Measuring AI "Slop" in Text
Abstract: AI "slop" is an increasingly popular term used to describe low-quality AI-generated text, but there is currently no agreed upon definition of this term nor a means to measure its occurrence. In this work, we develop a taxonomy of "slop" through interviews with experts in NLP, writing, and philosophy, and propose a set of interpretable dimensions for its assessment in text. Through span-level annotation, we find that binary "slop" judgments are (somewhat) subjective, but such determinations nonetheless correlate with latent dimensions such as coherence and relevance. Our framework can be used to evaluate AI-generated text in both detection and binary preference tasks, potentially offering new insights into the linguistic and stylistic factors that contribute to quality judgments.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tries to make sense of a new buzzword: “AI slop.” People use it to describe writing that looks like it came from an AI and feels low‑quality—too vague, too repetitive, too long, or even wrong. The problem is, no one agrees on exactly what “slop” means or how to measure it. This paper builds a simple, human-friendly checklist for spotting slop in text and tests whether people and computers can use it to find slop reliably.
The big questions the authors asked
- What exactly makes a piece of writing feel like “AI slop”?
- Can we break “slop” into clear parts (like a report card for writing)?
- When experts read the same text, do they agree on where the slop is?
- Do common automatic tools—or even advanced AIs—do a good job at finding slop?
- Do the most important “slop signals” change depending on the task (like news vs. short Q&A answers)?
How they studied it
First, they talked to 19 experts (writers, journalists, linguists, philosophers, and NLP researchers) to build a plain-English “slop” checklist (a taxonomy). Think of it like three big buckets with specific items inside:
- Information Utility: Is the content useful and on-topic?
- Density: Is there enough real substance, or lots of fluff?
- Relevance: Is it actually answering the question or fitting the task?
- Information Quality: Is the content true and fair?
- Factuality: Are the facts correct, or are there errors/hallucinations?
- Bias/Subjectivity: Is the tone appropriately neutral or clearly, needlessly biased?
- Style Quality: Is the writing readable and well-formed?
- Structure: Repetition and templated patterns
- Coherence: Does it flow logically?
- Tone, Fluency, Verbosity, Word Complexity
Then they tested the checklist by asking professional copy-editors to annotate two kinds of text:
- News articles: human-written, AI-written, and “humanized” AI-written versions of the same stories.
- Q&A answers (short responses to real user questions).
The annotators did two things:
- First, they gave a quick overall judgment: “Does this feel like slop?”
- Then, they highlighted exact parts (spans) of the text that show specific “slop” issues (like “off-topic” or “repetitive”).
They also checked how much annotators agreed with each other (which is hard because “slop” is subjective). Finally, they tried:
- Simple statistical modeling to see which checklist items best predict “this is slop.”
- Standard automatic text metrics (like measuring repetition or reading level).
- LLMs asked to judge slop directly.
- A smaller model trained specifically to extract “slop spans.”
What they found (in plain terms)
Overall patterns:
- People don’t always agree on a simple yes/no “this is slop.” That judgment is somewhat subjective.
- But they do overlap a lot on the actual problem spots in the text. In other words, even if they disagree about “slop overall,” they often highlight many of the same weak parts.
- Their checklist works: more highlighted issues → more likely the text is judged as “slop.”
Which issues mattered most?
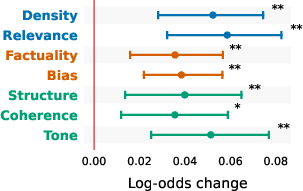
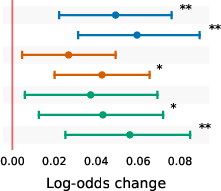
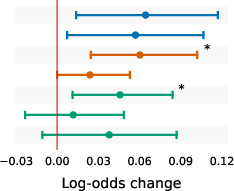
- Across everything, three signals were especially strong: being off-topic (low relevance), low information density (too much fluff), and awkward or mismatched tone/style.
- The important signals change by task:
- News articles: style and usefulness matter most. Being off-topic, fluffy, incoherent, biased, or tonally weird makes news feel “sloppy.”
- Short Q&A answers: facts and structure matter most. Wrong info or messy structure stands out immediately because answers are short.
Can automatic tools find slop well?
- Basic metrics (like counting repeated words, reading level, or length) catch a little signal but not enough. They miss human judgments about usefulness, coherence, and relevance.
