limited guidance on relevance filtering: No concrete algorithms, thresholds, or learning objectives to suppress spurious suggestions while maintaining recall in continuous, noisy input streams.
- Missing models for intervention timing: No validated methods to detect optimal intervention moments from multimodal signals (beyond high-level pointers to VAD/semantic turn-taking), including prosody, hesitation, gaze, and activity state.
- Real-time multimodal processing gaps: No solutions for variable-rate tokenization or adaptive sampling that reflect information density (silence vs rapid speech) to reduce cost while preserving responsiveness.
- Duplex agent–tool orchestration is underspecified: No designs for full-duplex processing that integrate streaming perception, concurrent tool calls, and user-facing interventions without blocking or race conditions.
- Intent inference under uncertainty: No formal frameworks to infer user intent without direct prompting, including priors, uncertainty quantification, confidence-calibrated suggestions, or Bayesian/causal models.
- ASR and diarization robustness: No assessment of how transcription/diarization errors propagate to downstream intent detection and intervention quality, nor mitigation strategies (confidence thresholds, fallback behaviors).
- Multilingual and code-switching support: No exploration of overhearing in non-English, multilingual, or code-switching settings, including domain-specific jargon and accents.
- Accessibility and inclusivity: No analysis of performance or UX for users with speech impairments, non-verbal communication styles, or varied cultural norms around interruption and consent.
- Privacy threat modeling is incomplete: No formal, end-to-end threat models covering data capture, on-device/cloud processing, memory storage, tool calls, logs, and audit trails; limited discussion of attack surfaces (model inversion, prompt injection via ambient inputs).
- Consent in multi-party settings: No concrete protocols or UI patterns for dynamic consent negotiation, selective processing (per-speaker opt-out), or on-device redaction when bystanders are present.
- Legal and regulatory compliance: No mapping to HIPAA/GDPR/CCPA or sector-specific rules (education, healthcare, corporate) covering data retention, discovery risk, and cross-jurisdictional constraints.
- PII detection and redaction efficacy: No evaluation of redaction tools (e.g., Presidio) on conversational, noisy audio/video and multimodal contexts; no guidance on false positives/negatives and their UX impact.
- On-device vs cloud trade-offs: No quantification of latency, battery, bandwidth, and cost for on-device small models vs cloud LLMs, including hybrid/offloading strategies and failover modes.
- Interface-level queueing and prioritization: No concrete algorithms to triage suggestions by time sensitivity, confidence, user context, and interruption cost; no policies for auto-expiration and pinning.
- Reversibility and auditability mechanisms: No validated designs to guarantee easy undo/rollback for stateful actions (calendar edits, device controls) with full provenance logging and user trust cues.
- Tooling ecosystem gaps: No open-source, LLM-agnostic libraries that provide native audio/video I/O, mobile/wearable integrations (notifications, haptics), async-first patterns, and composable tool registries with dynamic loading.
- Safety for high-stakes contexts: No risk management frameworks for medical, emergency, or industrial settings, including escalation logic, human-in-the-loop safeguards, and liability boundaries.
- Domain generalization: No analysis of how overhearing agents transfer across domains (education→healthcare→workplaces) and what domain adaptation or prompt/tool specialization is required.
- Data governance and retention: No policies for storage duration, minimization, differential privacy, federated learning, or user-controlled deletion in long-running overhearing systems.
- Socio-behavioral impacts: No study of how passive AI assistance changes group dynamics, power relations, speaking patterns, or reliance on automation in multi-party conversations.
- Hallucination mitigation: No strategy for verifiable suggestions (grounded retrieval, citation, UI affordances for quick validation) and calibration to avoid overconfident, incorrect interventions.
- Cost-aware design: No modeling of the economic cost (tokens, compute, network) of continuous overhearing and strategies for budget-aware throttling, batching, and selective processing.
- Benchmarking timeliness: No tests that penalize late suggestions or reward just-in-time interventions, nor latency budgets tied to task criticality (real-time vs asynchronous categories).
- Integration with wearables and smart home devices: No practical guidance on sensor fusion, battery management, connectivity disruptions, and privacy-preserving local processing on constrained hardware.
- Memory management: No principled approach to what overheard content should be written to long-term memory, how it is indexed, and when it should be pruned to minimize privacy risk and cognitive bias.
