- The paper introduces RadarSFD, a novel single-frame diffusion method that leverages pretrained depth priors to generate dense, LiDAR-like point clouds from radar data.
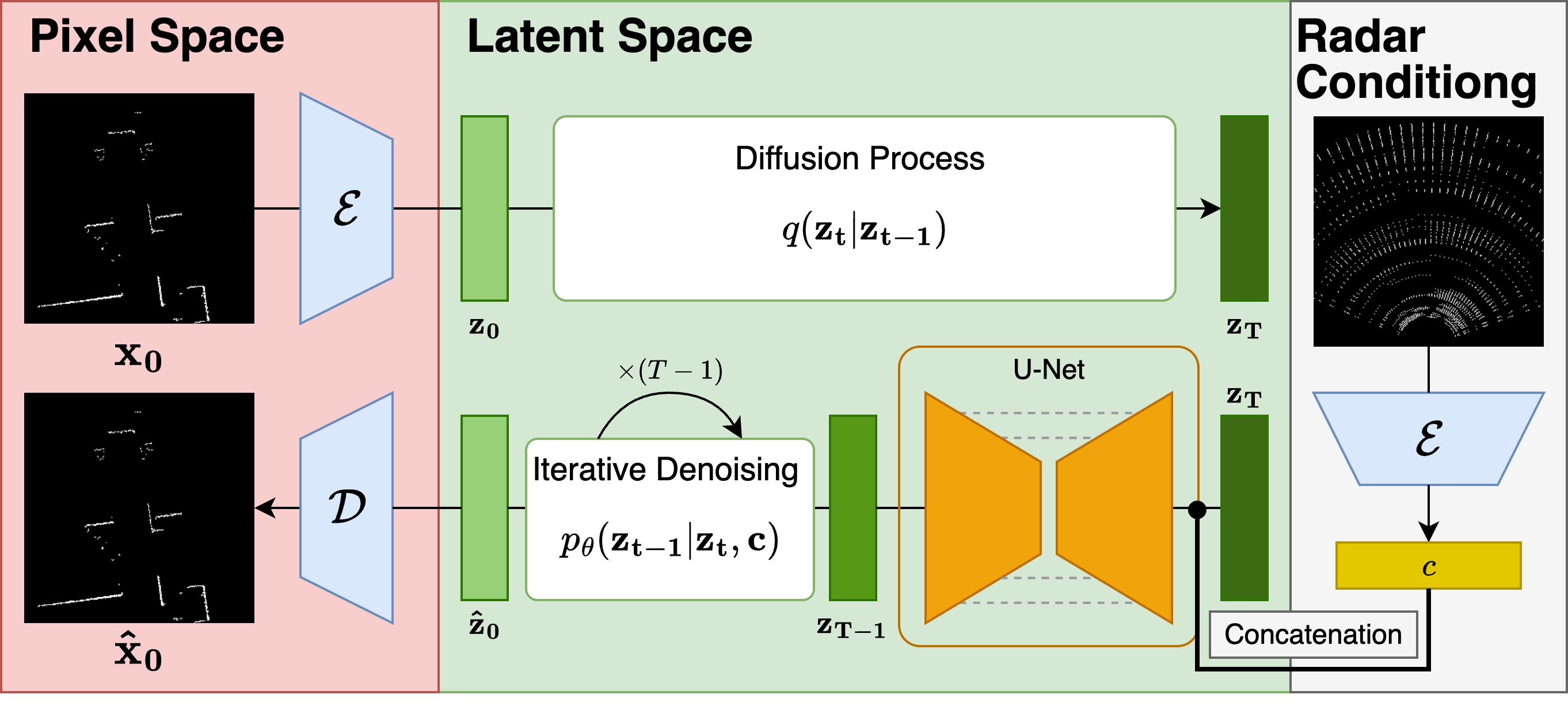
- The approach integrates a frozen VAE and a U-Net conditioned on radar and noisy LiDAR latents, ensuring precise spatial alignment in the reconstruction process.
- Evaluation on RadarHD benchmarks shows improved metrics with a 35 cm Chamfer Distance and 28 cm Modified Hausdorff Distance, outperforming traditional multi-frame methods.
RadarSFD: Single-Frame Diffusion with Pretrained Priors for Radar Point Clouds
Introduction
RadarSFD represents a novel approach to overcoming the limitations of radar imaging in compact robotic platforms by leveraging the robustness of millimeter-wave (mmWave) radar under challenging environmental conditions. Unlike traditional radar systems that rely heavily on synthetic aperture radar (SAR) or multi-frame aggregation, RadarSFD reconstructs dense, LiDAR-like point clouds using a single radar frame. This technique is particularly suited for platforms with stringent size, weight, and power (SWaP) constraints, as it obviates the need for extensive hardware setups or complex data aggregation methods.
Methodology
RadarSFD uses a conditional latent diffusion model that integrates pretrained geometric priors from a monocular depth estimator into the radar processing pipeline. The model operates by encoding radar and LiDAR images into a latent space using a frozen VAE, leveraging U-Nets initialized with depth priors from models like Marigold. This method conditions the latent diffusion process on radar input, ensuring the model effectively reconstructs high-resolution point clouds from radar data.
