- The paper demonstrates that Mono-Forward (MF) outperforms backpropagation by achieving up to 41% less energy consumption and 34% faster training on MLPs.
- It rigorously compares three BP-free algorithms—FF, CaFo, and MF—under identical network conditions, revealing significant trade-offs in accuracy, memory usage, and computational cost.
- The study underscores practical implications for sustainable AI by proposing BP-free methods as viable alternatives for energy-efficient and resource-constrained deep learning.
Energy-Efficient Deep Neural Network Training Beyond Backpropagation: A Comparative Analysis of FF, CaFo, and MF Algorithms
Introduction
The paper "Beyond Backpropagation: Exploring Innovative Algorithms for Energy-Efficient Deep Neural Network Training" (2509.19063) presents a rigorous empirical investigation into three backpropagation-free (BP-free) training algorithms—Forward-Forward (FF), Cascaded-Forward (CaFo), and Mono-Forward (MF)—with a focus on their energy efficiency and classification performance relative to standard backpropagation (BP). The study is motivated by the escalating energy demands of deep neural network (DNN) training, the environmental impact of large-scale models, and the limitations of BP, including memory overhead, backward locking, and biological implausibility. The research is distinguished by its methodologically rigorous comparative framework: each algorithm is implemented on its native architecture and compared against a fair BP baseline with identical network structure, systematic hyperparameter optimization, and early stopping based on validation performance.
Theoretical Foundations and Algorithmic Mechanisms
Backpropagation and Its Limitations
BP remains the canonical training algorithm for DNNs, relying on the storage of intermediate activations and sequential forward-backward passes for gradient computation. This results in high memory usage, limited parallelism, and susceptibility to vanishing/exploding gradients. BP's requirement for symmetric weight transport and global error signals is also biologically implausible.
Forward-Forward (FF) Algorithm
FF, introduced by Hinton, eliminates the backward pass by employing two forward passes—one with positive (real) data and one with negative (artificially paired) data. Each layer is trained locally to maximize a "goodness" metric for positive samples and minimize it for negatives. Layer normalization is applied to prevent the propagation of magnitude information. FF is natively designed for MLPs and requires multiple forward passes for inference.
Cascaded-Forward (CaFo) Algorithm
CaFo extends FF by introducing block-wise training in CNNs, with each block followed by a local predictor (auxiliary classifier). Predictors are trained independently, either on randomly initialized blocks (Rand-CE) or blocks pre-trained with Direct Feedback Alignment (DFA-CE). The final prediction aggregates outputs from all predictors. CaFo aims to improve stability and accuracy by providing direct supervisory signals at multiple depths.
Mono-Forward (MF) Algorithm
MF employs local projection matrices in each hidden layer to map activations directly to class-specific goodness scores, optimized via local cross-entropy loss. Both layer weights and projection matrices are updated using gradients from the local loss, avoiding global error propagation and backward locking. MF is natively evaluated on MLPs and supports both FF-style and BP-style inference.
Experimental Methodology
The study implements each algorithm on its native architecture (MLPs for FF and MF, CNNs for CaFo) and constructs fair BP baselines with identical structures. Systematic hyperparameter optimization is performed using Optuna, and early stopping is applied universally. Performance is evaluated on MNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100 datasets. Efficiency metrics include wall-clock training time, energy consumption (NVML API), peak GPU memory, GFLOPs (PyTorch profiler), and estimated CO2e (CodeCarbon).
Empirical Results
Forward-Forward (FF) vs. Backpropagation (BP)
FF achieves competitive accuracy with BP on MLPs for MNIST and Fashion-MNIST but requires dramatically more training epochs, wall-clock time, and energy. Hardware profiling reveals suboptimal GPU utilization and no practical memory savings, refuting theoretical expectations.
