Asteria: Semantic-Aware Cross-Region Caching for Agentic LLM Tool Access
Abstract: LLM agents tackle data-intensive tasks such as deep research and code generation. However, their effectiveness depends on frequent interactions with knowledge sources across remote clouds or regions. Such interactions can create non-trivial latency and cost bottlenecks. Existing caching solutions focus on exact-match queries, limiting their effectiveness for semantic knowledge reuse. To address this challenge, we introduce Asteria, a novel cross-region knowledge caching architecture for LLM agents. At its core are two abstractions: Semantic Element (SE) and Semantic Retrieval Index (Sine). A semantic element captures the semantic embedding representation of an LLM query together with performance-aware metadata such as latency, cost, and staticity. Sine then provides two-stage retrieval: a vector similar index with semantic embedding for fast candidate selection and a lightweight LLM-powered semantic judger for precise validation. Atop these primitives, Asteria builds a new cache interface that includes a new semantic-aware cache hit definition, a cost-efficient eviction policy, and proactive prefetching. To reduce overhead, Asteria co-locates the small LLM judger with the main LLM using adaptive scheduling and resource sharing. Our evaluation demonstrates that Asteria delivers substantial performance improvements without compromising correctness. On representative search workloads, Asteria achieves up to a 3.6$\times$ increase in throughput by maintaining cache hit rates of over 85%, while preserving accuracy virtually identical to non-cached baselines. Asteria also improves throughput for complex coding tasks by 20%, showcasing its versatility across diverse agentic workloads.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
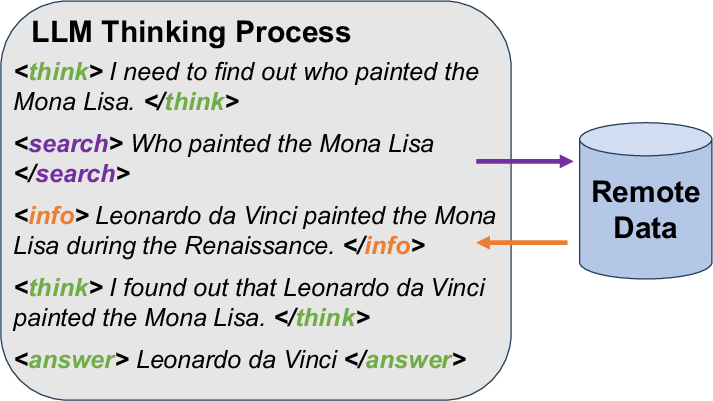
This paper introduces Asteria, a system that makes AI assistants (LLM “agents”) faster and cheaper when they need to look things up on the internet or other remote services. Instead of always paying time and money to call an outside tool (like a web search API), Asteria “caches” knowledge. But it doesn’t just cache exact copies of old questions—it understands meaning. That way, if a new question means the same thing as an old one (even if it’s worded differently), Asteria can safely reuse the earlier result.
What questions were the researchers trying to answer?
They focused on a few simple questions:
- Can we safely reuse past answers when new questions have the same meaning but different words?
- Can we do this without making mistakes (i.e., keep accuracy high)?
- Can this cut down the time (latency) and money (API fees) caused by calling tools in faraway data centers?
- Can we run the needed “meaning checks” efficiently on the same computer that runs the main AI model?
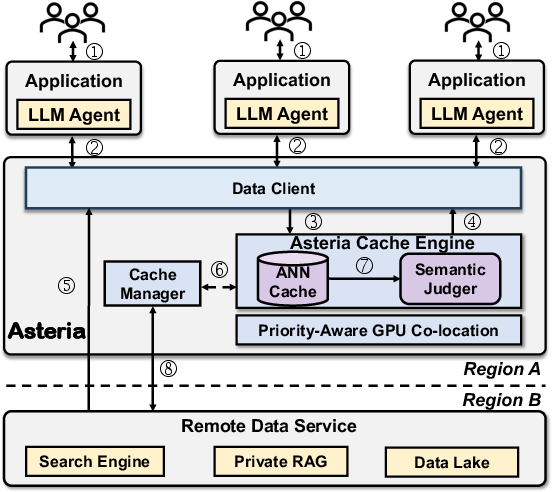
How does Asteria work?
Think of an AI assistant doing homework. It often searches the web, waits for results, then reasons about them. Calling a remote search engine takes time and costs money. Asteria saves time and money by keeping a smart notebook of past lookups and reusing them when the new question means the same thing.