- Transparency and user agency: No standardized feedback channels for users to correct agent assumptions, tune proactiveness levels, and set granular boundaries on what the agent can overhear or act upon.
Practical Applications
Immediate Applications
Below are concrete uses that can be deployed today by leveraging current LLMs, ASR/diarization, retrieval, and app integrations, aligned with the survey’s taxonomy and best practices.
- Meeting copilots and post-hoc minutes — Enterprise software
- Practical: Live capture of action items, decisions, risks, and follow-ups; post-hoc summaries and task drafts sent to participants.
- Tools/workflows: Streaming ASR + diarization; action-item extraction; calendar/task manager integration (ICS, Jira, Asana); suggestion queue in a sidebar; reversible state changes.
- Assumptions/dependencies: Participant consent; privacy and PII redaction (e.g., Presidio); integration with conferencing platforms; accuracy thresholds and suggestion fatigue controls.
- Real-time scheduling drafts during meetings — Enterprise/operations
- Practical: Detect consensus on time/place and draft calendar invites; surface conflicts; prepare tentative room bookings.
- Tools/workflows: Conversational intent detection; calendar availability APIs; draft-inbox for approvals.
- Assumptions/dependencies: Read-write access to calendars; reversible actions; explicit user confirmation; time-zone handling.
- Agent assist for sales and customer support — Contact centers
- Practical: Overhear live calls/chats to suggest compliant responses, retrieve KB snippets, and fill CRM fields.
- Tools/workflows: Streaming text/audio ingestion; RAG over playbooks/KB; CRM integration; latency-optimized prompts.
- Assumptions/dependencies: Sub-200 ms round-trip guidance; compliance logging/auditing; model grounding to reduce hallucinations.
- Coding copilots as “single-user overhearing” — Software engineering
- Practical: Detect new functions/tests, propose unit tests, missing imports, docstrings, and refactors while user edits code.
- Tools/workflows: IDE plugins; AST diff analysis; repository indexing; background doc lookup; reversible edits (staging changes).
- Assumptions/dependencies: Local indexer; support for large repos; developer override and explainability.
- Research and literature surfacing while writing or discussing — Academia/R&D
- Practical: As users draft or debate ideas, queue relevant papers, citations, datasets, and prior art for later review.
- Tools/workflows: Semantic Scholar/Google Scholar APIs; PDF parsing; citation managers; asynchronous “deep research” job queue.
- Assumptions/dependencies: Access to scholarly APIs; deduplication; bias/coverage monitoring; clear provenance display.
- Classroom support for instructors — Education
- Practical: During lectures, suggest diagrams/definitions/examples to display; queue clarifications when confusion is detected.
- Tools/workflows: Lecture audio ASR; retrieval from slide libraries/OERs; smartboard/slide control; instructor approval panel.
- Assumptions/dependencies: School privacy policy; student consent; minimal latency; ability to “pin” or dismiss suggestions.
- Smart home “rule-activated” helpers — Consumer/IoT
- Practical: When a cooking app is open or a kitchen device is active, surface next recipe step, set timers, and list substitutes.
- Tools/workflows: Device state triggers; recipe parsers; voice/ambient display; reversible timers and reminders.
- Assumptions/dependencies: Vendor integrations; wake-word activation; clear opt-in; offline fallback where possible.
- Wearable micro-prompts during live coordination — Daily life/consumer
- Practical: Smartwatch/earbud nudges during scheduling (“you are free Fri 3–5pm”), location-based ETA suggestions, or quick task capture.
- Tools/workflows: Calendar peek; haptic notifications; on-device summarization snippets; suggestion queue with snooze.
- Assumptions/dependencies: Battery and bandwidth; on-device speech snippets; safety-first notification rate limiting.
- Accessibility overlays for meetings — Accessibility/education
- Practical: Live captions and translation on AR glasses; term definitions on tap; contextual glossary for technical talks.
- Tools/workflows: On-device/edge ASR + MT; domain glossary injection; AR HUD overlays.
- Assumptions/dependencies: AR hardware; low-latency streaming; privacy signage for bystanders.
- Family planning and shopping capture — Daily life
- Practical: When consensus forms at dinner on an outing, queue weather/trails; detect “we’re out of milk” and draft a grocery list.
