- The paper presents a novel zero-shot image classification approach that eliminates the need for labeled training data through confidence-based pseudo-labeling and self-learning cycles.
- It utilizes Vision-Language Models and pre-trained feature extractors like ViT-G-14 to iteratively refine classifier training and improve performance across diverse datasets.
- Experimental results show the framework achieving up to 76.97% average accuracy, surpassing state-of-the-art methods and enabling dynamic adaptation.
Overview of "No Labels Needed: Zero-Shot Image Classification with Collaborative Self-Learning"
The paper presents a novel zero-shot image classification framework that tackles the limitation of requiring extensive labeled datasets. By leveraging Vision-LLMs (VLMs) and pre-trained models, the framework employs a self-learning cycle for pseudo-labeling and classifier training using test data directly, effectively enabling dynamic adaptation to new environments without supervision or labeled datasets.
Introduction
Image classification in deep learning typically relies on large annotated datasets for model training, which poses challenges in scenarios where such data is scarce. Vision-LLMs (VLMs) have emerged as promising tools for zero-shot classification, capable of achieving high accuracy without requiring labeled data. These VLMs use contrastive learning on image-text pairs, as demonstrated by models like CLIP, to embed both images and text into a shared representation space, facilitating tasks such as zero-shot classification.
Despite improvements in zero-shot classification, current methods often depend on LLMs and fine-tuning strategies, limiting their applicability in data-constrained environments. The paper introduces a new framework that circumvents these limitations by using confidence-based pseudo-labeling and self-learning cycles, requiring only class names for training.
Proposed Framework
The framework operates through three distinct steps in its pipeline: Seed Selection, Classifier Training, and Image Classification. Each step leverages different model capabilities for efficient processing.
Step A: Seed Selection
Seed selection identifies high-confidence samples from the test data using CLIP, encoding images and their class names to select the top candidates with high similarity scores. Improved selection further refines this process by using neighborhood consensus among selected candidates, enhancing reliability.
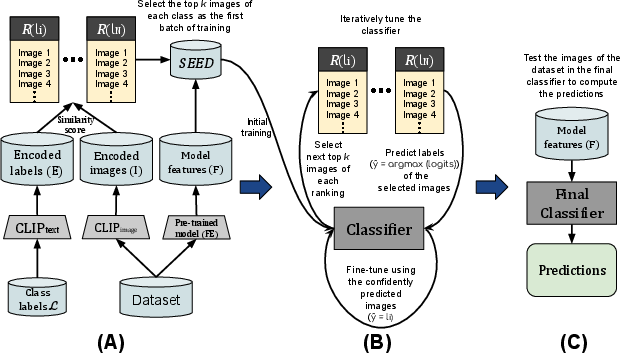
Figure 1: Our approach pipeline is divided into three steps. In (A), we construct the initial training set (SEED) using CLIP and extract features from the images using a pre-trained model. Next (B), we perform a self-learning cycle, incrementally tuning a classifier. In the third step (C), we make the predictions for each image in the dataset using the trained classifier.
Step B: Classifier Training
The selected seed set (high-confidence samples) is used for initial training of a lightweight classifier. This phase employs a pre-trained feature extractor (e.g., ViT-G-14) to generate robust feature vectors for iterative training processes, minimizing overfitting and maintaining adaptability.
Step C: Image Classification
After iterative refinement and self-learning cycles, the trained classifier predicts classes for the entire image dataset using robust feature vectors derived from the feature extractor. The self-learning process allows the framework to dynamically adjust and improve accuracy over successive cycles.
Experimental Results
The paper evaluates performance on ten diverse datasets, demonstrating significant accuracy improvements across all tested backbones and configurations. Notably, the framework achieves an average accuracy of up to 76.97%, surpassing state-of-the-art approaches and baseline models like CLIP.