Here are the main ideas, explained with everyday analogies:
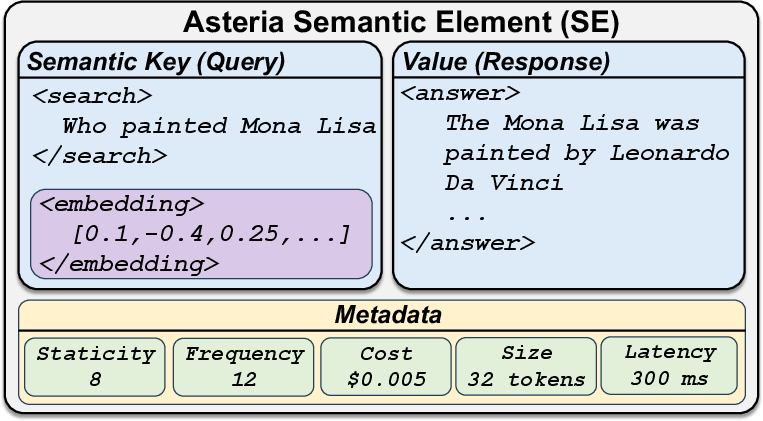
1) Semantic Elements: “Smart flashcards” for past lookups
A Semantic Element (SE) is like a flashcard the system saves each time it calls a tool:
- Front (the “key”): the exact question or tool request (for example, “Who painted the Mona Lisa?”).
- Back (the “value”): the answer it got back (for example, “Leonardo da Vinci” + a short snippet).
- Notes about the card: how long it took, how much it cost, how often it’s been used, how big it is, and a “staticity” score (how likely the fact stays true over time—“Mona Lisa’s painter” is very stable; “today’s weather” changes fast).
- A “meaning fingerprint”: the question is turned into numbers (an “embedding”) that capture its meaning, not just its exact words.
2) Sine: a two-step “are these the same meaning?” check
When a new question comes in, Asteria doesn’t immediately call the internet. It first asks: “Have we already answered this, or something that means the same thing?”
To decide quickly and accurately, Asteria does two checks:
- Fast similarity filter: a nearest-neighbor search finds past questions that look similar in meaning. This is like quickly flipping through flashcards that feel close to the new question.
- Careful LLM judge: a small, fast AI “judge” then double-checks the best candidates and says “yes, this old answer truly answers the new question” or “no, it doesn’t.” Only if the judge agrees does Asteria reuse the cached answer.
This two-step process avoids the usual problem of “close but wrong” matches from simple similarity.
3) A smart cache manager: keep the best, drop the rest, and guess what’s next
