- The paper presents SaSaSa2VA, a novel approach that enhances RVOS by augmenting segmentation inputs and scaling [SEG] tokens for richer temporal context.
- It introduces a Key Frame Compression strategy that tiles and compresses video frames, balancing global context with computational efficiency.
- Experimental results show a 67.45 J_contentF score, outperforming competitors by 2.80 points, validating the effectiveness of the proposed ensembling techniques.
SaSaSa2VA: Segmentation Augmented and Selective Averaged Sa2VA for Referring Video Object Segmentation
Introduction
The paper presents SaSaSa2VA, a solution for the 7th LSVOS Challenge (RVOS track), targeting the task of referring video object segmentation (RVOS). RVOS requires segmenting and tracking objects in videos based on natural language expressions, necessitating fine-grained spatiotemporal and linguistic understanding. The approach builds upon Sa2VA, which integrates a Multi-modal LLM (MLLM) with the video segmentation model SAM2. The authors identify two primary bottlenecks in Sa2VA: (1) sparse frame sampling, which limits global video context modeling, and (2) the use of a single [SEG] token for the entire video, which restricts temporal expressiveness. SaSaSa2VA introduces segmentation augmentation and test-time ensembling strategies to address these limitations, achieving a JcontentF score of 67.45 and outperforming the runner-up by 2.80 points in the challenge.
Methodology
Baseline: Sa2VA Architecture
Sa2VA consists of an MLLM (InternVL 2.5) and the SAM2 segmentation model. The MLLM processes images, videos, and text instructions, generating responses that may include a [SEG] token. The hidden state of this token is used as a prompt for SAM2, which produces segmentation masks for selected frames and propagates them across the video. However, Sa2VA samples only five frames per video and uses a single [SEG] token, which constrains its ability to capture temporal dynamics and global context.
Segmentation Augmentation
To overcome the limitations of sparse sampling and under-expressive prompting, SaSaSa2VA introduces two key strategies:
- Key Frame Compression (KFC): The video is divided into N non-overlapping clips, each containing c=g2+1 frames. For each clip, the first frame is retained as the key frame, while the remaining g2 frames are tiled into a g×g grid, resized, and compressed into a single image. This reduces the input to $2N$ images per video, balancing efficiency and global context retention.
- Scaling [SEG] Tokens:
Instead of a single [SEG] token, one [SEG] token is assigned per clip, allowing the MLLM to output N [SEG] tokens per video. Each token's hidden state is used by SAM2 to decode masks for its corresponding clip, enhancing temporal expressiveness and robustness to object variations.
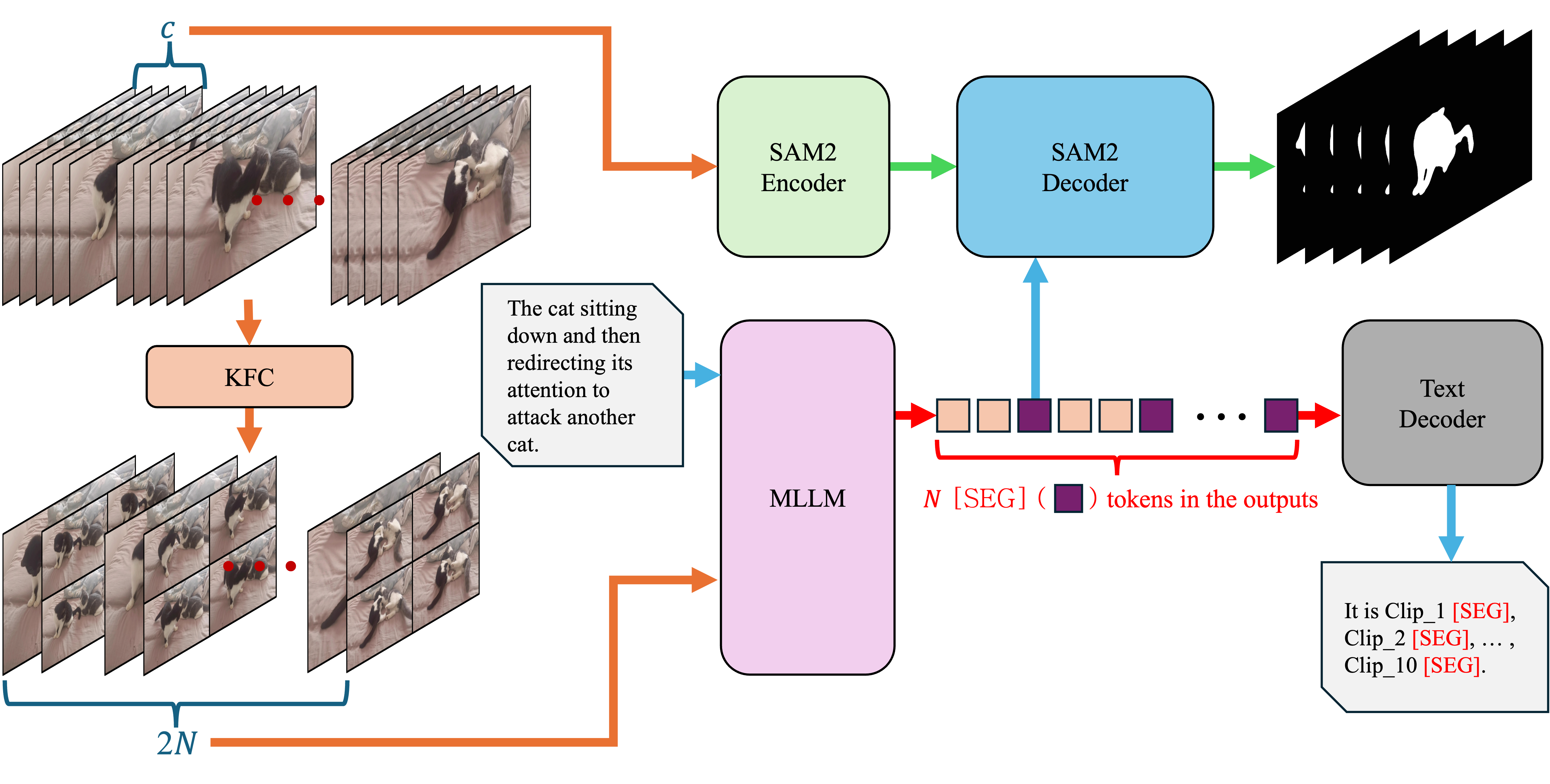
Figure 1: Overview of Segmentation Augmentation in SaSaSa2VA, illustrating the Key Frame Compression and Scaling [SEG] tokens strategies.
Test-time Augmentation and Selective Averaging
At inference, SaSaSa2VA employs five complementary frame sampling strategies to accommodate videos of varying lengths and characteristics:
- Uniform: Evenly divides the video and samples frames uniformly.
