- The paper introduces SurgMINT, a unified framework that uses optical flow–based label interpolation to address the temporal–spatial annotation imbalance in surgical videos.
- The framework employs multi-task learning with Mask2Former and MViT, significantly improving performance metrics such as step mAP from 80.93 to 85.61.
- The method enhances surgical workflow analysis by accurately modeling instrument segmentation, action detection, and step anticipation for improved robot-assisted surgery support.
Surgical Video Understanding with Label Interpolation: A Technical Analysis
Introduction
The paper presents SurgMINT, a unified framework for surgical video understanding that addresses the temporal–spatial annotation imbalance inherent in medical datasets. The approach integrates optical flow–based segmentation label interpolation with multi-task learning (MTL), enabling robust modeling of surgical workflows, instrument segmentation, action detection, and step anticipation. The framework is designed to maximize the utility of robot-assisted surgery (RAS) by leveraging both long-term (phase, step) and short-term (instrument, action) annotations, which are typically unevenly distributed across video frames.
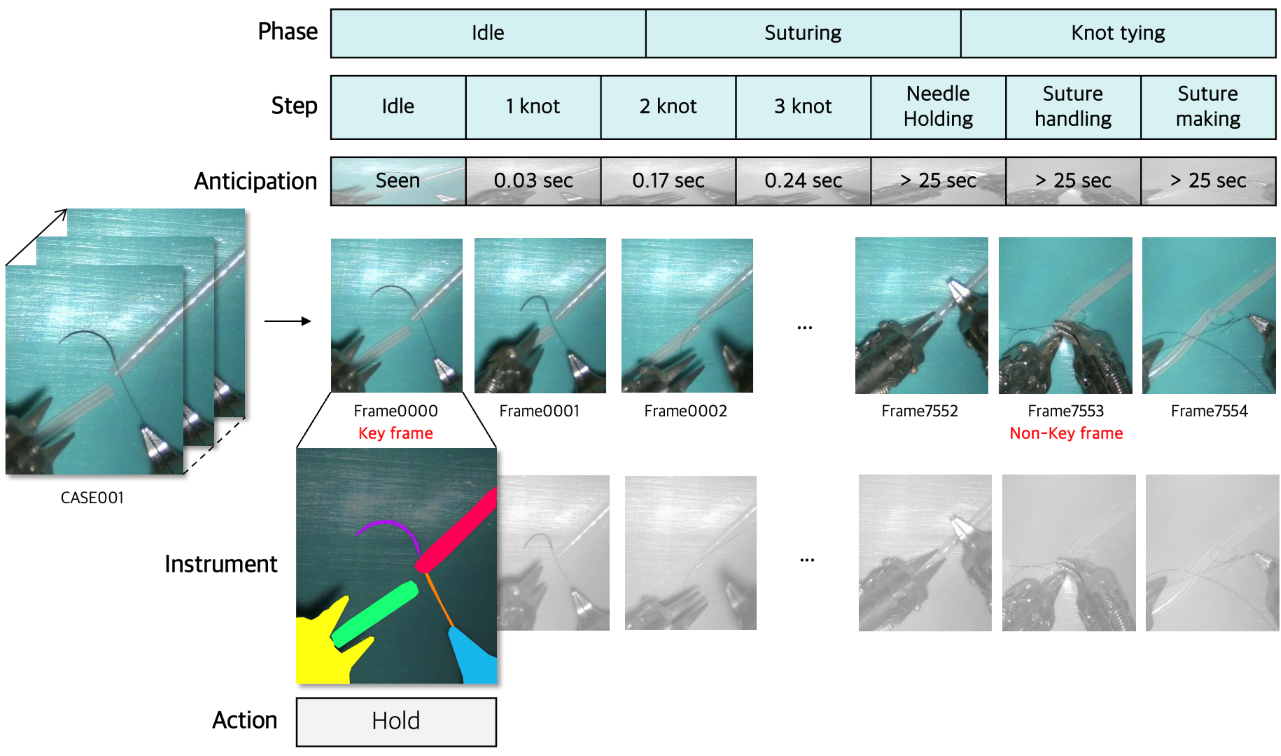
Figure 1: Illustration of the temporal–spatial annotation imbalance in medical datasets, highlighting the disparity between dense temporal annotations and sparse spatial annotations.
Methodology
Segmentation Label Interpolation via Optical Flow
SurgMINT propagates sparse instrument segmentation labels from annotated key frames to adjacent unlabeled frames using optical flow, specifically employing RAFT for dense flow estimation. The interpolation process is structured into three branches:
- Segmentation Branch: Utilizes a lightweight FPN-based segmentation network to predict instrument masks on non-key frames, supervised by consistency loss with warped labels.
- Warping Branch: Applies RAFT to estimate flow fields between key and non-key frames, warping ground-truth masks to generate pseudo-labels. Confidence masks and morphological post-processing are used to refine label quality.