- Tools/workflows: Voice note detection; list app integration; weather/trail APIs; later review in mobile app.
- Assumptions/dependencies: Household consent; opt-in rooms; suppression of private or sensitive content.
- Game master companion — Media/entertainment
- Practical: During tabletop RPGs, trigger music/soundscape, fetch monster stats, and display maps on cue.
- Tools/workflows: Phrase spotting; content library linking; scene lighting integrations; GM-controlled overlay.
- Assumptions/dependencies: Licensed content access; GM override; latency tolerance for “dramatic beats.”
- Post-hoc compliance summaries — Finance/healthcare/legal
- Practical: Redacted meeting/call summaries with policy flags (e.g., Reg BI, HIPAA topics) routed to review workflows.
- Tools/workflows: PII redaction; policy-aware classifiers; mutable audit trails; retention controls.
- Assumptions/dependencies: Regulatory approvals; strict access control; legal sign-off on automated flagging.
- Proactive desktop sidebar — Knowledge workers
- Practical: Contextual document links as users browse/email; auto-collect reference snippets for later writing.
- Tools/workflows: Browser extension; enterprise search; background RAG; pinned reading queue.
- Assumptions/dependencies: Data governance; SSO/permissions; local cache for privacy and speed.
Long-Term Applications
These require additional research, scaling, standards, or regulatory clearance, particularly around real-time multimodal processing, consent, safety, and on-device privacy.
- Clinical consultation copilot integrated with EHR — Healthcare
- Practical: Overhear patient–physician dialog, surface differential diagnoses, guideline snippets, drug–drug interactions; draft orders/notes.
- Tools/workflows: Medical ASR; EHR APIs; medical RAG with citations; clinician-controlled suggestion queue; reversible orders.
- Assumptions/dependencies: FDA/CE approvals; rigorous clinical evaluation; PHI-safe on-prem deployment; medico-legal liability frameworks.
- Always-on ambient home/office assistant with selective processing — Consumer/enterprise
- Practical: Continuous multimodal sensing with “semantic VAD” to spot actionable moments; aggressive on-device redaction and ephemeral buffers.
- Tools/workflows: Variable-rate tokenization; consent-negotiation module; configurable retention; “least data necessary” pipelines.
- Assumptions/dependencies: Robust consent UX for multi-party spaces; on-device multimodal LLMs; energy-efficient hardware.
- Classroom orchestration at scale — Education
- Practical: Track group work, identify misconceptions, form adaptive groups, and stage materials per group without teacher prompt.
- Tools/workflows: Multimodal student-activity detection; content routing; dashboard for teacher approvals; fairness and bias audits.
- Assumptions/dependencies: Student privacy (FERPA/GDPR); equity safeguards; robust evaluation of learning impact.
- Industrial field service AR helper — Manufacturing/energy/utilities
- Practical: When a technician hesitates or mentions an error code, overlay step-by-step procedures, parts availability, and safety checks.
- Tools/workflows: AR glasses; equipment telemetry integration; knowledge graph of procedures; offline edge inference.
- Assumptions/dependencies: Ruggedized devices; union and safety compliance; model certification for safety-critical prompts.
- Emergency and elder-care detection — Health/assistive tech
- Practical: Detect distress/falls from multimodal cues and escalate to caregivers, with false-alarm management and consent-aware processing.
- Tools/workflows: Privacy-preserving audio/video features; graded alerting; escalation trees; caregiver coordination app.
- Assumptions/dependencies: High precision/recall requirements; liability and insurance frameworks; secure home hubs.
- Legal and governance copilot for proceedings — Legal/policy
- Practical: During board meetings or depositions, surface precedent and policy constraints; mark privilege boundaries; generate privilege logs.
- Tools/workflows: Jurisdiction-aware legal RAG; eDiscovery hooks; privilege-safe storage; counsel approval gates.
- Assumptions/dependencies: Bar ethics guidance; confidentiality controls; defensible audit trails.
- Proactive research agents that self-orchestrate deep dives — Academia/R&D
- Practical: After overhearing a question, launch a multi-agent deep research process to compile lit reviews, benchmarks, and open problems.