Because the cache can’t grow forever, Asteria needs to decide what to keep:
- Cost-aware eviction: instead of just keeping the most recent or most frequent items, Asteria scores each flashcard by:
- How often it’s used,
- How expensive or slow it was to fetch,
- How stable the fact is,
- How big it is.
- Cards that save more time/money per byte and stay correct longer are kept; others are evicted first.
- Predictive prefetching: the system also “guesses” what you’ll likely ask next (based on past patterns) and fetches those answers ahead of time—so the cache is ready when you need them.
4) Running the big AI and the small judge together
Asteria runs the main AI assistant and the small judge model on the same GPU (graphics processor) to save hardware. A simple scheduler gives priority to the main assistant (user-facing work), and only uses leftover capacity for the judge (background checks). That way, the judge never slows down the main assistant.
What did they find?
The researchers tested Asteria on search-like tasks and coding tasks. Here’s what happened:
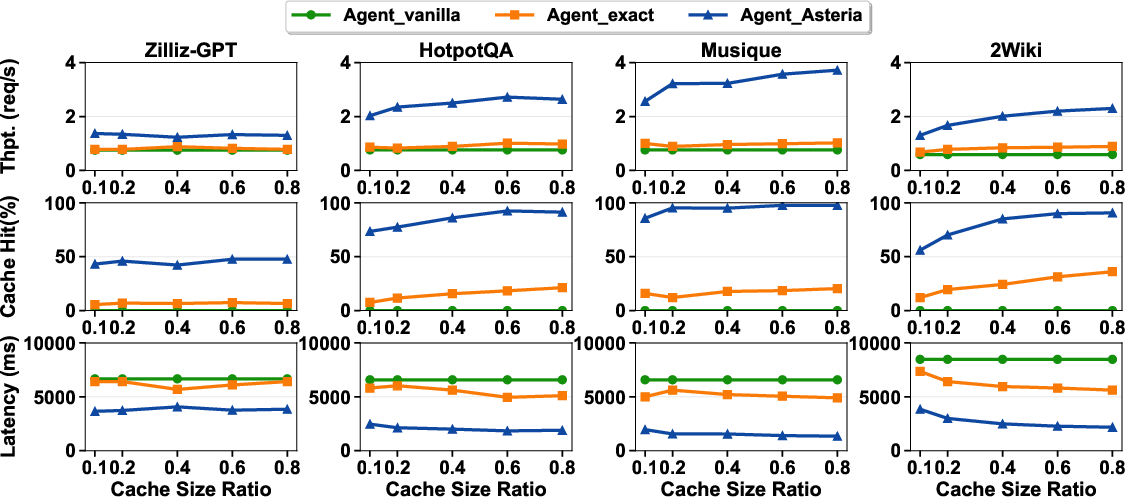
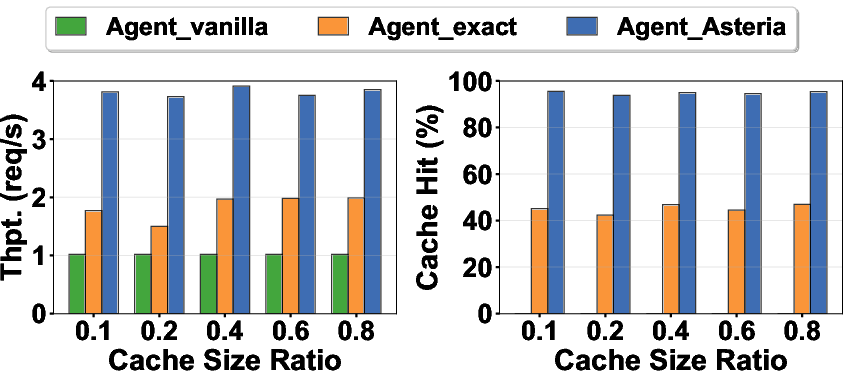
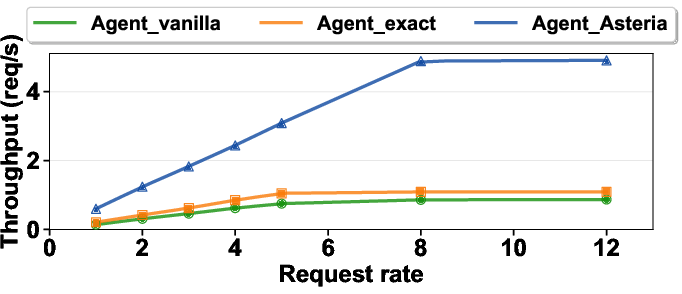
- On search workloads:
- Throughput (how many tasks per unit time) went up by as much as 3.6×.
- The cache hit rate stayed high (over 85%), meaning most requests could be served from the cache.
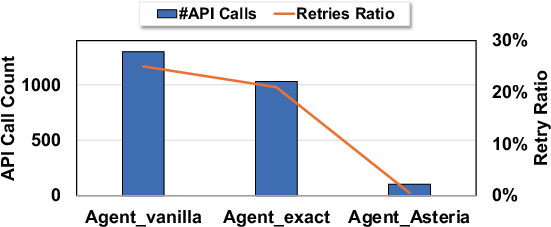
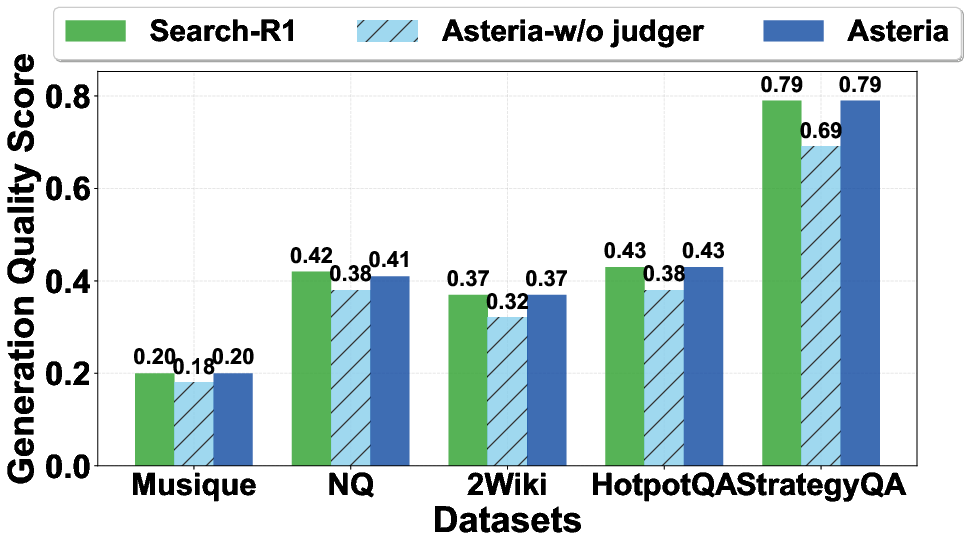
- Accuracy stayed almost identical to not using a cache at all. This is important: a naive “semantic cache” without the careful judge made more mistakes, but Asteria’s judge kept correctness high.