- Fusion Branch: Combines predictions from the segmentation and warping branches using pixel-wise confidence measures, mitigating error propagation in regions of low reliability.
This multi-branch design ensures both spatial accuracy and temporal consistency in label propagation.
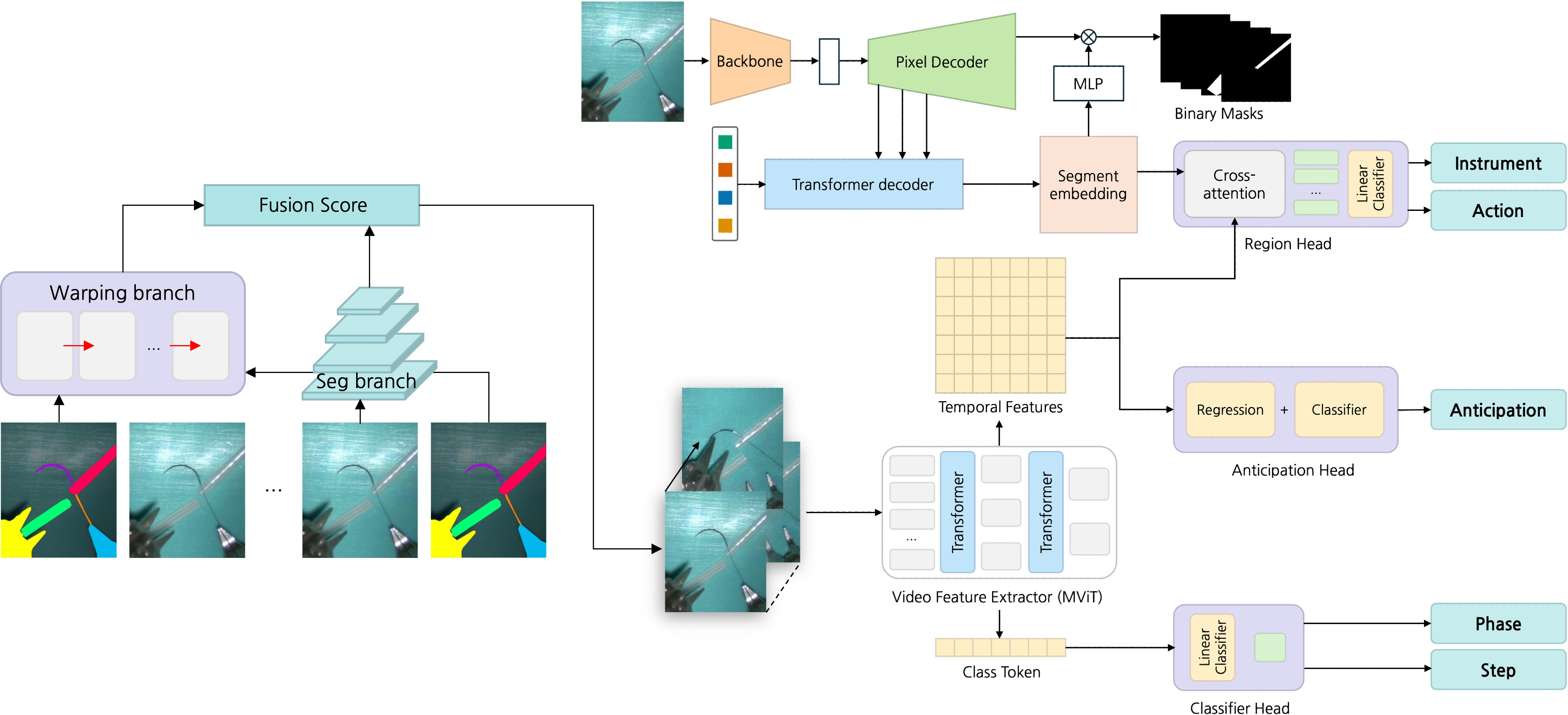
Figure 2: Overview of the SurgMINT framework, showing segmentation label interpolation and multi-task learning for comprehensive surgical video understanding.