- A writing-quality reward model (trained elsewhere) somewhat lined up with slop, but the correlation was only modest.
- When asked directly to judge slop, advanced LLMs did poorly. They often failed to call out slop that humans saw, and they missed many of the highlighted problem spans.
- Training a smaller model to extract slop spans helped a bit (better than zero-shot prompting), but it still missed many issues. Finding slop precisely is hard.
Why that’s important:
- A simple yes/no detector for AI text is not the same as judging “sloppiness.”
- The checklist makes judgments more explainable: instead of “this is bad,” you can say “it’s off-topic, repetitive, and low on real info.”
Why this matters
- For everyday users: It helps explain why some AI answers feel unhelpful—too general, off-topic, wordy, or even wrong.
- For teachers, editors, and platforms: It offers a clear, shared language to give feedback (“reduce fluff,” “fix coherence,” “check facts”) rather than vague comments.
- For AI builders: It shows what today’s metrics and models miss, and points to where better tools are needed—especially for relevance, coherence, tone, and factuality without reference answers.
- For society: Since lots of people use AI for writing and information, having a practical way to spot and reduce “slop” can improve the quality of what we read online.
In short: The paper turns a vague insult (“AI slop”) into a usable checklist. It shows which flaws matter most in different settings, proves that people can reliably point to problem spots, and warns that current automatic tools—especially LLMs judging other LLMs—aren’t yet good enough to replace careful human evaluation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper and where future research could concretely build.
- Definition and scoring: No validated composite “slop score” exists (weights, aggregation, domain cutoffs); no psychometric validation (e.g., factor analysis, reliability, construct/convergent validity) of the proposed taxonomy.
- Subjectivity and reliability: Binary “slop” labels show low agreement; cognitively demanding codes (relevance, coherence, density) remain unstable; intra-annotator reliability was not reported; it is unclear how much further training/guidelines can reduce subjectivity.
- Annotator effects: Analyses aggregate labels without modeling annotator random effects; mixed-effects or hierarchical models to disentangle item-, domain-, and annotator-level variance are missing.
- Span severity and aggregation: All span issues are implicitly treated equally; there is no severity/impact scaling or principled method for aggregating multi-label spans into document-level judgments.
- Dataset scope: Evaluation is limited to English news and short QA (MS MARCO); coverage of other high-incidence settings (SEO articles, web forums, customer support, educational content, instructions, creative writing, technical docs, emails, code comments) is missing.
- Model coverage and drift: Experiments cover a limited set of models at one point in time; how the taxonomy holds under newer frontier models and temporal drift in LLM behaviors is unknown.
- Human vs. AI “slop”: The framework does not explicitly quantify or contrast “slop” incidence/severity in human-written vs. AI-written text under controlled conditions; misclassification and overlap remain unmeasured.
- Domain transferability: Domain differences are observed but not systematically modeled; no domain-specific scoring rules or calibration procedures are proposed.
- Automatic metric gaps: Key axes (relevance, coherence, fluency, tone) lack robust, validated automatic measures; the paper does not introduce new metrics for these dimensions.
- Factuality without references: No exploration of retrieval- or evidence-based factuality checks (e.g., claim verification against web/evidence) for reference-free settings; feasibility and reliability remain open.
- Bias/subjectivity: Bias measurement relies on lexicon-based subjectivity, which is simplistic; distinguishing necessary from inappropriate subjectivity and contextual framing is unresolved.
- Metric validation: The mapping from codes to automatic metrics is not empirically validated per code; correlations/ablations between code-level annotations and metric outputs are not reported.
- Modeling approach: Only linear models are tested; potential gains from discourse/entity-grid coherence models, NLI-based contradiction checks, redundancy detection, semantic coverage measures, and representation learning are unexplored.
- Reward models: No slop-specific reward model or preference model is trained; whether slop-aware RMs predict human preferences or improve generation quality is untested.
- LLMs-as-judges: Judge prompting is limited; effects of judge calibration, rubric-tuned evaluators, multi-pass deliberation, uncertainty quantification, or learning-to-judge approaches are unknown.
- Span extraction: The trained extractor achieves modest partial overlap; per-code performance, boundary uncertainty modeling, and sequence tagging architectures specialized for multi-label, multi-span extraction remain to be explored; evaluation metrics for this setting could be improved and standardized.
- Data efficiency: Span-level annotation is costly; active learning, weak supervision, silver-to-gold bootstrapping, or semi-automated pipelines to scale annotations are not investigated.