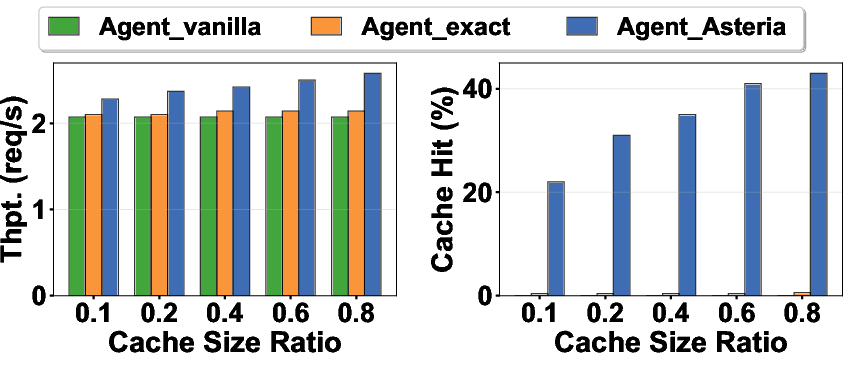
- On complex coding tasks:
- Throughput improved by about 20%.
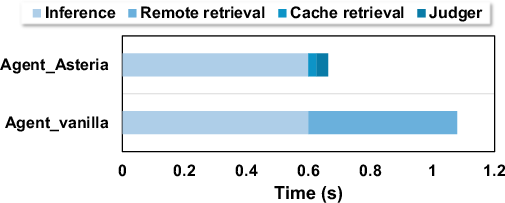
Why this matters: these gains mean faster responses for users, fewer delays caused by long-distance calls to remote services, and much lower API costs.
Why does this matter and what could it change?
Asteria shows a practical way to make AI assistants:
- Faster: less waiting for faraway services.
- Cheaper: fewer paid API calls.
- Safer: careful checking keeps answers correct even when reusing past results.
- Scalable: better throughput helps when there are lots of users or strict rate limits on tools.
This approach could help many AI apps—search assistants, coding helpers, research tools, and more—especially those that frequently look up information online. In short, Asteria turns “smart reuse of knowledge” into a dependable, cost-saving feature, without sacrificing accuracy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper; each item is phrased to be concrete and actionable for future researchers.
- Lack of rigorous, reproducible accuracy evaluation: the claim of “virtually identical” correctness to non-cached baselines is not backed by clear metrics (precision/recall, error types, confidence intervals), benchmark datasets, or public evaluation artifacts.
- Ground-truth acquisition for judger calibration is unspecified: the FetchGT/EvaluateGT process, its cost, provenance, and methodology for diverse query types (factual, time-sensitive, subjective) are not defined, making LSM threshold recalibration hard to reproduce and audit.
- No treatment of multilingual, cross-lingual, and multi-modal queries: it is unclear whether the embedding model, ANN index, and LSM generalize to non-English queries, code-mixed inputs, or tool calls that return images/tables/structured JSON.
- Unclear handling of user-specific context and personalization: the cache key definition does not state how user/session context, preferences, permissions, or personalization are incorporated to avoid cross-user leakage or serving context-inappropriate results.
- Rate-limit awareness is claimed but not designed or evaluated: there is no algorithmic detail (e.g., token bucket, admission control, request shaping) nor quantitative evidence that Asteria improves throughput under real API rate limits.
- Staleness control is simplistic and static: TTL is user-defined and not tied to staticity, topic drift, or change detection; dynamic TTL, freshness heuristics, and automatic refresh under fast-changing topics are not investigated.
- Staticity scoring validity is unproven: the 1–10 staticity scale produced by the judger lacks calibration, inter-annotator agreement, domain transfer evaluation, and demonstrated correlation with true change rates of topics/tools.
- No policy for semantic versioning or provenance tracking of cached values: how to track the source version, timestamp, schema changes, and provenance to support safe reuse and reproducibility is not addressed.
- Prefetching model is overly simplistic and unevaluated: the first-order Markov process lacks ablation against higher-order models, sequence modeling (e.g., Transformers), or RL-based strategies; prefetch precision/recall, pollution rate, and impact on eviction are not quantified.
- ANN index scalability and concurrency are underexplored: memory footprint, build/update costs, online insertion throughput, lock/contention behavior, and performance under high concurrent agent traffic are not reported.
- Embedding model overhead and selection criteria are not analyzed: the choice of a 0.6B embedding model (vs. smaller optimized models) and its latency/cost contribution per query are not measured or optimized.
- Threshold optimization is incomplete: dynamic adaptation of the ANN similarity threshold ($\tau_{\text{sim}$) is not addressed, and joint tuning of $\tau_{\text{sim}$ and $\tau_{\text{lsm}$ under workload drift remains an open problem.
- LCFU eviction scoring needs calibration and unit normalization: the score formula mixes frequency, latency, cost, staticity, and size via logarithms and ad hoc scaling (e.g., cost × 103) without sensitivity analysis, unit harmonization, or fairness checks against different tool types.
- Cache pollution risks are insufficiently addressed: speculative prefetches and near-miss admissions may pollute the cache; safeguards like negative caches, confidence debiasing, or quarantine zones are not explored.
- Distributed deployment, replication, and coherence are not designed: cross-region cache synchronization, consistency models (e.g., eventual vs. strong), invalidation propagation, and conflict resolution across multiple Asteria instances are missing.