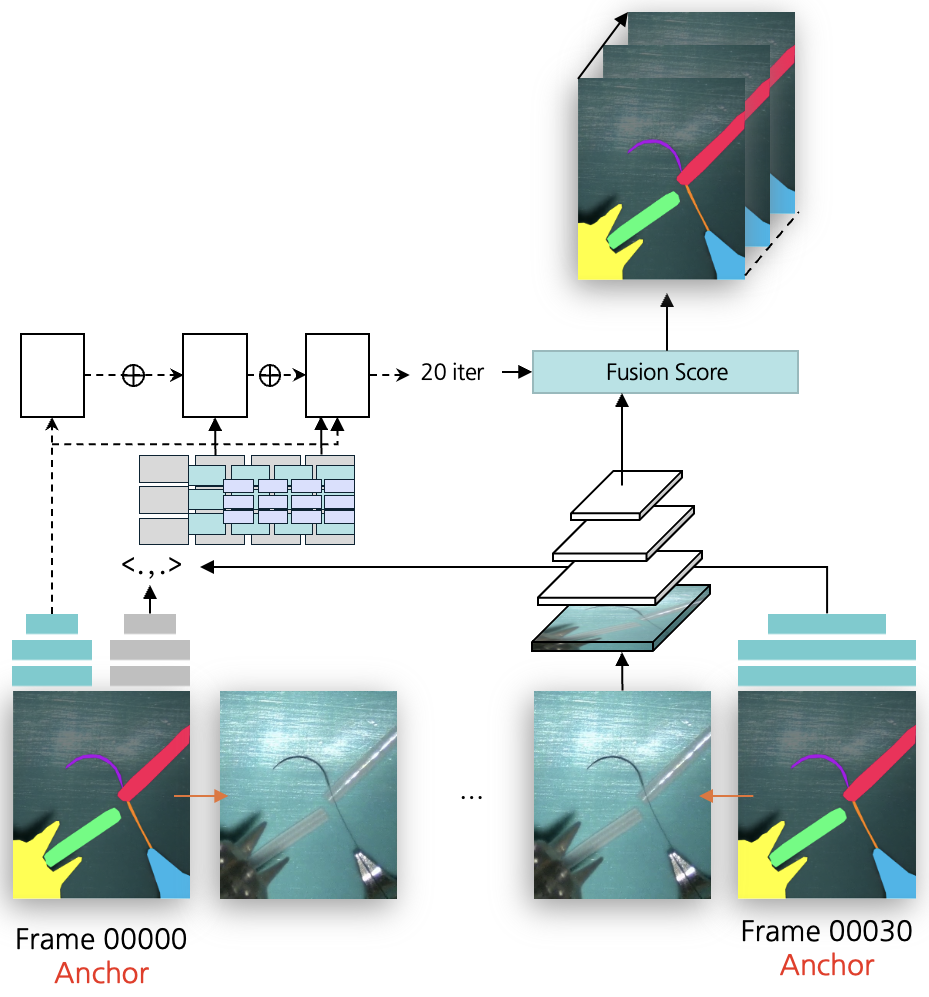
Figure 3: Segmentation label interpolation framework using optical flow, corresponding to the warping branch in SurgMINT.
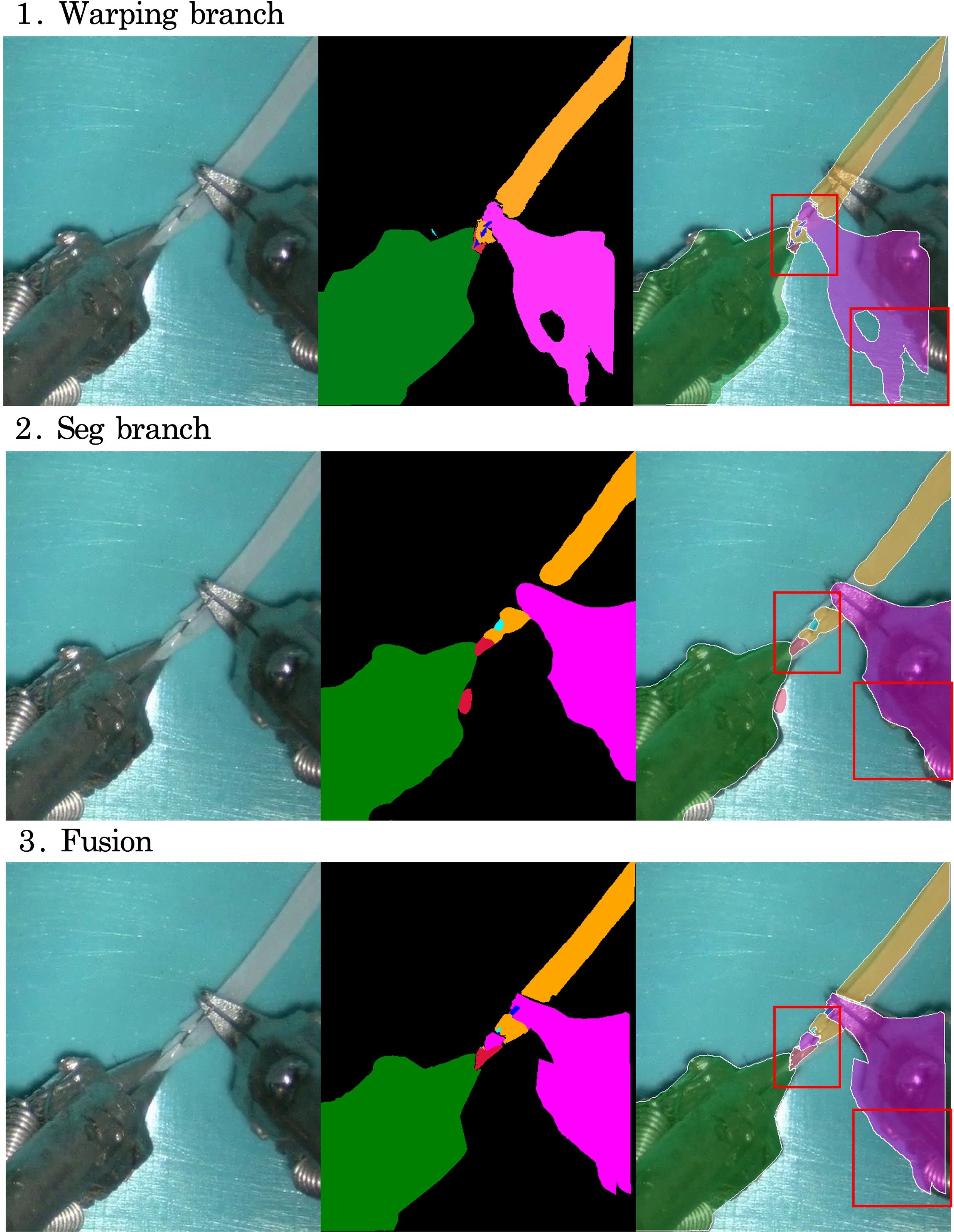
Figure 4: Visualization of intermediate results from each branch during label interpolation, demonstrating the complementary strengths of warping and segmentation.
Multi-Task Learning Architecture
The framework extends the TAPIS baseline by incorporating Mask2Former for instrument segmentation and Multiscale Vision Transformer (MViT) as the shared video backbone. Task-specific heads are attached for:
- Phase/Step Recognition: Classification heads trained with cross-entropy loss.