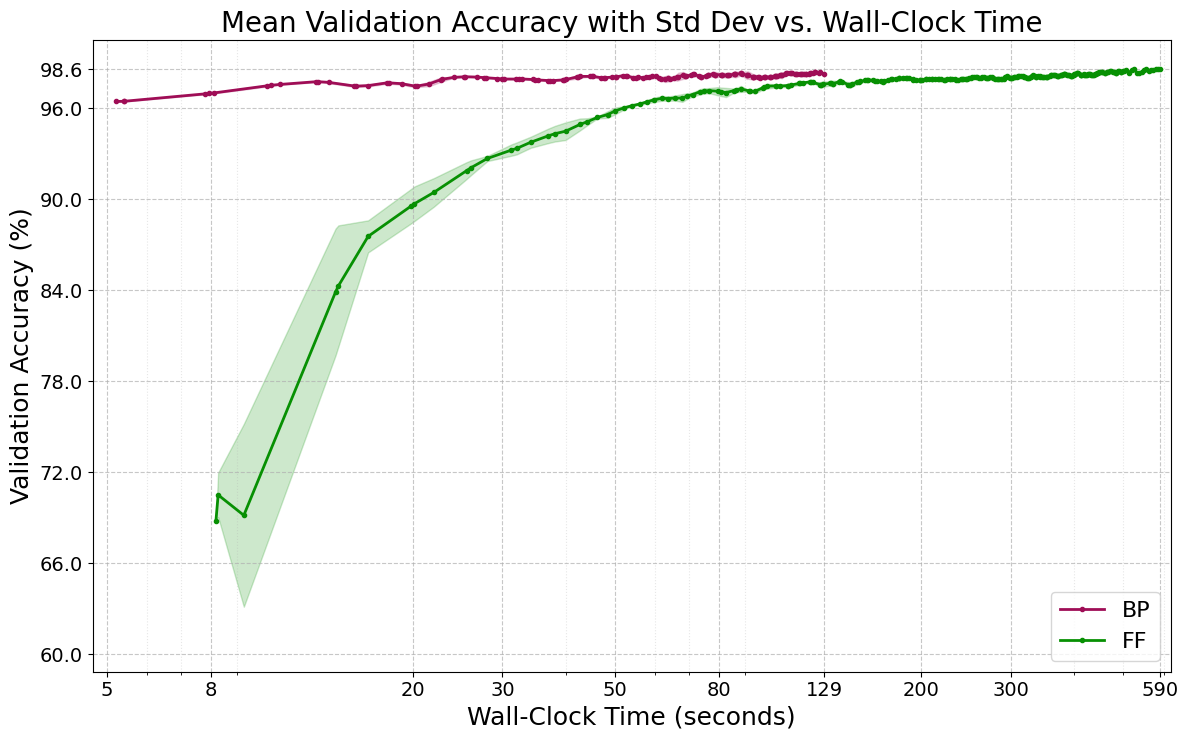
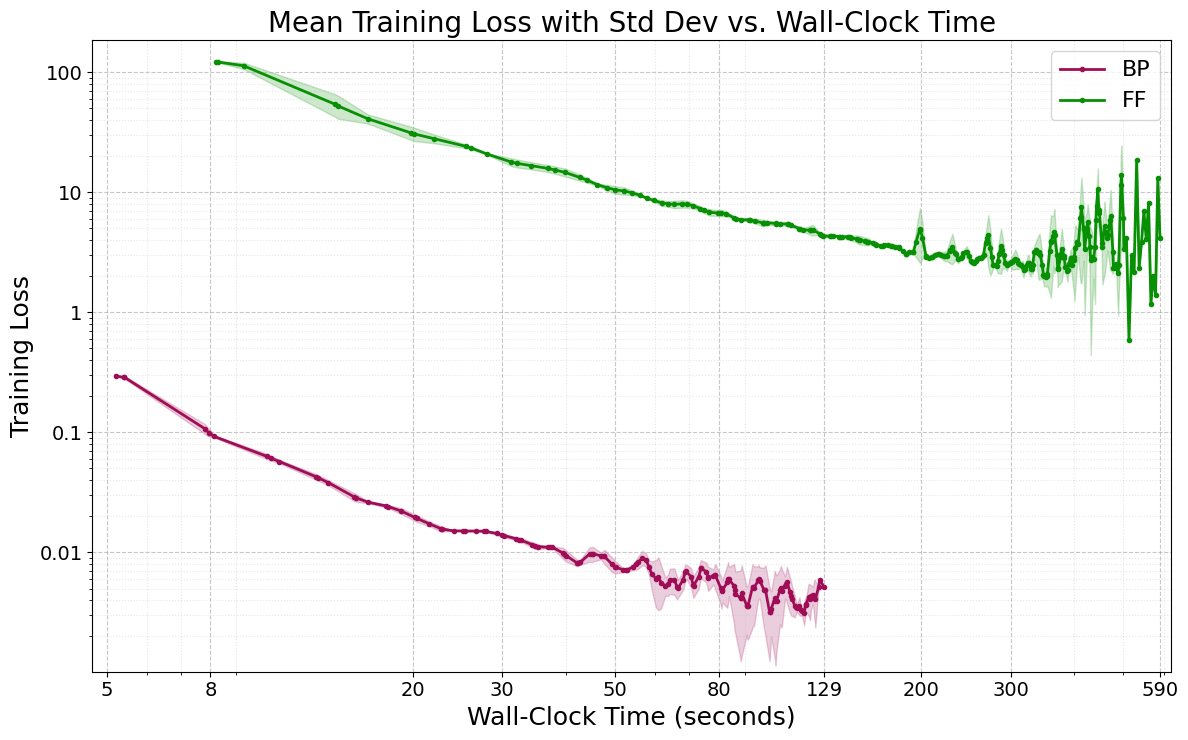
Figure 1: Convergence dynamics for FF and BP on MNIST 4×2000 MLP, showing FF's slow and volatile learning trajectory.
Cascaded-Forward (CaFo) vs. Backpropagation (BP)
CaFo-Rand-CE offers modest memory and energy savings but suffers