- Security, privacy, and compliance are not considered: caching external tool results may store PII or copyrighted data; policies for redaction, encryption at rest/in transit, tenancy isolation, GDPR/CCPA compliance, and auditability are absent.
- Robustness to adversarial inputs and model misuse remains open: semantic caching could be exploited via prompt injection, poisoning of cached values, or adversarial examples targeting the LSM; detection and mitigation strategies are not discussed.
- Failure handling and resilience are unspecified: behavior under tool outages, partial network failures, cache corruption, ANN index rebuilds, and judger model failures lacks design and experimental validation.
- Interaction with existing inference caches (KV/prompt caches) is unexplored: the synergistic or conflicting effects of combining Asteria with transformer KV caches or prompt caches have not been studied.
- Comparison against alternative baselines is limited: replicating or relocating the remote data service (edge caching, CDN, regional mirroring), or using vendor-side semantic caches, is not benchmarked to contextualize Asteria’s benefits vs. simpler deployments.
- Cost savings are not quantified end-to-end: while throughput and hit rates are reported, there is no comprehensive accounting of API/tool cost reduction, GPU utilization gains, and amortized overheads from embeddings, judger, ANN maintenance, and storage.
- Latency distribution and tail behavior are not reported: p50/p95/p99 latency impacts, especially under bursty workloads and rate-limit regimes, remain unknown; only throughput metrics are highlighted.
- Tool heterogeneity and schema generality are unclear: the SE abstraction’s applicability to diverse tools (web search, databases, SaaS APIs with complex schemas) and non-deterministic responses (e.g., search rankings) is not validated.
- Handling of dynamic code corpora and repository updates is not specified: for coding tasks, cache invalidation when repositories change, branch/version awareness, and mapping from semantic queries to canonical file identifiers need definition and evaluation.
- Memory management and scheduler details are underspecified: the “unified dynamic memory pool,” fragmentation handling, KV cache sizing, and integration with vLLM/MPS under mixed workloads require concrete algorithms and stress-test results.
- Generalization beyond two domains is not demonstrated: only search and coding are mentioned; applicability to analytics, data science tools, enterprise knowledge bases, or multi-hop toolchains remains an open question.
- Data/model governance and retraining cadence are missing: policies for continuous LSM fine-tuning, monitoring for concept drift, data selection, labeling pipelines, and rollback mechanisms are not described.
- Reproducibility and open-sourcing are absent: datasets, configuration files, prompts for the judger, code for LCFU/prefetching, and scripts for ANN index management are not provided to enable independent verification.
Practical Applications
Immediate Applications
These applications can be deployed now using the paper’s methods (SEs, Sine ANN+judger pipeline, LCFU eviction, predictive prefetching, GPU co-location) with existing LLM-agent stacks and tool APIs.
- Software/Developer Tools — IDE-integrated coding assistants with RAG
- What: Cache semantically equivalent file lookups and repository context retrievals to accelerate code agents (e.g., SWE-bench-style tasks), yielding ~20% throughput gains and fewer cross-region calls.
- Product/workflow: Asteria-backed “RepoCache” plugin for IDEs; FAISS-backed RAG gateway with LCFU; Markov prefetch for next-file access.
- Dependencies/assumptions: MCP or tool-call wrappers expose <tool>/<info> blocks; repository content licenses permit caching; staticity and TTL tuned per repo; judger fine-tuned on code tasks.
- Search/Consumer AI — AI search mode and web copilots
- What: Front the Search API with semantic cache to handle Zipfian and bursty queries, cutting latency/cost and smoothing rate-limit ceilings; up to 3.6× throughput improvement at >85% hit rate.
- Product/workflow: “Asteria Gateway” reverse-proxy between agent and search APIs (Google, Bing), with offline LSM recalibration and prefetch driven by trending topics.
- Dependencies/assumptions: API ToS allow caching; TTL and staticity protect freshness for news; LSM thresholds audited for correctness; cross-region cache placement near agent.
- Enterprise Knowledge Management — Internal copilots (RAG over wikis, tickets, CRM)
- What: Cache semantically equivalent knowledge snippets across teams to reduce repeated pulls from remote KBs and search services.
- Product/workflow: Drop-in Python SDK for vLLM-based agents; cost-aware LCFU tuned for high-latency private RAG stores; org-wide cache replication.
- Dependencies/assumptions: Data governance/PII policy allows caching; audit trails and TTLs enforced; per-tenant isolation; embedding/LSM models permitted on-prem.
- Customer Support — FAQ and troubleshooting agents
- What: Reuse high-staticity answers (FAQs, policies, how-tos), minimizing API spend and improving response times during spikes.
- Product/workflow: FAQ cache with semantic judger; predictive prefetch of follow-up flows; dashboard for hit-rate and cost savings.
- Dependencies/assumptions: Content versioning emits cache-busting TTLs; freshness hooks on policy updates; multi-locale handling.