- Step Anticipation: Dual-branch head for next-step classification and remaining-time regression, optimized jointly.
- Instrument Segmentation/Detection: Region head leveraging segmentation embeddings for cross-attention.
- Action Detection: Trained on key frames with available instrument annotations.
The training process involves initial segmentation model training, followed by joint fine-tuning of all tasks, leveraging interpolated labels for dense supervision.
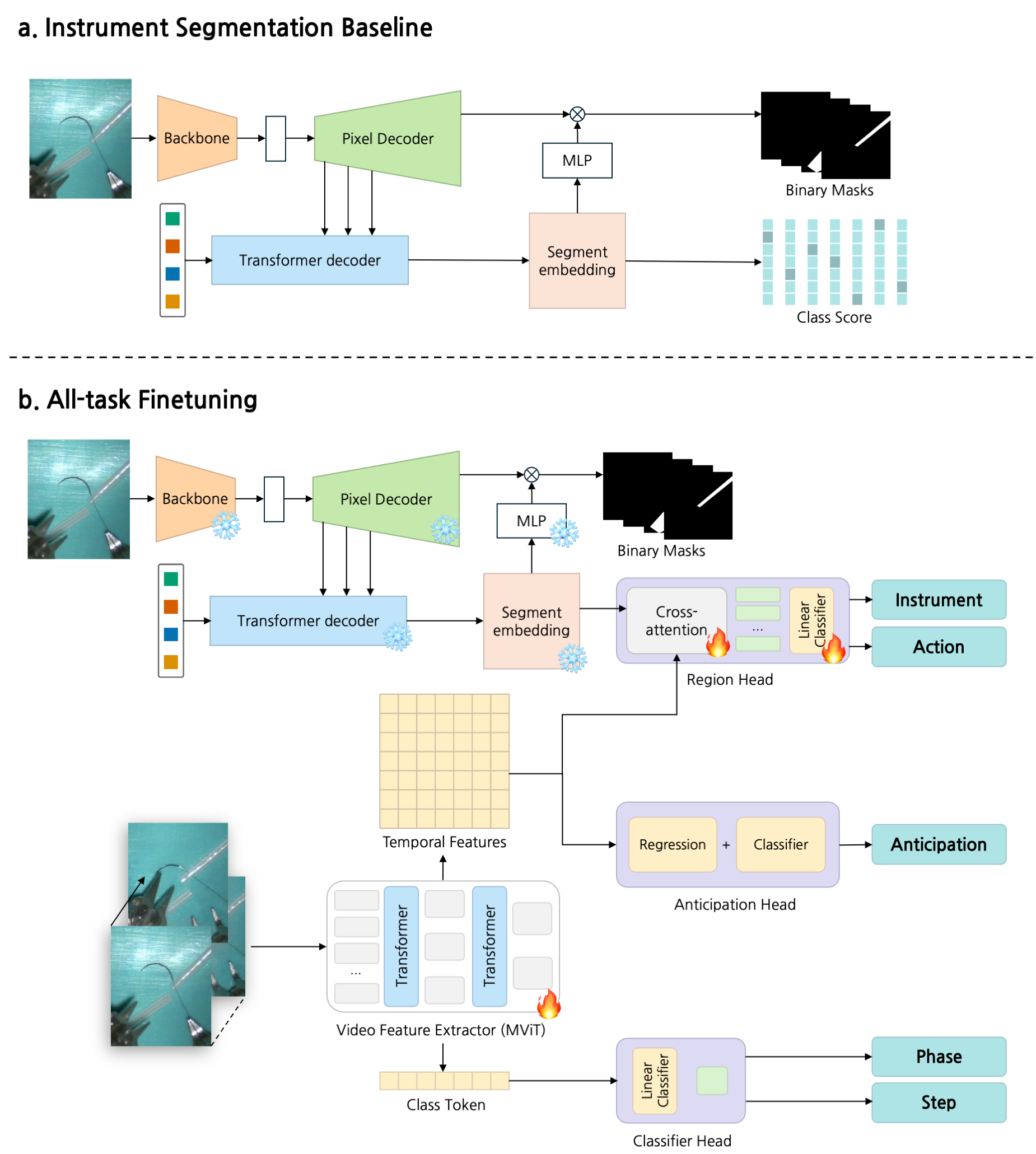
Figure 5: Training process of SurgMINT, illustrating sequential training and joint fine-tuning of all tasks.