- Uniform+: Averages masks for frames with multiple [SEG] tokens.
- Q-frame: Selects frames most relevant to the text prompt.
- Wrap-around: Cyclically samples frames when the video is shorter than the target length.
- Wrap-around+: Combines wrap-around and uniform strategies based on video length.
To further enhance robustness, the Selective Averaging ensemble fuses predictions from different models and sampling strategies by weighted averaging of masks, setting pixel values based on a threshold.
Experimental Results
SaSaSa2VA was evaluated on the 7th LSVOS Challenge (RVOS track), achieving a JcontentF score of 67.45, outperforming the second-place solution by 2.80 points. The ablation studies demonstrate:
- Segmentation Augmentation yields over 10 JcontentF points improvement compared to the Sa2VA baseline.
- Selective Averaging provides an additional ~2 point gain, confirming the benefit of ensembling across models and sampling strategies.
These results establish the effectiveness of the proposed augmentation and ensembling techniques for grounded MLLMs in RVOS.
Implementation Considerations
- Model Scaling: The approach is compatible with both 14B and 26B parameter MLLMs, with larger models yielding higher performance.
- Frame Sampling: The KFC strategy reduces computational overhead while maintaining global context, making it suitable for long videos.
- Training Data: The method leverages both referring image and video segmentation datasets, including RefCOCO, RefCOCO+, RefCOCOg, MeViS, Ref-YTVOS, ReVOS, and Ref-SAV.
- Inference Efficiency: The use of multiple sampling strategies and Selective Averaging increases inference time and memory requirements, but the performance gains justify the additional cost in competitive settings.
- Generalization: The modular design allows for straightforward adaptation to other video segmentation tasks or datasets.
Implications and Future Directions
The results highlight the importance of aligning MLLM reasoning with dense video segmentation, particularly in tasks requiring fine-grained temporal and linguistic grounding. The segmentation augmentation and ensembling strategies are broadly applicable to other multi-modal video understanding tasks. Future work may explore:
- Adaptive Sampling: Learning-based or query-aware frame selection to further optimize context coverage.
- Token-efficient Prompting: Dynamic allocation of [SEG] tokens based on video complexity or object motion.
- Real-time Inference: Reducing the computational cost of ensembling for deployment in latency-sensitive applications.
- Generalization to Open-world Settings: Extending the approach to handle open-vocabulary and zero-shot referring expressions.
Conclusion
SaSaSa2VA advances the state of the art in referring video object segmentation by addressing key bottlenecks in temporal context modeling and segmentation prompting. Through segmentation augmentation and selective ensembling, the method achieves superior performance on the LSVOS RVOS benchmark. The findings underscore the value of integrating efficient video summarization and robust ensembling in grounded MLLMs, with implications for a wide range of multi-modal video understanding tasks.

