- The paper investigates the convergence of representation embeddings from varied foundation models in astronomy using the mutual k-nearest neighbor (MKNN) metric.
- It employs diverse architectures like ViT, DINOv2, and AstroPT to show that larger model sizes yield improved intra- and crossmodal alignment in astronomical data.
- The study suggests that leveraging pre-trained, domain-agnostic models can enable resource-efficient approaches for developing astronomy-specific foundation models.
The Platonic Universe: Do Foundation Models See the Same Sky?
Introduction
The paper "The Platonic Universe: Do Foundation Models See the Same Sky?" (2509.19453) presents an investigation into the Platonic Representation Hypothesis (PRH) within the field of astronomy. Utilizing observations from JWST, HSC, Legacy Survey, and DESI, the researchers evaluate the convergence of representational embeddings produced by a variety of foundation models developed through differing architectures and training paradigms. This study endeavors to determine whether these models, despite divergent backgrounds, yield similar representations upon being trained on extensive datasets, effectively supporting the notion that foundation models for astronomy can rely on pre-trained architectures from broader machine learning efforts.
The Conceptual Framework: Platonic Representation Hypothesis
The PRH posits that neural networks, irrespective of their unique architectures and training objectives, eventually converge on a shared statistical framework of reality. It suggests that progressively larger models trained on diverse tasks generate embeddings that reflect a collective understanding of the universe's underlying structures. The PRH draws from Plato’s "Allegory of the Cave," wherein observed shadows symbolize distorted reflections of reality. Foundation models, through extensive training, learn to reconstruct these shadowy data into comprehensive Forms of reality. The convergence is propelled by task generality, model capacity, and simplicity bias.
Methodology
The authors employ a selection of distinct neural architectures including ViT, ConvNeXtv2, DINOv2, IJEPA, AstroPT, and Specformer. These architectures represent a cross-section of supervised, self-supervised, autoregressive, and astronomy-specific models. The study utilizes data from crossmatched astronomical surveys, facilitating the evaluation of embedding similarity via the mutual k-nearest neighbor (MKNN) metric—a measure of representational alignment. This analysis spans both intramodal comparisons (within a single modality but varying model sizes) and crossmodal comparisons (different modalities at comparable model sizes).
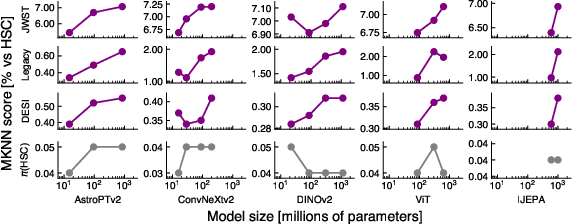
Figure 1: Model size vs crossmodal embedding alignment for our tested models. Each of our modality embeddings are compared to crossmatched embeddings from a paired HSC image dataset.
Key Findings
The paper provides compelling evidence for the PRH, with substantial numerical results indicating a correlation between model size and representational alignment, both intra and cross-modally. Specifically, intramodal MKNN scores consistently increase for larger models across a majority of the comparisons analyzed. For instance, JWST pairs exhibit improved alignment from 49.7% to 56.2% between different model sizes. Crossmodal results echo these findings, with MKNN scores manifesting significant increases across a broad array of trials and yielding robust statistical validation of the PRH's predictions.
Implications and Future Work
The demonstrated convergence of representations has profound implications for the development of astronomical foundation models. The study suggests a strategic pivot towards leveraging pre-trained models from non-specialized architectural bases, which already encapsulate extensive computational investments. This perspective could usher in resource-efficient model training approaches by simply augmenting pre-trained models for domain-specific applications. Future explorations are recommended to encompass more comprehensive datasets and investigate alternative representational similarity metrics, beyond MKNN—a move that will potentially uncover finer granularity into the nature of embedding alignments.
Conclusion
The evidence presented in the paper underscores the viability of the PRH within astronomical contexts, advocating for a paradigm where scaled models comprehensively capture universal patterns transcending their specific training regimes. It indicates a promising trajectory where domain-agnostic foundation models may be tailored effectively to astronomy-specific explorations, facilitating efficient utilization of computational resources while reaffirming the convergence towards a shared Platonic representation space. Such advancements hold promise for the future direction of AI and machine learning applications in astronomy, suggesting continued focus on scalable architectures and diverse datasets.