significant accuracy loss on complex datasets. CaFo-DFA-CE narrows the accuracy gap, even surpassing BP on Fashion-MNIST, but incurs a substantial computational and energy cost due to DFA pre-training. The memory advantage of BP-free methods is not universal; CaFo-DFA-CE can consume more memory than BP due to DFA overhead.
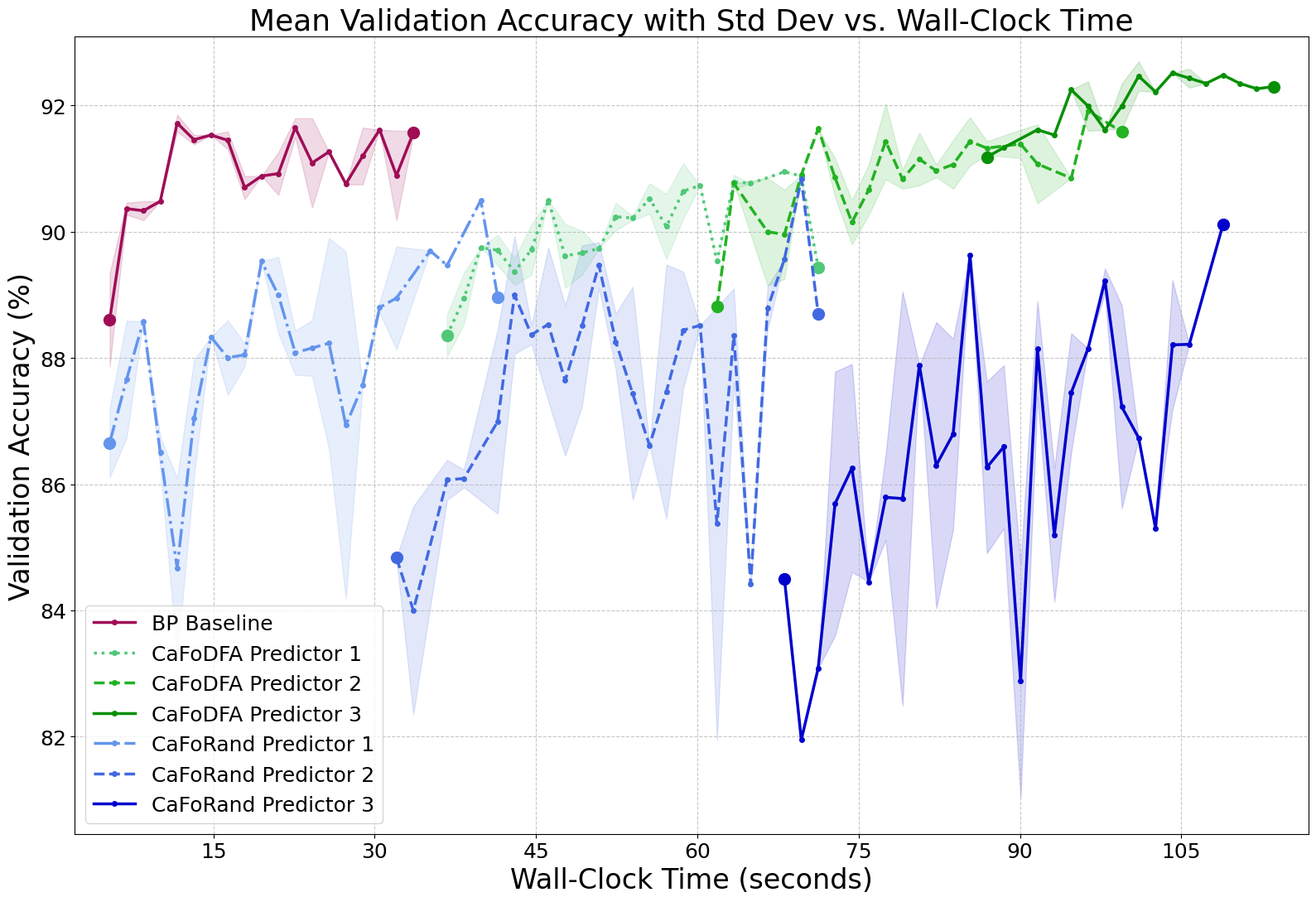
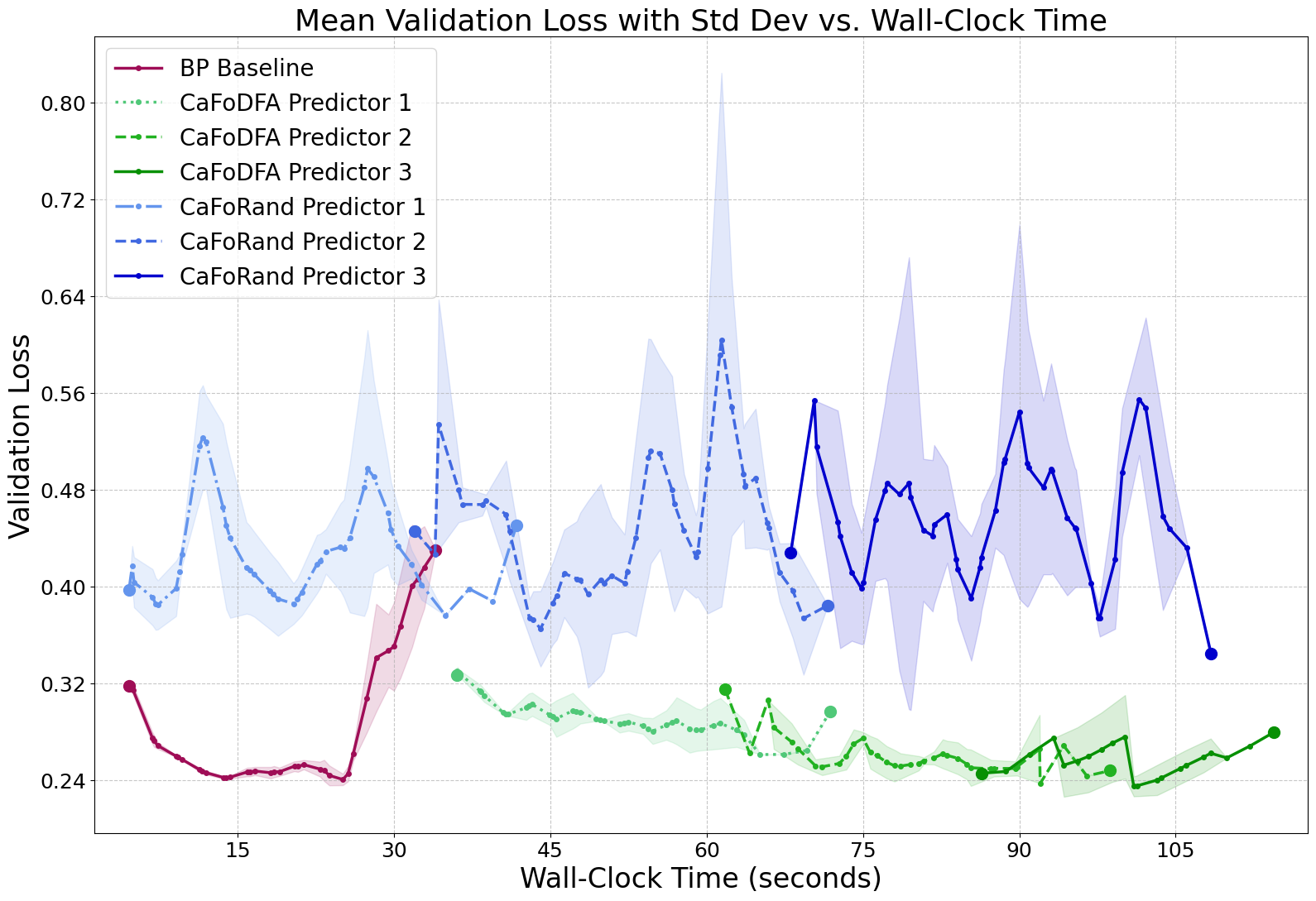
Figure 2: Convergence dynamics for CaFo variants and BP on Fashion-MNIST 3-block CNN, highlighting the trade-off between feature quality and computational cost.
Mono-Forward (MF) vs. Backpropagation (BP)
MF consistently matches or surpasses BP in accuracy on MLPs, with pronounced efficiency gains: up to 41% less energy and 34% faster training on CIFAR-10. MF converges to a lower validation loss than BP, indicating superior generalization. Peak memory savings are modest (4–5%) due to the overhead of projection matrices and optimizer states.