- Tools/workflows: Autonomous research pipelines; dataset/tool inventories; reproducible notebooks; long-term memory stores.
- Assumptions/dependencies: Source provenance; bias/coverage diagnostics; compute budgets and scheduler.
- Consent negotiation and selective processing standards — Policy/standards
- Practical: System-level protocols for per-person opt-in/out with automatic exclusion of non-consenting participants from processing.
- Tools/workflows: Device-to-device consent beacons; selective diarization redaction; standardized icons/signage; verifiable compliance logs.
- Assumptions/dependencies: Industry standards bodies; OS-level primitives; regulator-backed certification.
- Financial trading/compliance coach — Finance
- Practical: Overhear desk chatter to flag market manipulation risks and surface internal policies in context; draft compliant comms.
- Tools/workflows: Real-time classifiers; policy RAG; secure archiving; workflow for compliance officer review.
- Assumptions/dependencies: Very low false positives; surveillance policies; strict segregation from trading decision logic.
- Multimodal personal memory and life-logging — Consumer/wellness
- Practical: Curate a searchable, redacted personal chronicle; auto-tag milestones; prepare periodic digests and to-dos.
- Tools/workflows: Background world-model updates; vector memories; redaction pipelines; user controls for retention and sharing.
- Assumptions/dependencies: Strong privacy defaults; export/forget APIs; on-device summarization.
- Smart-city and workplace ambient note systems — Public sector/enterprise
- Practical: In designated rooms, auto-capture minutes with policy-aligned retention, translated accessibility overlays, and open-data export where permitted.
- Tools/workflows: Room-level consent signage; role-based access; policy templates for retention; FOIA-aware redaction.
- Assumptions/dependencies: Municipal policy alignment; procurement and security certification; community engagement.
- Coaching for communication and soft skills — Education/HR
- Practical: Private “whisper coach” during presentations: pace, filler words, sentiment shifts, inclusive language nudges.
- Tools/workflows: Prosody analysis; real-time wearable feedback; post-hoc coaching plans and practice prompts.
- Assumptions/dependencies: Strong user privacy; opt-in only; bias-aware language feedback; on-device computation.
- Robotics-adjacent operator support — Robotics/warehousing
- Practical: Overhear operator–robot interactions, surface safety SOPs or parameter tweaks when confusion or errors arise.
- Tools/workflows: Multimodal event detection; robot telemetry; SOP RAG; operator tablet overlays.
- Assumptions/dependencies: Tight integration with robot controllers; safety certifications; network reliability on the floor.
Cross-cutting tools and workflows likely to emerge
- Overhearing SDKs: Modular tool interfaces (LLM-agnostic), async-first APIs, audio/video I/O, semantic VAD/diarization, suggestion-queue primitives, reversible action scaffolds.
- Privacy and compliance toolchains: On-device inference switches, redaction pipelines, at-rest encryption, retention policies, verifiable consent logs.
- Evaluation suites: Helpfulness vs interruption metrics, user-accept/reject analytics, latency/error budgets, domain-specific gold standards.
- Multimodal efficiency primitives: Variable-rate tokenization, adaptive buffering, edge/cloud scheduling, full-duplex processing.
Common assumptions and dependencies impacting feasibility
- Accurate, low-latency ASR/diarization and robust intent detection across accents, domains, and noise.
- Strong consent and privacy mechanisms, including selective processing for multi-party conversations.
- Reliable integrations with calendars, EHR/EMR, CRMs, task managers, AR devices, and enterprise identity/permissions.
- Reversible, auditable state changes; human-in-the-loop approvals for read-write actions.
- On-device or on-prem deployment options for sensitive domains; clear cost and energy budgets for continuous processing.
- Mitigation of hallucinations via grounding/RAG, provenance display, and conservative suggestion thresholds to reduce suggestion fatigue.
Glossary
- Agentic systems: LLM-driven systems that can use tools and act autonomously toward goals. "With the ability to use tools and interact with the wider world, a popular topic in current work is LLM-powered ``agentic'' systems."
- Asynchronous-first design: A software design approach that natively supports non-blocking, delayed, or concurrent tasks. "Finally, tool interfaces should be built with an asynchronous-first design, allowing for both real-time and asynchronous tasks to be implemented using native Python programming models."