Experimental Evaluation
Datasets and Implementation
Experiments are conducted on the MISAW and Cholec80 datasets. MISAW is extended with new instance segmentation annotations for surgical instruments, enabling spatially dense supervision. Cholec80 provides phase and tool presence annotations for step recognition and anticipation.
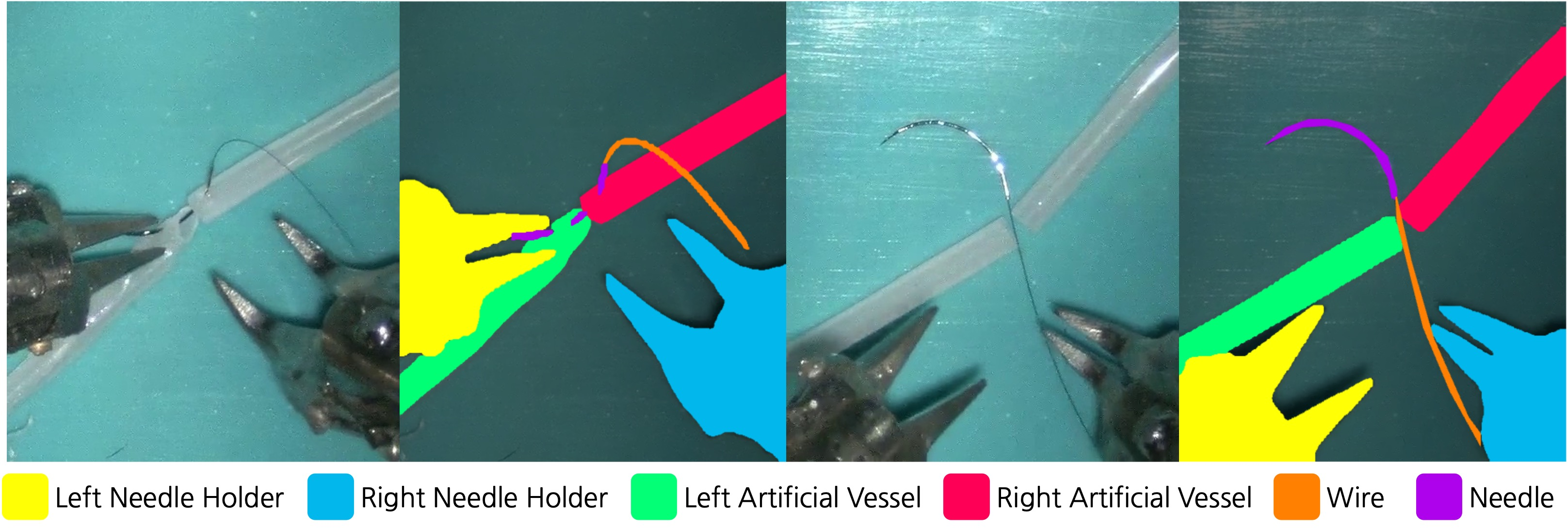
Figure 6: Examples from the MISAW segmentation dataset, showing RGB images and corresponding instrument annotations.
Training is performed in PyTorch on a single RTX A6000 GPU, with batch size 16 and SGD optimizer. Loss weighting is used to balance ground-truth and pseudo-label reliability.
Metrics
- Phase/Step Recognition: mAP, F1-score, Accuracy (1 fps sampling).
- Instrument Segmentation: mAP, mIoU, IoU, mcIoU.
- Action Detection: AVA-style [email protected] IoU for instrument bounding boxes.