- Causal mitigation: The paper does not test interventions to reduce slop (e.g., decoding strategies, prompt design, stylistic constraints, post-editing with taxonomy feedback); it remains unknown which levers most effectively decrease slop across domains.
- External validity: No link is established between slop scores and user outcomes (task success, trust, satisfaction, time-to-understanding) or A/B human preferences; predictive value for practical evaluation is unquantified.
- Confounding controls: Analyses do not control for length, topic, source, or model family; causal attributions (e.g., verbosity vs. density) are therefore uncertain.
- Humanized outputs: The “humanized” AI articles are included but not analyzed for which slop axes are reduced or persist, nor for which interventions are effective.
- Taxonomy structure: Independence among axes is assumed but untested; latent structure (e.g., correlated clusters) has not been examined via exploratory/confirmatory factor analysis.
- Cross-lingual and multimodal: Generalization to other languages and multimodal outputs (vision+text) is unaddressed, despite likely differences in “slop” markers.
- Reproducibility: Use of proprietary LLMs (e.g., GPT-5) for judging/extraction limits reproducibility; sensitivity of results to model or prompt changes is not characterized.
- Relationship to AI-detection: The correlation between “slop” and AI-text detection scores (e.g., DetectGPT, Binoculars) is not measured; whether “slop” is orthogonal to AI-likelihood remains open.
Practical Applications
Overview
This paper proposes a practical, interpretable taxonomy for assessing “AI slop” in text along three axes—Information Utility (density, relevance), Information Quality (factuality, bias), and Style Quality (structure, coherence, tone/fluency/verbosity/word complexity)—validated via span-level expert annotations over news and retrieval-augmented QA. It shows which latent dimensions most strongly predict human “slop” judgments by domain, maps several codes to existing automatic metrics, and demonstrates that current automated tools and LLM-as-judges fall short of capturing slop without human-in-the-loop assessment. The authors release guidelines and data to support adoption.
Below are actionable applications derived from the findings, methods, and innovations, grouped by deployment horizon.
Immediate Applications
Use these when human-in-the-loop review is feasible and when partial automatic measurement (e.g., repetition, verbosity, word complexity) suffices.
- Bold: Editorial QA “Slop Filter” for publishers and newsrooms (Sector: media)
- Use the taxonomy and span-level marking to triage articles for density, relevance, coherence, tone, and templated structure before publication; prioritize the strongest predictors (density, relevance, tone) identified for news.
- Tools/workflows: an editor plugin that overlays “slop spans” (heatmap), checklist based on the released guidelines, batch scoring for repetitive structure and verbosity.
- Assumptions/dependencies: domain calibration for news; human oversight for relevance/coherence; acceptance of subjective judgments; integration into CMS.
- Bold: RAG answer quality gate (Sector: software; customer support; healthcare knowledge bases)
- Apply slop checks (especially factuality and structure, which are most predictive for QA) to RAG outputs before serving answers.
- Tools/workflows: post-generation validator that flags low density, off-topic content, or templated phrasing; routes flagged items to human review; logs slop patterns for prompt and retrieval tuning.
- Assumptions/dependencies: access to retrieved sources; human fact-check for non-reference contexts; latency acceptable for review.
- Bold: SEO quality screening to de-rank low-utility AI content (Sector: search/ads/marketing)
- Use information density and relevance markers (plus repetition/templatedness) to flag thin or generic AI content from content farms.
- Tools/workflows: “SlopScore” with automatic metrics (compression ratios, word complexity) and spot human audits; integrate into ranking pipelines.
- Assumptions/dependencies: risk of Goodhart’s law (content gaming); domain-specific thresholds; false-positive mitigation.
- Bold: “Anti-Slop Linter” for enterprise and personal writing (Sector: productivity; education)
- A writing assistant that flags verbosity, low density, repeated templates, and tonal mismatches; suggests span-level edits using the taxonomy.
- Tools/workflows: Word/Docs plugin; inline highlights and quick fixes; rubric-based feedback aligned with the paper’s codes.
- Assumptions/dependencies: reliable automatic metrics only for certain axes; user acceptance of critiques; option to request human review for coherence/relevance.
- Bold: Content moderation and marketplace quality assurance (Sector: platforms; freelancing)
- Screen submissions (blog posts, product descriptions, proposals) for slop indicators; require remediation or provide feedback.
- Tools/workflows: intake screening with automatic style checks; human secondary review; standardized feedback templates.