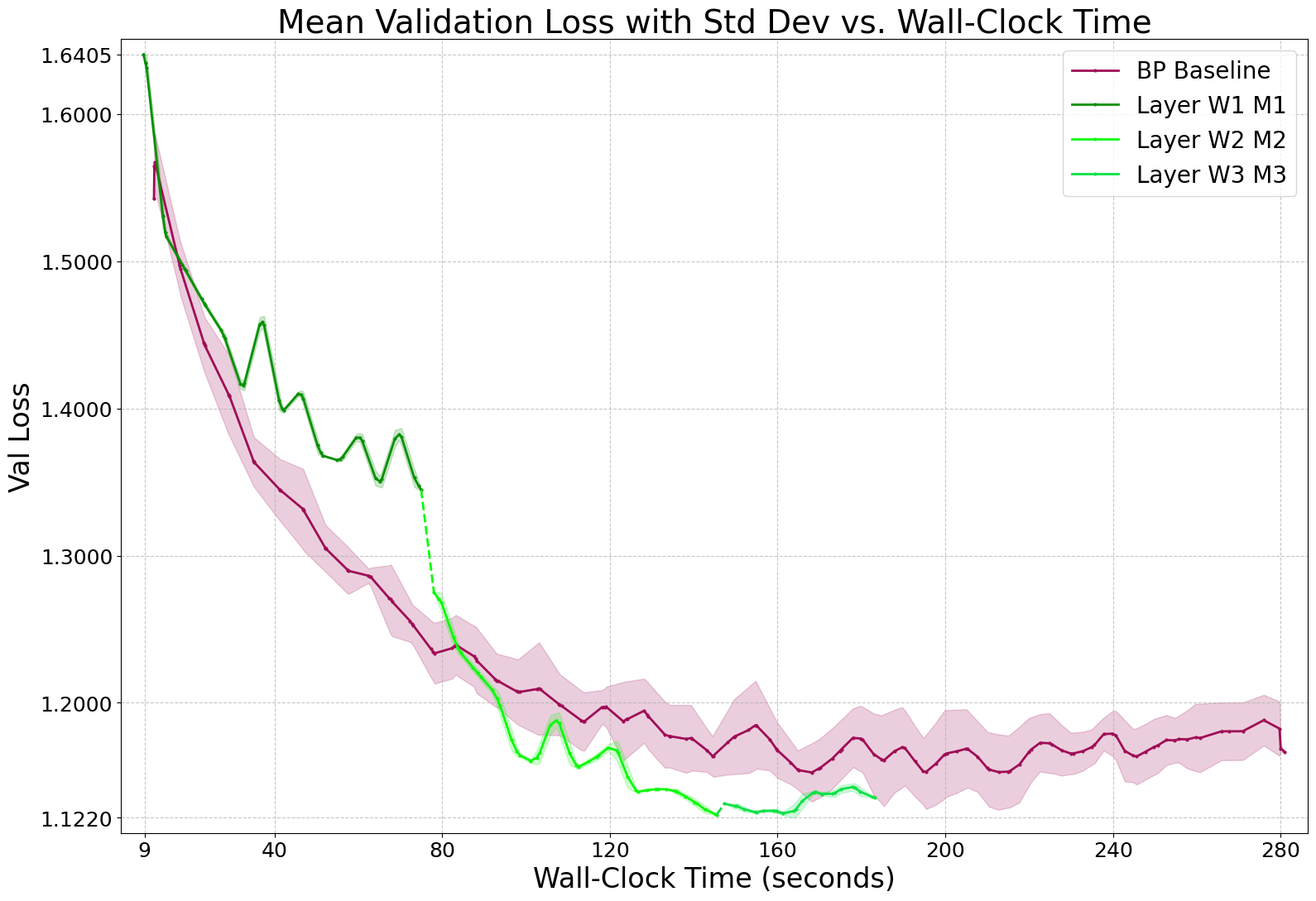
Figure 3: Mean validation loss dynamics for MF vs. BP on CIFAR-10 3×2000 MLP, demonstrating MF's superior convergence.