- Finance/Research — Analyst copilots for filings/news
- What: Cache stable entity definitions, recurring ratios/formulae, and historic filings; validate time-sensitive items (prices/news) with judger + short TTL.
- Product/workflow: Dual-tier cache (static vs. volatile) with different TTL/staticity thresholds; LCFU weighted by API costs.
- Dependencies/assumptions: Market data licenses/ToS permit caching; strict TTLs for live quotes; correctness monitoring.
- Healthcare — Clinical guideline lookup in CDS agents
- What: Cache stable clinical guidelines and dosing tables with high staticity; enforce TTL and provenance to preserve safety.
- Product/workflow: Whitelist-only cache with long TTL for guidelines; judger tuned on biomedical QA; provenance attached to SE values.
- Dependencies/assumptions: Regulatory compliance (HIPAA/PHI) excludes patient data from cache; institutional approval; frequent audits.
- Legal — Case law and statute retrieval for research assistants
- What: Cache canonical passages of frequently cited cases; reduce repeated cross-region pulls from legal databases.
- Product/workflow: Semantic cache with strict provenance and edition/version tags; eviction tuned to subscription-access costs.
- Dependencies/assumptions: Publisher ToS permit caching excerpts; accurate versioning; high-precision LSM to avoid mis-citations.
- E-commerce — Product Q&A and comparison chatbots
- What: Cache stable product specs and FAQs; prefetch related SKUs during comparison flows.
- Product/workflow: Prefetch graph based on SKU co-views; LCFU emphasizes API cost and size-normalized savings.
- Dependencies/assumptions: Rapidly changing inventory/prices require low TTLs; consistent schema for product updates.
- Public Sector — Government service chatbots (tax, benefits)
- What: Cache stable policy explanations; smooth rate limits during filing seasons; reduce inter-region dependency.
- Product/workflow: Regional cache replicas; strict TTL on policy changes; accuracy audits and offline recalibration.
- Dependencies/assumptions: Data residency rules; legal mandate to ensure correctness; public-record provenance.
- Education — Course-aware tutoring agents
- What: Cache curriculum-aligned explanations, definitions, and problem solutions with high staticity and provenance.
- Product/workflow: Course-pack caches per class/term; prefetch for sequential curricula; offline recalibration via instructor-provided ground truth.
- Dependencies/assumptions: Academic integrity policies; version control for course content; multilingual embeddings where needed.
- Platform/Infra — GPU cost optimization via co-location
- What: Run a ~7B agent and ~1B judger on a single GPU using MPS-based asymmetric partition and priority scheduler for latency protection.
- Product/workflow: Scheduler module for vLLM with unified dynamic memory pool; usage in on-prem or cloud GPU fleets.
- Dependencies/assumptions: CUDA MPS availability; predictable judger KV footprint; careful SLO tuning.
- Operations/SRE — Rate-limit resilience and cost governance
- What: Use semantic hits to stay under upstream API quotas and cap spend without user-visible degradation.
- Product/workflow: Policy knobs: rate-limit-aware admission, surge prefetch for predicted bursts, cost-per-byte LCFU scoring.
- Dependencies/assumptions: Accurate API quota telemetry; reliable cost/latency metadata in SE.
Long-Term Applications
These applications require additional research, scaling, ecosystem design, or compliance work before widespread deployment.
- Cross-Org Semantic CDN for Tool Responses
- What: A cache network that shares vetted, high-staticity SEs across tenants or regions to offload popular queries globally.
- Potential: “Semantic CDN” with signed SEs, deduplication, and freshness channels from origin APIs.
- Dependencies/assumptions: Strong multi-tenant isolation, differential privacy, licensing for content redistribution, interoperable SE schema.
- Cache-Aware Agent Planning
- What: Agents incorporate cache state (hit probabilities, TTLs, costs) into tool-use decisions to minimize latency/cost while meeting accuracy targets.
- Potential: Planners that condition prompts on cache hints; tool-selection policies that prefer cached sources.
- Dependencies/assumptions: Planner–cache APIs; stable estimates of hit-rate and staleness; reward shaping for cost-latency-accuracy trade-offs.
- Domain-Specialized Judgers and Staticity Models
- What: Highly accurate, small LLM judgers for safety-critical domains (medicine, law, finance) with certified thresholds.
- Potential: Auditable LSMs, calibration pipelines with domain GT evaluators, model cards for regulatory acceptance.
- Dependencies/assumptions: High-quality labeled datasets; formal calibration; external certification processes.
- Event-Aware Prefetching and Freshness Protocols
- What: Integrate exogenous signals (news, social, telemetry) to anticipate bursts and refresh caches proactively.
- Potential: Connectors to trend APIs; publisher-provided freshness hooks (ETags/feeds) to update SEs.
- Dependencies/assumptions: Reliable event feeds; contracts with content providers; false-positive control for speculative prefetch.