- Assumptions/dependencies: transparent policies; fairness audits; appeal processes.
- Bold: Training data curation for LLM development (Sector: AI model development)
- Filter corpora to reduce low-density, highly templated, verbose text; prioritize diverse, coherent, relevant samples.
- Tools/workflows: pretraining data filters using style metrics; sampling strategies to increase information utility.
- Assumptions/dependencies: scaling filters to web-scale data; balance to preserve diversity; guard against introducing bias.
- Bold: Reward-model feature design (Sector: AI alignment/evaluation)
- Use the taxonomy to define human-labeled axes (relevance, coherence, tone) that current automatic metrics miss; penalize slop spans during RLHF.
- Tools/workflows: small, high-quality labeled datasets; multi-axis preference collection; model ablation to avoid over-weighting superficial cues.
- Assumptions/dependencies: budget for annotation; consistency in subjective labels; preventing overfitting to heuristics.
- Bold: Educational rubrics and tutoring (Sector: education)
- Teach students to improve density, relevance, and coherence; use span-level feedback to show where prose becomes generic or off-topic.
- Tools/workflows: writing rubrics aligned to the taxonomy; exercise sets with annotated exemplars; classroom “slop audits.”
- Assumptions/dependencies: adapt rubrics by genre (essays vs. reports); avoid prescriptive style that stifles creativity.
- Bold: Customer support and knowledge base upkeep (Sector: software; e-commerce)
- Periodic audits of macros/FAQ entries for templatedness, verbosity, and low utility; prune or rewrite flagged content.
- Tools/workflows: quarterly quality scans; “rewrite queue” driven by slop scores; A/B testing of revised content.
- Assumptions/dependencies: change management for teams; measurement of downstream impact (resolution rates, CSAT).
- Bold: Public-sector communications hygiene (Sector: policy/government)
- Pre-release checks of public notices and advisories for clarity (density), relevance, and word complexity to improve accessibility.
- Tools/workflows: “Plain language” pass tied to Gunning-Fog/Flesch-Kincaid and slop taxonomy; human review for coherence/tone.
- Assumptions/dependencies: policy buy-in; accessibility standards; translator workflows for multilingual contexts.
Long-Term Applications
These require further research, scaling, standardization, or robust automation of latent axes (relevance/coherence/tone).
- Bold: Standardized “Slop Index” and benchmarks (Sector: academia; industry consortia; policy)
- Create an open benchmark and composite index across domains; publish reference thresholds for genre-specific use.
- Tools/products: SlopBench; annual reports; interoperability specs for metrics and labels.
- Assumptions/dependencies: community governance; domain stratification; avoiding metric gaming.
- Bold: High-accuracy slop detectors and editors (Sector: software; AI tooling)
- Train domain-specific detectors that reliably capture relevance, coherence, and tone; pair with “de-slopify” editors that propose targeted revisions.
- Tools/products: fine-tuned span extractors; suggestion engines; human-in-the-loop review queues.
- Assumptions/dependencies: larger, diverse labeled datasets; evaluation protocols beyond AUPRC; careful human calibration.
- Bold: Slop-aware search ranking and ad quality controls (Sector: search/ads)
- Incorporate slop signals into ranking, crawl prioritization, and ad review; demote content with low utility or templated structure.
- Tools/products: ranking features; auditor dashboards; publisher feedback APIs.
- Assumptions/dependencies: legal and policy considerations; transparency; robust appeal mechanisms.
- Bold: RLHF and generation training with slop penalties (Sector: AI model development)
- Integrate slop axes into training objectives to reduce verbosity, increase density and relevance, and improve coherence across domains.
- Tools/workflows: multi-objective RL; curriculum learning with anti-slop exemplars; inference-time self-checks.
- Assumptions/dependencies: balancing trade-offs (conciseness vs. completeness); genre-specific norms; avoiding over-sanitization.
- Bold: Sector-specific taxonomies and compliance (Sector: healthcare, finance, legal)
- Extend the taxonomy with domain rules (e.g., medical relevance/factuality under clinical standards; financial compliance and tone constraints).
- Tools/products: regulatory checklists; audit services; domain reward models.
- Assumptions/dependencies: expert involvement; alignment to regulation; liability considerations.
- Bold: Provenance, labeling, and consumer protection policy (Sector: policy/regulation)
- Pair slop assessments with provenance signals (watermarks, signatures); mandate quality checks for AI-generated public-facing content.