Diffusion Model Process
The forward process adds Gaussian noise to the original LiDAR BEV over multiple timesteps, while the reverse process employs a U-Net to iteratively remove noise, guided by radar data (Figure 1). This effectively reconstructs high-resolution scenes from seemingly noisy radar inputs.
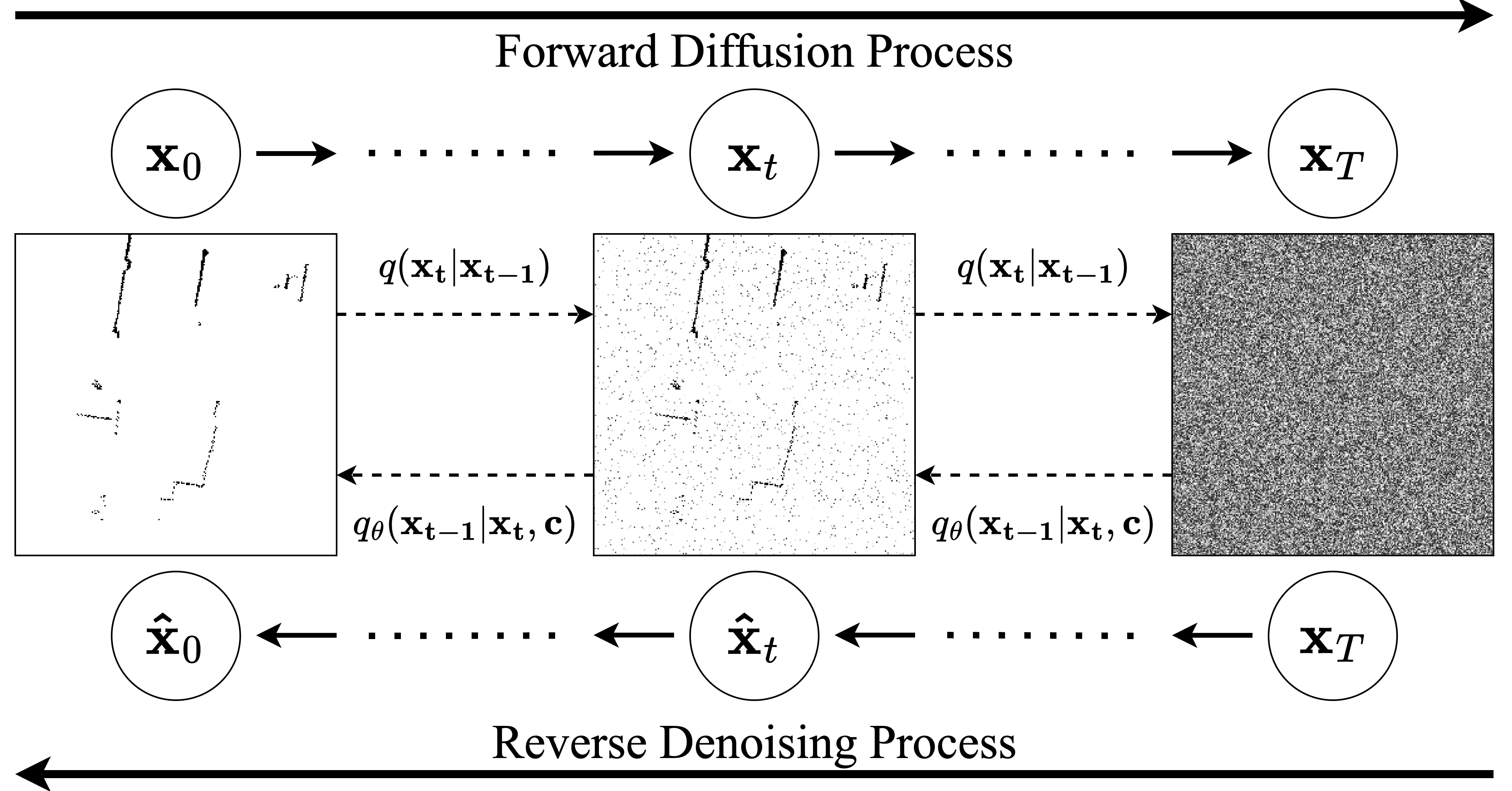
Figure 1: The forward and reverse process of a diffusion model.
Architectural Design
RadarSFD's architecture enables efficient single-frame radar-to-LiDAR translation through several key components (Figure 2):
Evaluation
Quantitative Results
RadarSFD achieves significant improvements in reconstruction metrics compared to both traditional and newer learning-based methods, demonstrating a Chamfer Distance (CD) of 35 cm and Modified Hausdorff Distance (MHD) of 28 cm on the RadarHD benchmark. These results outperform existing single-frame radar approaches and remain competitive with multi-frame methods like RadarHD, which aggregates data from up to 41 frames.
Generalization and Real-World Testing
Evaluation on unseen environments confirms RadarSFD's robust generalization capabilities (Figure 3). The integration of pretrained priors sustains high performance across diverse scenarios, making it suitable for practical deployment in real-world conditions.