- At-rest encryption: Encrypting stored data on a device or server to protect it from unauthorized access. "and any locally-recorded data should be at-rest encrypted."
- Context window: The span of tokens or content an LLM can attend to in a single pass. "that is not in its context window"
- DocPrompting: A technique or system for retrieving and prompting over document contexts to aid LLMs. "DocPrompting \cite{zhou_docprompting_2023}"
- Full-duplex system: A system that can process input and generate output simultaneously and continuously. "future work could investigate how to integrate agentic tool calling with a full-duplex system."
- Haptics: Tactile feedback mechanisms (e.g., vibrations) used to communicate information to users. "integration with mobile devices and their device-specific affordances (e.g., mobile notifications and haptics), and asynchronous programming."
- Hierarchical multi-agent setup: An arrangement where multiple agents are organized in tiers to coordinate complex tasks. "use a hierarchical multi-agent setup to aggregate a large number of sources to return an answer to a user's query."
- Human-Computer Interaction (HCI): The study and design of interactive technologies focused on human use and experience. "exploratory HCI studies."
- LLM: A neural model trained on vast text corpora to perform language understanding and generation tasks. "There has been a recent uptick in the popularity of LLM-powered AI agents: semi-autonomous systems that use multiple rounds of tool calling to answer complex queries or complete tasks delegated by a human user."
- Life-logging: Continuous or frequent recording of life activities and data for later review or analysis. "Other ``life-logging'' products like Bee"
- LLM-agnostic: Designed to work with any LLM without depending on a specific provider or architecture. "Tool interfaces should be LLM-agnostic, allowing a single set of tools to be reused regardless of the underlying model."
- Model Context Protocol (MCP): A protocol for standardizing tool and context integrations with AI models. "and the Model Context Protocol\footnote{\url{https://modelcontextprotocol.io/} (MCP) present first steps towards these goals."
- Multimodal LLMs: Models that process and reason over multiple input types (e.g., text, audio, video). "there have been few multimodal LLMs capable of processing audio input directly"
- On-device processing: Running AI processing locally on a user’s device instead of sending data to external servers. "Users should have the option for on-device processing with small LLMs rather than API-hosted LLMs."
- PII (Personally Identifiable Information): Data that can identify a specific individual (e.g., names, emails). "may contain PII or other private information."
- Post-hoc systems: Systems that analyze conversations or data after completion rather than in real time. "Post-hoc systems process conversations after they conclude rather than in real-time."
- Prefill: The initial forward pass of tokens into a Transformer before generation, affecting latency. "While optimizing the Transformer model to reduce prefill and generation time is widely researched"
- Prosodic features: Non-linguistic aspects of speech (e.g., intonation, rhythm, pauses) that convey cues like uncertainty. "These include prosodic features like pauses, hesitations, or changes in tone that might indicate confusion or uncertainty."
- Read-write (stateful) tasks: Tasks that modify and depend on persistent state in the user’s environment. "In contrast, read-write or stateful tasks require an AI agent to be aware of a long-term state and how its actions will affect that state (a ``world model''; \citealp{hao_reasoning_2023})."
- Semantic VAD (Voice Activity Detection): Models that segment continuous audio based on meaning-informed speech activity. "explicit segmentation of the continuous input into discrete turns using semantic VAD models"
- Speaker diarization: The process of separating an audio stream by speaker identity over time. "Audio agents may implicitly diarize speech to distinguish between participants"
- Throughput: The rate at which a system can process input and produce output, often critical for real-time performance. "How can we optimize multimodal throughput for real-time processing?"
- Tool calling: An LLM’s capability to invoke external tools or APIs during reasoning to gather information or act. "LLM agents use tool calling across multiple rounds of tool use in pursuit of a user-defined goal."
- Transformer-based model: A neural architecture using self-attention to model sequences, widely used in modern LLMs. "which are processed by a Transformer-based model to predict a sequence of output tokens."
- Variable rate tokenization: A scheme that adapts token density to the information content of the input to improve efficiency. "future work could develop a variable rate tokenization scheme that varies with the information density of a continuous input."
- World model: An internal representation of environment state and dynamics that informs an agent’s actions. "(a ``world model''; \citealp{hao_reasoning_2023})"
Collections
Sign up for free to add this paper to one or more collections.