- Tools/products: certification schemes; disclosure standards; oversight bodies.
- Assumptions/dependencies: technical feasibility of provenance; international harmonization; avoiding chilling effects.
- Bold: Workforce training and quality SLAs for AI writing (Sector: enterprise operations)
- Define service-level agreements for AI-assisted writing; train staff to recognize and remediate slop; monitor quality KPIs.
- Tools/workflows: dashboards; recurrent training; continuous quality audits.
- Assumptions/dependencies: organizational buy-in; cost-benefit evidence; integration with existing review cycles.
- Bold: Adaptive “quality guards” for RAG systems (Sector: software; knowledge management)
- Slop-aware retrieval and generation loops that automatically re-query or re-compose when answers fail utility or coherence thresholds.
- Tools/workflows: dynamic retrieval policies; feedback loops; confidence gating.
- Assumptions/dependencies: robust detection of latent axes; acceptable latency; careful UX.
- Bold: Cross-lingual and accessibility expansions (Sector: education; public services)
- Extend the taxonomy and metrics to other languages and audiences (plain language, neurodiversity-aware style).
- Tools/workflows: multilingual lexicons; culturally sensitive tone checks; adjustable reading-level targets.
- Assumptions/dependencies: localized annotations; linguistic diversity; equity and inclusion safeguards.
- Bold: Continuous content governance for platforms (Sector: social media; UGC platforms)
- Platform-wide monitoring of slop trends to reduce generic, low-value AI content and promote diverse, human-centered contributions.
- Tools/workflows: periodic ecosystem reports; creator guidance; incentive realignment.
- Assumptions/dependencies: balance between moderation and creativity; transparency with users; fairness audits.
Notes on Feasibility and Dependencies
- Subjectivity and domain variance: Relevance, coherence, and tone require human judgment and domain calibration; thresholds should be genre-specific.
- Data and labels: Progress depends on high-quality, diverse, span-level annotations and robust agreement protocols; released guidelines/data can bootstrap adoption.
- Metric gaming risks: Over-reliance on surface metrics (e.g., verbosity, word complexity) can be gamed; maintain human oversight and multi-axis evaluation.
- Fairness and governance: Use equitable policies to avoid disproportionate impacts on certain creators or styles; provide appeals and transparency.
- Integration costs: Editorial and operational workflows need phased adoption (pilot → instrumentation → scale), with clear ROI and impact measurement.
Glossary
- AUROC: Area Under the Receiver Operating Characteristic curve; a performance metric summarizing binary classification across thresholds. "provide scores for the likelihood that they were AI generated, and report high discriminant performance (0.95 AUROC)."
- AUPRC: Area Under the Precision-Recall Curve; measures classifier performance in imbalanced settings focusing on precision and recall. "On News, the model achieves an AUPRC of 0.52 (prevalence is 0.25), while on MS MARCO it reaches 0.55 (prevalence is 0.27)."
- Binoculars: A method for detecting AI-generated text by scoring likelihood of machine authorship. "DetectGPT \citep{mitchell2023detectgpt} and Binoculars \citep{hans2024binoculars} provide scores for the likelihood that they were AI generated, and report high discriminant performance (0.95 AUROC)."
- BLEU: A reference-based metric that measures overlap between generated and reference text using n-grams. "Text quality has typically been measured using simple surface-level metrics like BLEU \citep{papineni2002bleu} and ROUGE \citep{lin2004rouge}, which can be effective when reference outputs are available..."
- Bonferroni correction: A multiple-comparisons adjustment that tightens significance thresholds to control family-wise error. "Features with adjusted (after Bonferroni correction) are considered statistically significant predictors of whether annotators label texts as ``slop.''"
- Cohen’s κ: A chance-corrected statistic for inter-rater agreement on categorical labels. "Annotator responses had a Cohen's of -0.15 (A1--A2), 0.29 (A1--A3), and 0.06 (A2--A3), indicating poor to fair agreement."
- Compression Ratios: An automatic repetition metric that quantifies redundancy by how well text can be compressed. "Compression Ratios \citep{shaib2024standardizing}"
- DetectGPT: A zero-shot detector that leverages probability curvature to discern machine-generated text. "DetectGPT \citep{mitchell2023detectgpt} and Binoculars \citep{hans2024binoculars} provide scores for the likelihood that they were AI generated, and report high discriminant performance (0.95 AUROC)."