Figure 3: Real world test for generalization with completely unseen data in a campus building. All models are trained on the same radar dataset.
Qualitative Analysis
Qualitative comparisons reveal that RadarSFD effectively reconstructs scene boundaries and fine structural details, achieving clarity comparable to LiDAR ground truth in many instances (Figure 4). This fidelity underscores the model's ability to address common artifacts in radar perception, such as blurring and structural loss.



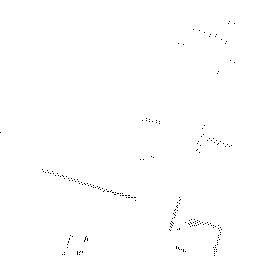

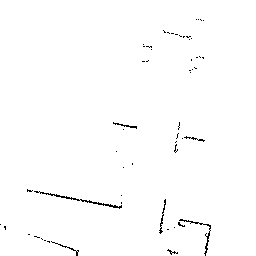
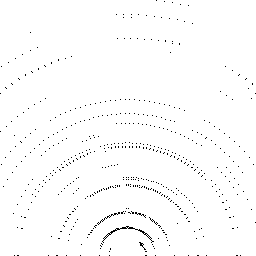


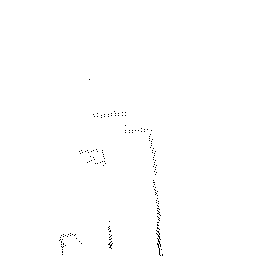





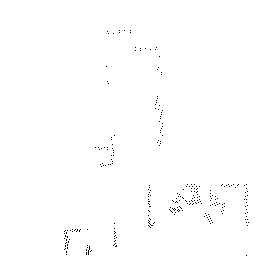





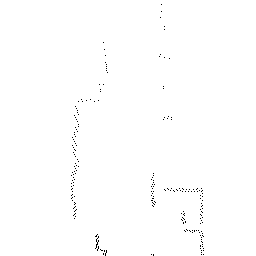
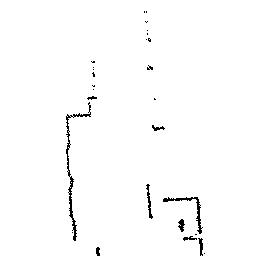
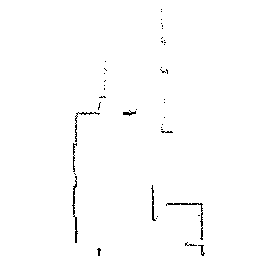
Figure 4: Qualitative comparison of point cloud reconstructions on four representative scenes with varying complexity.
Conclusion
RadarSFD establishes a pioneering single-frame radar processing framework that aligns well with SWaP-constrained environments while delivering superior point cloud resolution and fidelity. The system's innovative use of diffusion models, pretrained depth priors, and efficient latent space operations highlight a promising direction for future developments in cross-modality sensor translation. The results suggest that latent-space diffusion models, when equipped with well-aligned priors, hold substantial potential for advancing single-frame radar applications in autonomous systems.