- Step Anticipation: MAEin and MAE$_{e}$, measuring prediction error over relevant time horizons.
Results
Multi-Task Learning and Label Interpolation
Joint training of phase, step, and anticipation tasks yields improved F1-scores and lower anticipation error, demonstrating strong semantic and temporal dependencies. However, full multi-task training without label interpolation degrades short-term task performance due to annotation imbalance. The proposed interpolation strategy restores and improves performance, with step mAP increasing from 80.93 (single-task) to 85.61 (multi-task with interpolation), a relative improvement of 5.8%.
Instrument Segmentation
Mask2Former achieves high IoU for large instruments (needle holders: 93.01, 91.11), but performance drops for small/thin objects (wire: 24.70, needle: 28.79), indicating limitations in spatial resolution and annotation quality.
Step Recognition and Anticipation
On Cholec80, multi-task learning outperforms single-task settings for both step recognition (mAP: 84.83 vs. 83.67) and anticipation (MAEin: 1.04 vs. 1.55), confirming the benefit of shared representations for temporally dependent tasks.
Qualitative Analysis
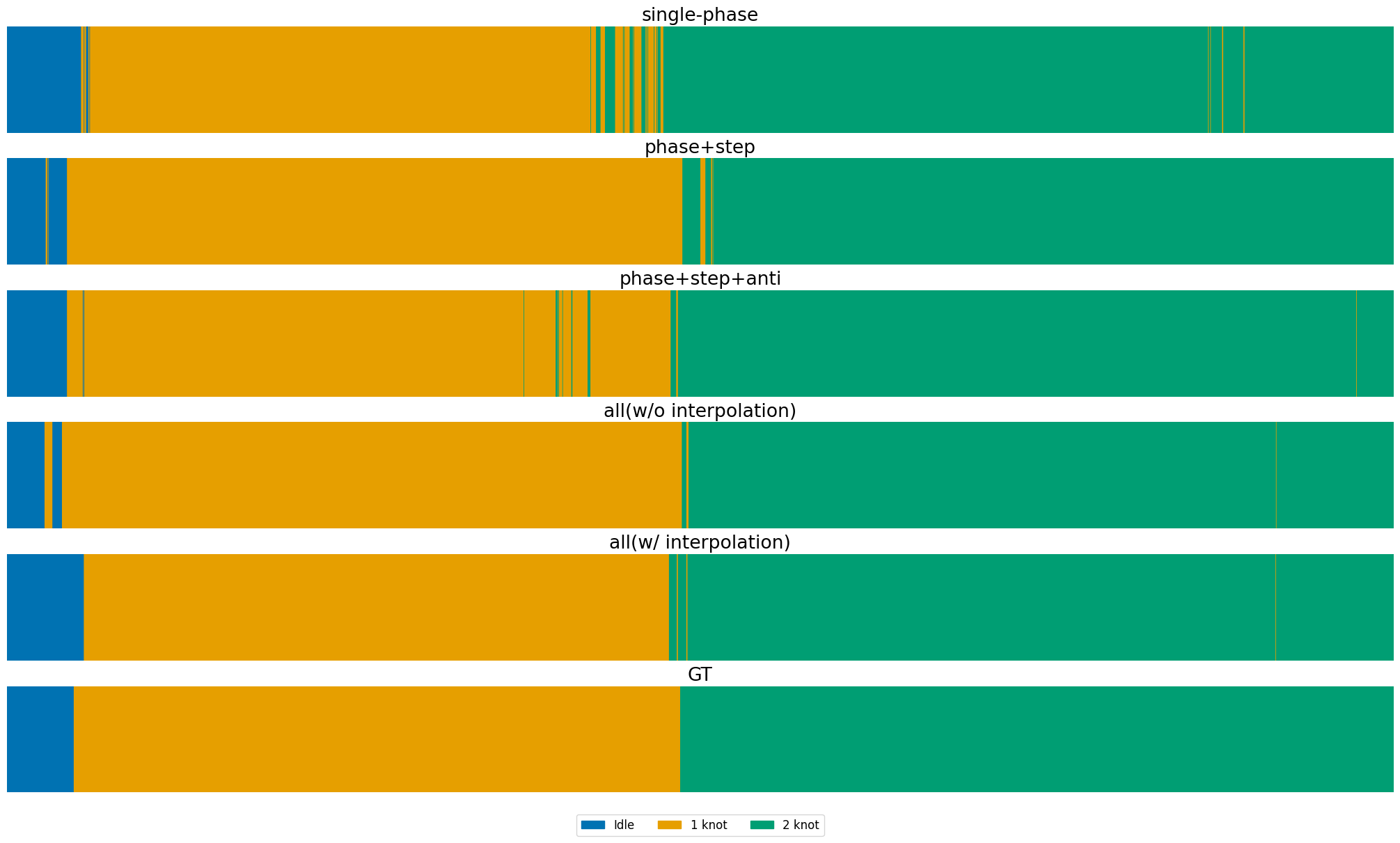
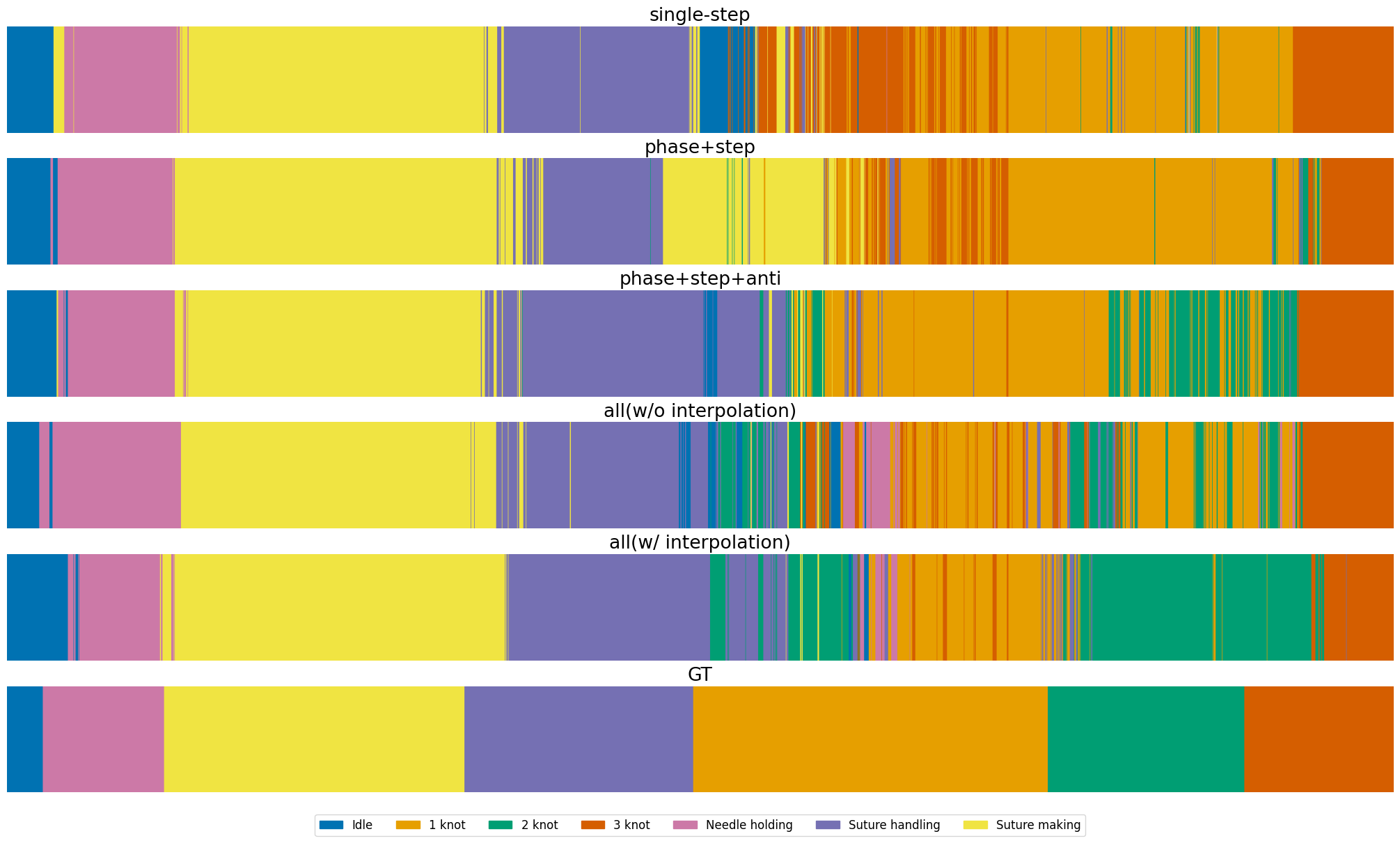
Figure 7: Phase recognition results on MISAW, comparing single-task, multi-task, and multi-task with interpolation against ground truth.