- Flesch-Kincaid Grade Level: A readability metric estimating U.S. school grade level required to comprehend text. "measured by Gunning-Fog Index \citep{gunning1952technique} and Flesch-Kincaid Grade Level \citep{kincaid1975derivation}."
- Fleiss κ: A generalization of Cohen’s κ for assessing agreement among more than two raters. "We report both Cohen's (for pairwise), Fleiss (for three-way) and Gwet's AC..."
- Gunning-Fog Index: A readability metric estimating years of formal education needed to understand a passage. "measured by Gunning-Fog Index \citep{gunning1952technique} and Flesch-Kincaid Grade Level \citep{kincaid1975derivation}."
- Gwet’s AC1: An inter-rater reliability coefficient less sensitive to prevalence and marginal probabilities than κ. "By contrast, Gwet's AC yields pairwise scores of 0.12 (A1--A2), 0.42 (A1--A3), and 0.28 (A2--A3), indicating fair to moderate agreement when correcting for prevalence."
- In-context examples: Few-shot prompting technique where labeled examples are placed in the prompt to guide an LLM’s behavior. "and with in-context examples ()."
- Krippendorff’s α_MASI: A chance-corrected agreement metric for set-valued annotations using the MASI distance. "Following \citet{marchal2022establishing}, we calculate Krippendorf's $\alpha_{\text{MASI}$ which measures set agreement chanceâcorrected for partial overlaps."
- L2 regularization: A penalty on the squared magnitude of model parameters to reduce overfitting and multicollinearity. "To address this and handle class imbalance, we use 2 regularization with and class weighting."
- LLMs-as-judges: The practice of using LLMs to evaluate or score text quality or preferences. "Neither LLMs-as-judges nor linear models are able to fully approximate human assessments of ``slop,''..."
- Multicollinearity: High correlation among predictor variables that destabilizes regression estimates. "which can lead to multicollinearity issues in regression models."
- Part-of-Speech (PoS) tags: Linguistic labels (e.g., noun, verb) assigned to words indicating their syntactic role. "\citet{shaib-etal-2024-detection} found that modern LLMs are prone to repeatedly generate favoured syntactic templates, i.e., sequences of Part-of-Speech (PoS) tags."
- Propositional idea density: A measure of how many distinct ideas or propositions are expressed per unit length. "measured through information-theoretic token entropy \citep{meister2021revisiting} and propositional idea density \citep{brown2008automatic}."
- Retrieval-Augmented QA: A question answering paradigm that augments generation with retrieved passages from external sources. "Retrieval-Augmented QA."
- Reward model (Writing Quality Reward Model): A learned evaluator that scores text quality to guide generation or selection. "We use the Writing Quality Reward Model (WQRM; \citealt{chakrabarty2025ai}) to assign quality scores to our data."
- ROUGE: A reference-based metric focusing on n-gram overlap, widely used in summarization evaluation. "Text quality has typically been measured using simple surface-level metrics like BLEU \citep{papineni2002bleu} and ROUGE \citep{lin2004rouge}..."
- Span-level precision: An agreement metric evaluating overlap between annotated text spans rather than whole-document labels. "We use the span-level precision measure described in \citet{chakrabarty2025can} to assess if annotators highlighted similar text."
- Subjectivity-Lexicon: A lexicon-based method to estimate subjectivity by counting subjective terms. "Subjectivity-Lexicon \citep{10.1162/0891201041850885}"
- Surprisal: An information-theoretic measure of unexpectedness for tokens, often used to quantify information density. "Surprisal \citep{meister2021revisiting}"
- Sycophancy: A failure mode where models flatter or agree excessively, often misleading reward models. "show that reward models over-weight 5 superficial writing cues including length, structure, jargon, sycophancy, and vagueness."
- Templatedness: The degree to which text follows repeated syntactic or rhetorical templates. "Templatedness, measured via syntactic structures \citep{shaib-etal-2024-detection}"
- Templates-per-Token: A metric quantifying the prevalence of repeated syntactic templates normalized by length. "Templates-per-Token \citep{shaib-etal-2024-detection}"
- Token entropy: Information-theoretic measure of uncertainty per token; used to assess information density. "measured through information-theoretic token entropy \citep{meister2021revisiting}"
- Zero-shot: Prompting an LLM to perform a task without example demonstrations. "This is usually done zero-shot, providing instructions for evaluation."
Collections
Sign up for free to add this paper to one or more collections.