- Privacy-Preserving Multi-Party Caching
- What: Federated or encrypted caches enabling cross-team reuse without exposing sensitive content.
- Potential: Secure enclaves, searchable encryption for embeddings, differential privacy on access patterns.
- Dependencies/assumptions: Practical secure vector search; acceptable performance overhead; compliance validation.
- Policy/Compliance Tooling for Cached AI Systems
- What: Governance layers to manage ToS, data residency, copyright, and liability for served cached answers.
- Potential: Policy-as-code over SE metadata; automated TTL/provenance enforcement; audit logs and redress mechanisms.
- Dependencies/assumptions: Consensus standards for SE provenance; regulator guidance; upstream provider agreements.
- Marketplace for High-Staticity SE Packs
- What: Curated, licensed bundles of vetted SEs (e.g., canonical facts, domain glossaries) that bootstrap caches.
- Potential: “Knowledge packs” per vertical; signed, versioned distributions with update channels.
- Dependencies/assumptions: Licensing models; standard SE formats; trust infrastructure for signatures.
- Edge/On-Device Semantic Caching
- What: Personal agents caching common tool responses locally to reduce network use and improve privacy.
- Potential: Mobile-friendly ANN indices; tiny judgers; intermittent sync with cloud freshness signals.
- Dependencies/assumptions: Efficient on-device embeddings; storage/compute limits; privacy-preserving sync.
- Native GPU Runtime Support for Multi-Model Co-location
- What: First-class runtime primitives (beyond MPS) for priority and memory QoS across heterogeneous models.
- Potential: Vendor APIs that expose latency SLOs and partitioning policies; scheduler-aware KV caching.
- Dependencies/assumptions: GPU vendor support; ecosystem adoption; performance validation at scale.
- Cross-Provider Rate-Limit Negotiation and Credits
- What: Mechanisms where caches earn quota credits or negotiated terms for reducing upstream load.
- Potential: “Cache-friendly” API tiers; verifiable hit reports; economic incentives for semantic reuse.
- Dependencies/assumptions: Provider cooperation; secure metering; industry standards.
- Safety-Critical “Never-Serve-Stale” Modes
- What: Conservative cache modes that require dual validation (judger + external freshness check) before serving.
- Potential: Double-check protocols for medical/legal outputs; fail-open-to-live-fetch on uncertainty.
- Dependencies/assumptions: Fast, reliable freshness endpoints; calibrated uncertainty estimates; acceptable latency overhead.
- Research/Academia — Low-Cost Shared Benchmarks for Agents
- What: Open caches of SEs to reduce evaluation cost and promote reproducibility across labs.
- Potential: Shared SE corpora with labels; plug-and-play with popular agent frameworks.
- Dependencies/assumptions: Dataset licensing; community curation; baseline judger models.
Notes on feasibility and assumptions across applications:
- Structured tool I/O is assumed (e.g., MCP <tool>/<info> tags) to construct SEs reliably.
- Correctness hinges on judger quality and calibrated thresholds; periodic offline recalibration and monitoring are critical.
- Freshness must be enforced via TTL/staticity and, ideally, upstream provenance/freshness signals.
- Legal/ToS constraints for caching third-party content must be honored; data residency and PII policies may restrict scope.
- Performance depends on robust ANN infrastructure, memory budgets for indices, and cross-region placement strategy.
- Rate-limit resilience is complementary to provider policies; caching should not be used to circumvent contractual limits.
Glossary
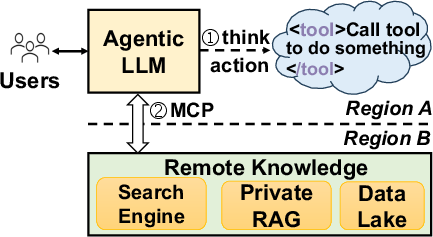
- Agentic LLM: LLMs that operate in a think–act–observe loop, issuing tool calls and integrating results iteratively. "Agentic LLM workloads rely heavily on remote tool calls, whose cost and latency often dominate performance."
- Approximate Nearest Neighbor (ANN): A fast, approximate search technique over vector embeddings to retrieve similar items efficiently. "We then propose Semantic Retrieval Index (Sine), a two-stage retrieval engine that combines 1) an Approximate Nearest Neighbor (ANN) search for high-recall candidate selection..."
- Asteria: A semantic-aware cross-region caching system for LLM agents that validates and reuses external knowledge. "We present Asteria, a concrete implementation of semantic-aware knowledge caching."
- CUDA Multi-Process Service (MPS): A CUDA feature that enables multiple processes to share a GPU context and partition compute resources. "To capitalize on this, we use the CUDA Multi-Process Service (MPS)~\cite{cuda-mps} to create a static, asymmetric compute partition..."