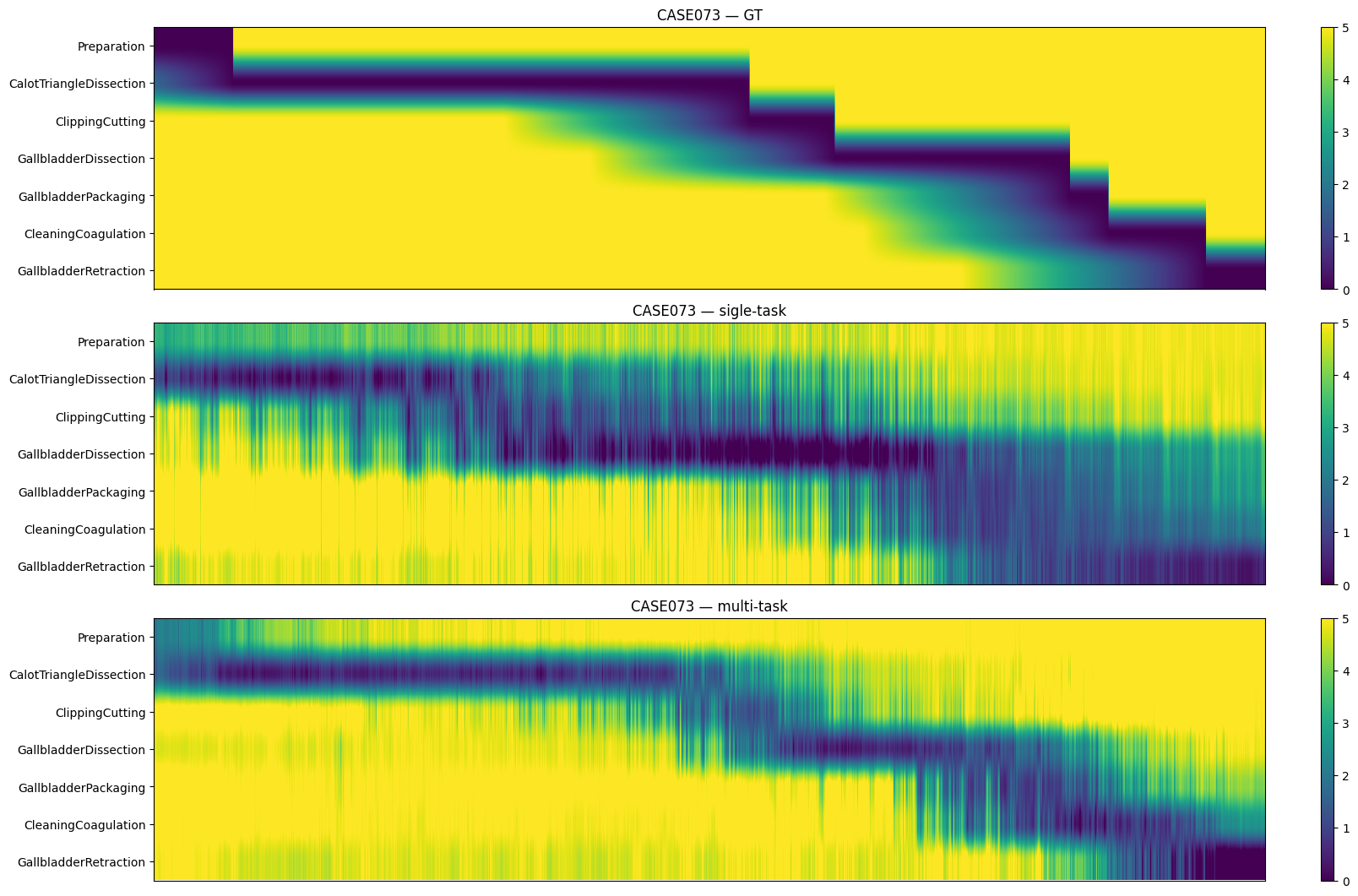
Figure 8: Step anticipation results on Cholec80, visualizing temporal prediction stability across settings.

Figure 9: Instrument segmentation and detection results on MISAW, highlighting improved detection of small instruments in the multi-task setting.
Implications and Future Directions
The integration of label interpolation with multi-task learning addresses a critical bottleneck in surgical video analysis: the annotation imbalance between temporally dense and spatially sparse labels. The approach enables comprehensive modeling of surgical workflows, instrument usage, and anticipatory decision support, which are essential for advancing autonomous and assistive functionalities in RAS.
Theoretical implications include the demonstration that MTL benefits are contingent on balanced supervision across tasks, and that optical flow–based label propagation can effectively densify spatial annotations without significant manual effort. Practically, SurgMINT provides a scalable solution for holistic surgical scene understanding, with potential applications in intraoperative guidance, skill assessment, and automated workflow analysis.
Future research may focus on improving label interpolation for small and occluded objects, integrating uncertainty modeling for pseudo-labels, and extending the framework to additional modalities (e.g., kinematic data, audio). Further exploration of adaptive loss weighting and dynamic task balancing could enhance MTL robustness in highly imbalanced annotation regimes.
Conclusion
SurgMINT offers a unified, scalable framework for surgical video understanding by combining multi-task learning with optical flow–based label interpolation. The method effectively mitigates annotation imbalance, enabling robust modeling of both long-term and short-term surgical tasks. Experimental results demonstrate state-of-the-art performance across multiple datasets and tasks, with qualitative analyses confirming improved alignment with ground truth. The framework lays the foundation for future developments in vision-driven decision support and autonomy in robot-assisted surgery.