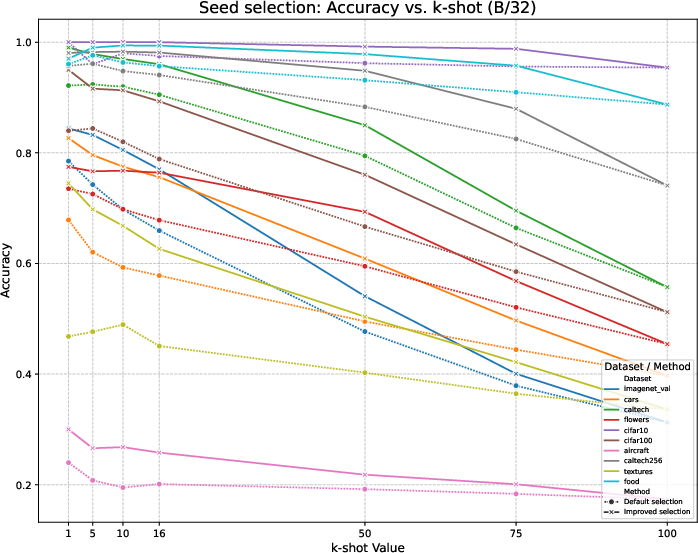
Figure 2: Accuracy of the sample selection (default and improved versions) across the datasets using CLIP B/32 backbone.
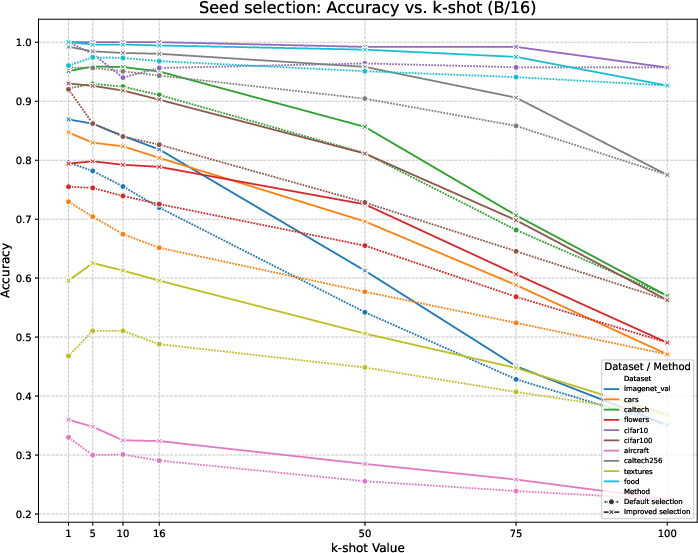
Figure 3: Accuracy of the sample selection (default and improved versions) across the datasets using CLIP B/16 backbone.
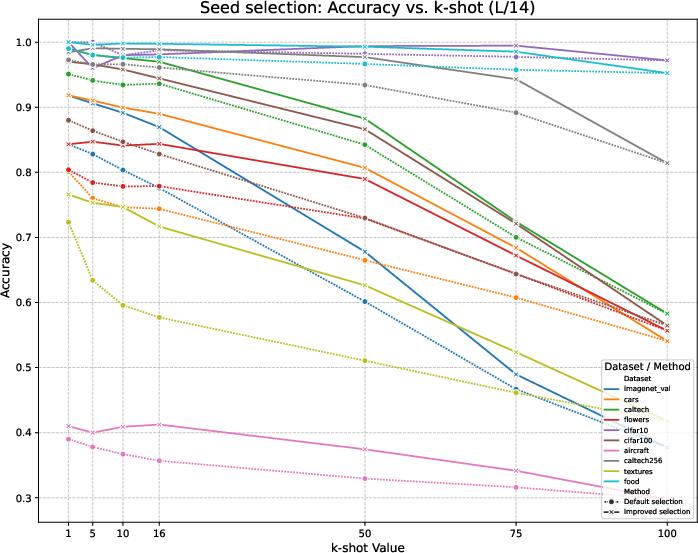
Figure 4: Accuracy of the sample selection (default and improved versions) across the datasets using CLIP L/14 backbone.
The experimental results underscore the efficacy of the collaborative self-learning model, which dynamically refines pseudo-labels and enhances performance without relying on labeled data or extensive fine-tuning, demonstrated by consistent improvements across different datasets and backbones used.
Conclusion
The collaborative self-learning framework introduced in this paper offers a novel method for zero-shot image classification, facilitating enhanced accuracy and adaptability across diverse datasets without heavy reliance on labeled training data or extensive fine-tuning. By decoupling semantic and visual sources of information, the framework achieves efficient transfer learning and unsupervised training capabilities, paving the way for broader applications in resource-constrained settings in the future.