- FAISS: A high-performance library for efficient similarity search and clustering of dense vectors. "For coding, we use a self-deployed FAISS~\cite{douze2024faiss}-based RAG service~\cite{douze2024faiss} with an average 300\,ms round trip."
- Geo-distributed: Deployed across multiple geographic regions or clouds, often incurring cross-region latency. "...improving performance and operational efficiency in geo-distributed LLM agent deployments."
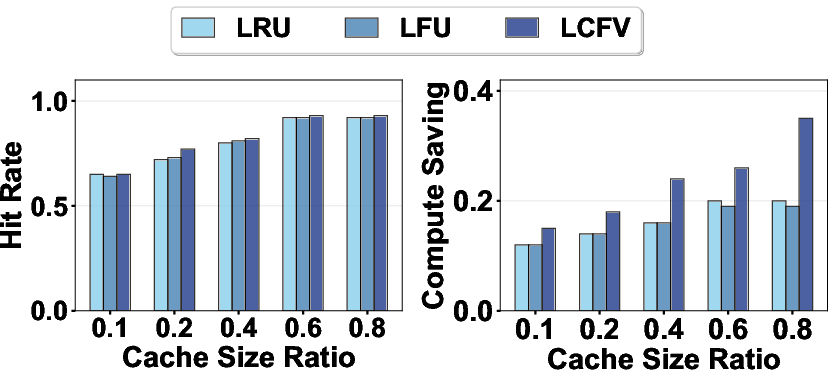
- LCFU eviction policy: A value-based cache eviction strategy that considers latency, cost, frequency, staticity, and size. "With a reliable access signal established, we employ a tailored Least Cost-Efficient and Frequently Used (LCFU) eviction policy to manage the cache's contents."
- Lightweight semantic judger model (LSM): A small LLM/classifier that validates semantic equivalence of cached results and estimates staticity. "The LSM evaluates if the cached result is a sufficient answer for the new query , producing a confidence score $S_{\text{lsm}$."
- Markov model: A probabilistic model where the next state depends only on the current state, used here for predictive prefetching. "Using a lightweight first-order Markov model, it calculates the probability ..."
- Model Context Protocol (MCP): A protocol for transmitting tool-use commands/queries between LLM agents and external services. "...over the model context protocol (MCP~\cite{antropic2024mcp}) to a remote data source."
- Predictive prefetching: Proactively fetching likely next items based on historical access patterns to reduce future miss latency. "...predictive prefetching, driven by SE metadata."
- Priority-aware scheduler: A scheduler that prioritizes latency-critical agent tasks over deferrable judger tasks when sharing GPU resources. "...managed by a priority-aware scheduler that protects the agent's critical latency paths."
- Retrieval-Augmented Generation (RAG): Augmenting LLM outputs by retrieving relevant external knowledge to include in the context. "...either private knowledge bases via retrieval-augmented generation (RAG) \cite{lewis2020retrieval}..."
- Semantic Element (SE): The cache unit that packages an agent’s query/tool action, the retrieved result, and performance-aware metadata. "At its core are two abstractions: Semantic Element (SE) and Semantic Retrieval Index (Sine)."
- Semantic embedding: A vector representation of text that captures meaning for similarity-based retrieval and matching. "A semantic element captures the semantic embedding representation of an LLM query together with performance-aware metadata..."
- Semantic judger: A lightweight LLM component that validates whether a candidate cache entry truly answers a new query. "...a lightweight LLM-powered semantic judger for precise validation."
- Semantic Retrieval Index (Sine): A two-stage retrieval pipeline combining ANN candidate selection and LLM-based validation. "We then propose Semantic Retrieval Index (Sine), a two-stage retrieval engine..."
- Time-To-Live (TTL): A freshness control parameter specifying the maximum lifespan of a cache entry to prevent staleness. "To prevent outdated information from persisting, Asteria integrates an aging mechanism using a user-defined Time-To-Live (TTL)."
- Transformer KV-caches: Caches of key–value attention states used to accelerate transformer decoding for repeated or similar prompts. "Transformer KV-caches~\cite{kwon2023efficient,gim2024prompt,liu2024cachegen} store token KV states to accelerate model decoding..."
- Unified dynamic memory pool: A shared GPU memory pool managed by a priority-aware controller to admit batches under contention. "...manages the unified dynamic memory pool ($M_{\text{dynamic}$)."
- vLLM: A high-throughput LLM serving system used as the foundation for intercepting tool calls and co-location. "Asteria is implemented in Python atop vLLM~\cite{vllm_repo}, which we use as the high-throughput serving layer..."
- Wide-area network (WAN): A network spanning large geographic areas, introducing cross-region latency between agents and tools. "...are connected by a wide-are network (WAN)."
- Zipfian distribution: A skewed distribution where a few “head” items account for most frequency, with a long tail of rare items. "Search queries follow a Zipfian distribution: a few topics draw most traffic while the majority form a long tail."
Collections
Sign up for free to add this paper to one or more collections.