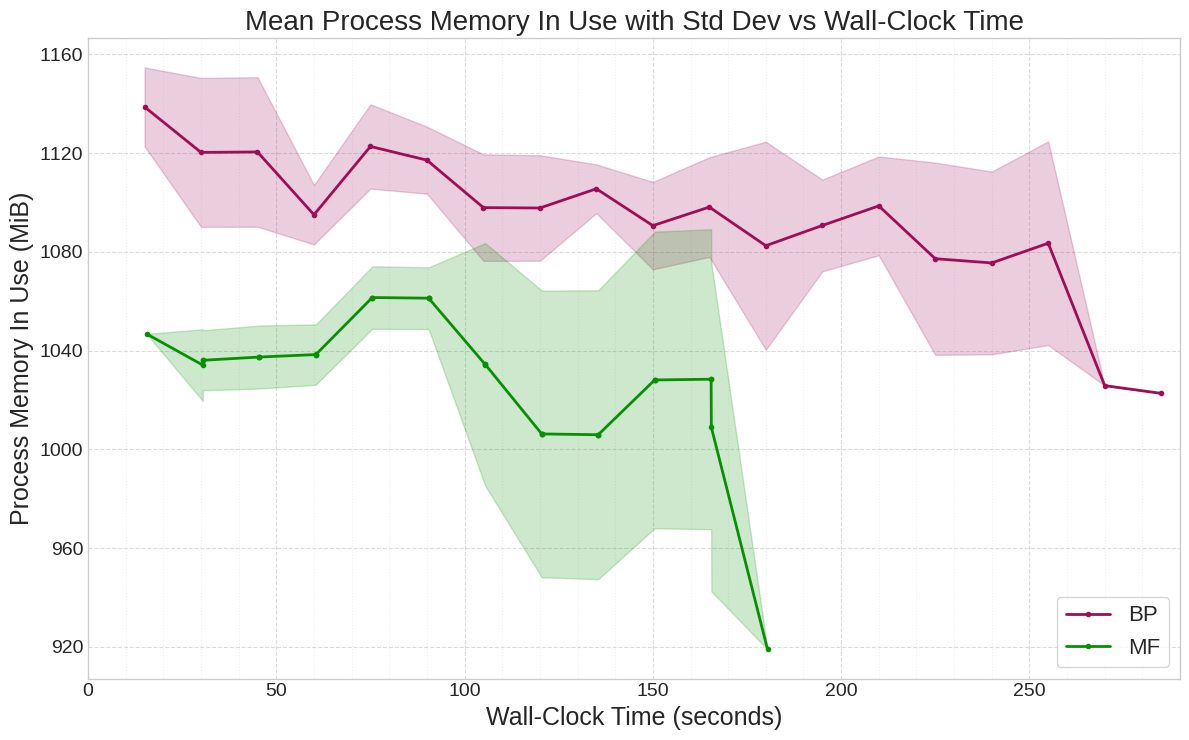
Figure 4: Mean process memory in use for MF vs. BP on CIFAR-10 3×2000 MLP, showing MF's modest memory advantage.
Comparative Synthesis and Trade-offs
A cross-algorithm synthesis reveals:
- FF validates BP-free learning but is prohibitively inefficient.
- CaFo presents a trade-off: Rand-CE offers niche efficiency gains for a substantial accuracy penalty; DFA-CE achieves near-BP accuracy at a prohibitive energy cost.
- MF delivers the most favorable trade-off for MLPs, achieving BP-competitive or superior accuracy with significant reductions in training time and energy consumption.
Practical and Theoretical Implications
The results demonstrate that high-performance learning is achievable with purely local rules, challenging the necessity of global optimization. MF's success suggests that greedy layer-wise optimization can locate more favorable minima in the loss landscape. The findings have direct implications for sustainable AI, enabling energy-efficient training and deployment in resource-constrained environments. The nuanced memory results highlight the importance of empirical measurement over theoretical assumptions.
Limitations and Future Directions
The study is limited to native architectures; MF's performance on CNNs and Transformers remains to be explored. CaFo's DFA-CE variant is computationally intensive, and FF is impractical in its current form. Future research should investigate MF's adaptability to other architectures, scalable evaluation on larger datasets, hardware co-design for BP-free algorithms, and extension to other domains (e.g., generative modeling, RL).
Conclusion
This work provides a rigorous, data-driven roadmap for energy-efficient deep learning, establishing MF as a practical, high-performance, and sustainable alternative to BP for MLPs. The evolutionary progression from FF to CaFo to MF highlights rapid advancements in BP-free learning. The research underscores the necessity of fair benchmarking, direct hardware measurement, and systematic optimization in evaluating novel training algorithms. The broader implications include democratizing AI development, enabling on-device learning, and fostering biologically inspired computation for a more sustainable future.